En esta entrada vamos a entender en qué consiste Databricks. Cómo nos puede ayudar esta solución cloud en nuestras necesidades de procesamiento y analítica Big Data y cuáles son sus particularidades para poder tomar decisiones con criterio.

Contenidos
¿Qué es Databricks?
Databricks es el nombre de la plataforma analítica de datos basada en Apache Spark desarrollada por la compañía con el mismo nombre. La empresa se fundó en 2013 con los creadores y los desarrolladores principales de Spark. Permite hacer analítica Big Data e inteligencia artificial con Spark de una forma sencilla y colaborativa.
Esta plataforma está disponible como servicio cloud en Microsoft Azure y Amazon Web Services (AWS).
Databricks contiene muchas funcionalidades que la hacen una solución analítica bastante completa. Aun así, depende de servicios adicionales como almacenamientos externos de datos para poder convertirse en la pieza central de un sistema analítico empresarial completo como Data Warehouse o Data Lake.
Es una plataforma que permite múltiples casos de uso como procesamiento batch, streaming y machine learning.
Características de Databricks
Permite auto-escalar y dimensionar entornos de Apache Spark de forma sencilla en función de las necesidades. También es posible terminar automáticamente estos clústers. De esta forma, se facilitan los despliegues y se acelera la instalación y configuración de los entornos. Con la opción serverless se puede abstraer toda la complejidad alrededor de la infraestructura y obtener directamente acceso al servicio. Así se facilita su uso por equipos independientes que necesiten recursos volátiles y despliegues ad-hoc.

Incluye proyectos colaborativos y espacios de trabajo interactivos llamados notebooks. Estos pueden servir para desarrollar procesos y prototipos de transformación y análisis y más adelante ponerlos en producción con el planificador. Están integrados con sistemas de control de versiones como Github y Bitbucket y es posible crear directorios separados para diferentes unidades o equipos.
Un clúster de Databricks tiene dos modos: Estándar y Alta Concurrencia. El clúster de alta concurrencia (High Concurrency) soporta los lenguajes de programación Python, R y SQL mientras que el clúster Estándar (Standard) soporta los lenguajes Scala, Java, Python, R y SQL. También se complementan con librerías y frameworks como Tensorflow, PyTorch, GraphX, Keras y scikit-learn.
Soporta cifrados de datos con la última versión de TLS y se integra con los servicios AWS KMS (Key Management System) y Azure Key Vault. En cuanto a su seguridad, es compatible con Azure Active Directory para definir políticas de acceso, también se pueden definir los roles y SLAs.
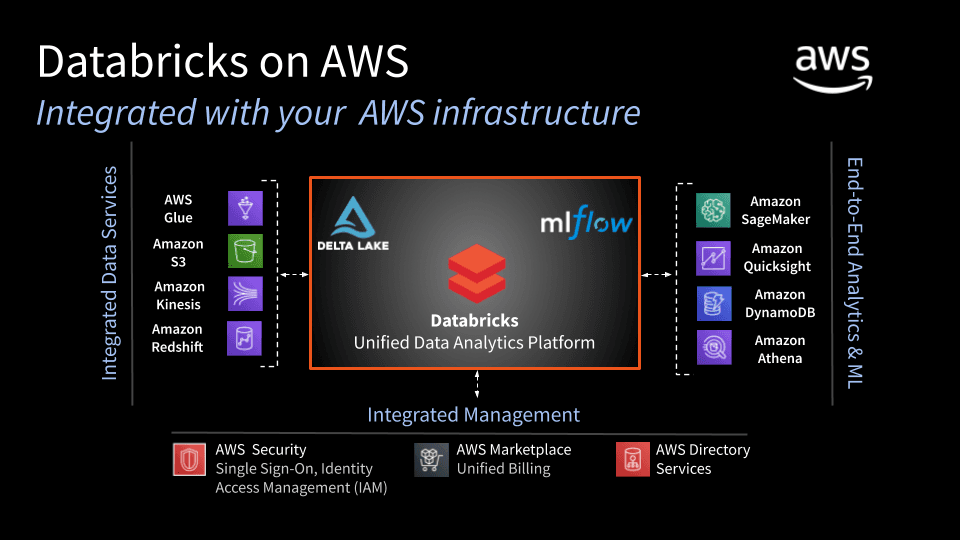
Además, la plataforma puede realizar backups periódicos automáticos de los sistemas y sus metadatos para evitar la pérdida de información. También genera alertas y capacidad de monitorización de los procesos, generando reintentos cuando sea necesario.
¿Cómo usar Databricks?
Databricks no es responsable de la capa de persistencia de los datos. Esto quiere decir que los datos se procesan con Spark pero antes deben estar almacenados en algún componente adicional. Algunos ejemplos de estos componentes son Azure Blob Storage, Amazon S3, ADLS (Azure Data Lake Storage), Azure SQL Data Warehouse o herramientas compatibles con JDBC y ODBC.
Al evaluar Databricks como una solución Cloud, debemos prestar atención también al resto de servicios con los que se integra de forma nativa y para los que se optimiza la operativa. Tanto en AWS como en Azure existen integraciones con servicios de ingesta de datos como Azure Data Factory, de almacenamiento y de visualización de datos como Power BI.
Es importante tener en cuenta herramientas como Azure Data Factory (ADF) en Azure, ya que estas pipelines de datos nos pueden ayudar a configurar y a invocar los trabajos de Databricks mediante variables. Además, de esta forma también podremos establecer dependencias entre notebooks fácilmente y nos ayudará en las tareas de debug.
¿Quieres Convertirte en Ingeniero de Datos?
Nos permite ejecutar trabajos Spark de tres formas: mediante Notebook, mediante su JAR y mediante spark-submit.
El sistema está preparado para trabajar a través de la interfaz web, desde la que se pueden ejecutar y monitorizar trabajos. Además, existe una herramienta de línea de comandos: Databricks CLI. Esta utilidad se conecta a la API REST de Databricks y, una vez autenticada, puede ejecutar ciertos comandos.
Leer: Cómo Optimizar Clústers en Databricks
Databricks Free (Antes Databricks Community)
Databricks Free (Antes Databricks Community) es la versión de Databricks gratuita. Permite usar un pequeño clúster con recursos limitados y notebooks no colaborativos. La versión de pago no tiene estas limitaciones y aumenta las capacidades.

Una vez hemos hecho login en la plataforma, nos permitirá hacer un tutorial rápido que nos explica la funcionalidad básica:
- Crear un clúster de Spark
- Asociar notebooks al clúster y ejecutar comandos
- Crear tablas de datos
- Hacer consultas y visualizar los datos
- Manipular y transformar los datos
El primer paso es crear un nuevo clúster. Esto se puede hacer desde la pestaña clusters. Nos permite elegir el nombre y la versión del runtime. En este caso elegimos 6.5: Con Scala 2.11 y Spark 2.4.5. La versión Free crea un clúster con un driver de 15GB de RAM.
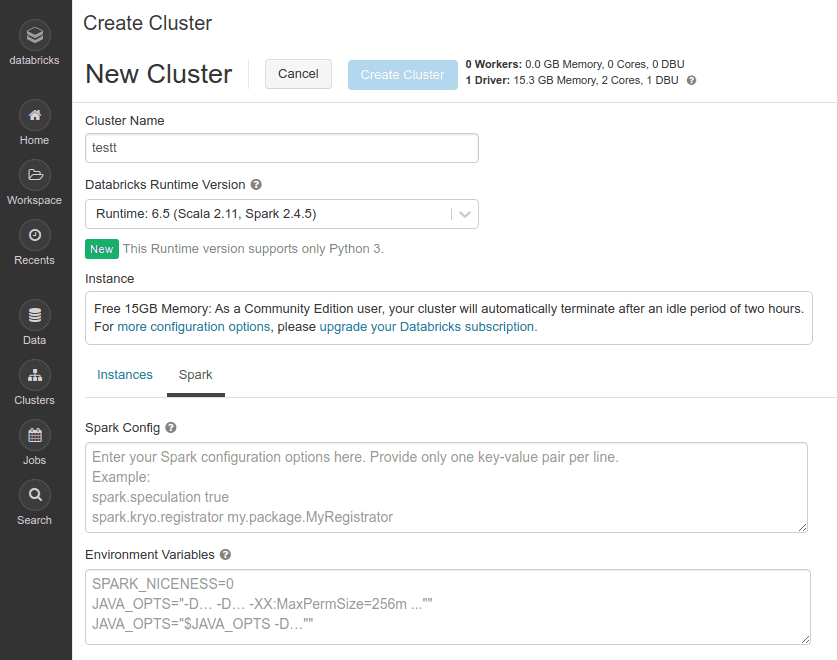
Además, es posible configurar desde aquí las variables de entorno y la configuración específica de Spark. Una vez que hemos creado el clúster, para poder usarlo debemos desplegarlo y esperar a que se encuentre en el estado «Running».
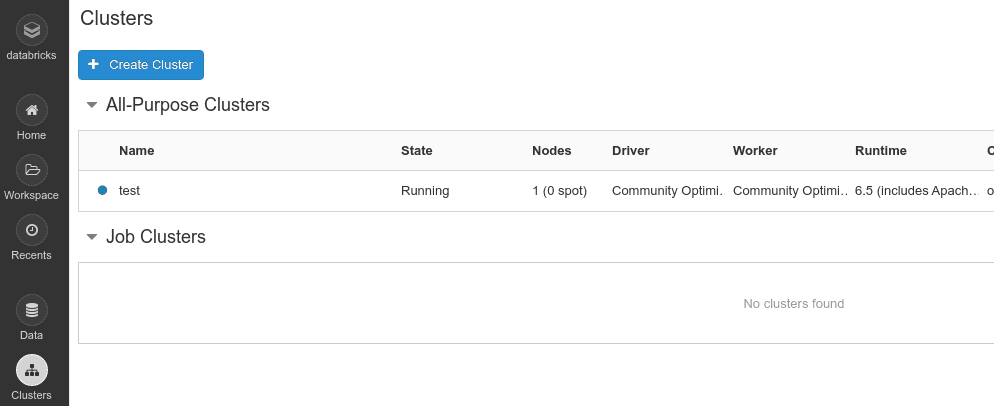
Con Databricks Free no podemos ejecutar jobs de Spark desde ficheros JAR, solamente desde notebooks. Es posible integrar los notebooks con el sistema de control de versiones Git en Github o Bitbucket.

Cuando creamos y accedemos a un notebook, podemos escribir consultas, visualizar datos y realizar transformaciones. Para ejecutar cada bloque existe un icono a su derecha, pero previamente debemos asociar el notebook a un clúster en ejecución.
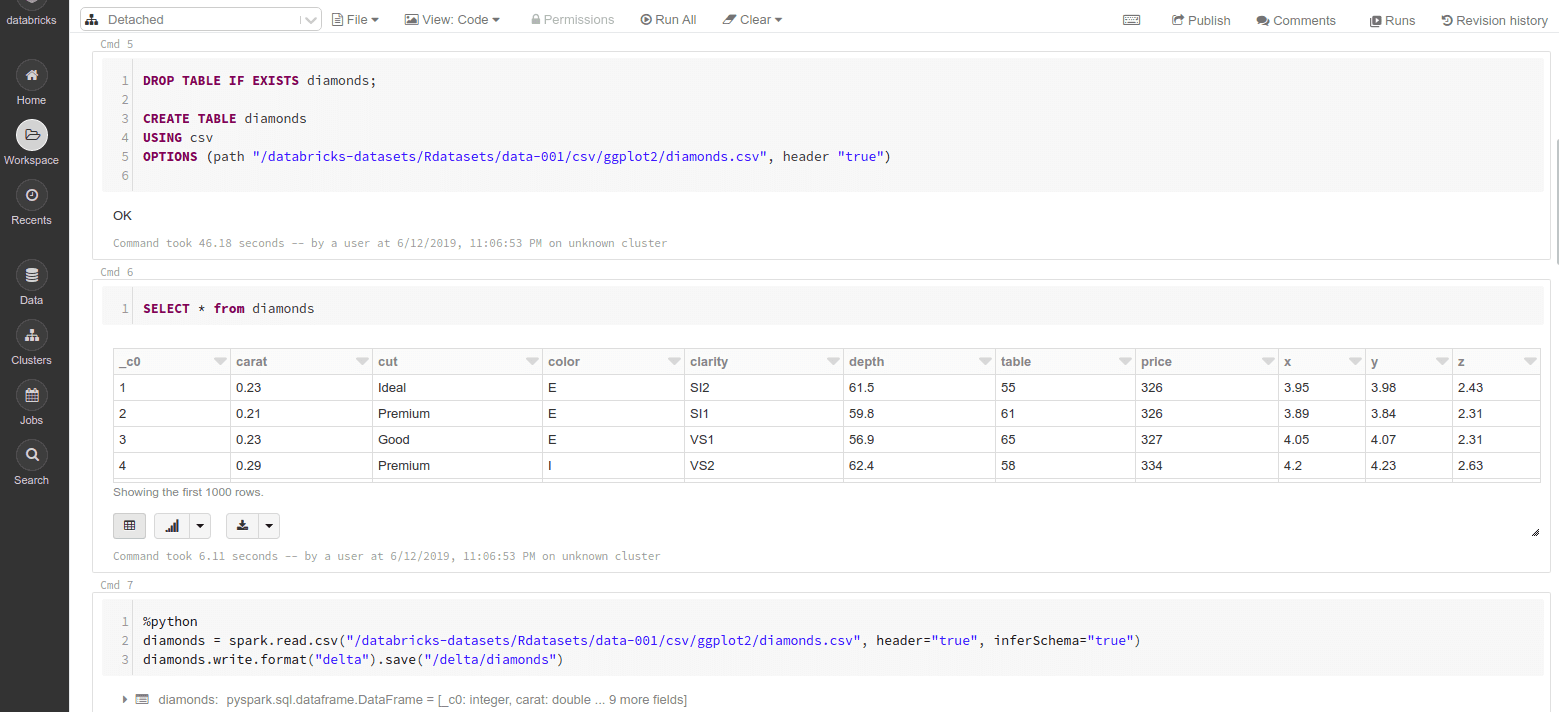
También integra varias herramientas de logging y de monitorización. Entre ellas se encuentra la Spark UI, a la que accedemos desde dentro de una pestaña en el clúster que hemos desplegado. Aquí tenemos el detalle de los trabajos que hemos ejecutado en el clúster de Spark desde el notebook.

Databricks SQL
Databricks SQL es una herramienta que nos permite realizar análisis de datos y operar nuestra arquitectura de Data Warehouse sobre el ecosistema de Databricks. Esta herramienta es accesible desde la interfaz web de Databricks y proporciona un editor de SQL nativo para consultar datos en nuestro Data Lake y Data Warehouse o Data Lakehouse.
Delta Lake
proporciona capacidades adicionales sobre el formato de datos Parquet. Entre estas capacidades se encuentra el soporte a las propiedades ACID, posibilitando transacciones sobre nuestro data lake. También es posible recuperar una versión anterior de un dato o de una tabla (time travel), por lo que resulta muy útil para garantizar el cumplimiento de determinadas regulaciones.
Alternativa en Azure: HDInsight
HDInsight es el servicio para analítica Big Data de Microsoft Azure con el que se pueden desplegar clústers de servicios Big Data como Hadoop, Apache Spark, Apache Hive, Apache Kafka, etc.
En HDInsight existen varios tipos de clúster predefinidos con los componentes que cubren los casos de uso más habituales como Streaming, Data Warehouse o Machine Learning.
HDInsight está integrado con otros servicios del catálogo de Microsoft Azure, y es compatible con otras soluciones como Databricks. HDInsight podría cubrir la capa de almacenamiento persistente que necesita Databricks para formar una solución Big Data completa.
Te recomiendo leer el artículo acerca de HDInsight para conocer las diferencias más destacadas.
También, puedes conocer la alternativa en AWS: Amazon EMR.
Siguientes Pasos, Formación y Curso
Aquí tienes mi propio curso para que aprendas de forma eficiente Databricks, para cualquier nivel:

Curso de Introducción a Databricks
Este curso te preparará para comprender y sacar todo el partido posible al ecosistema de Databricks.
Explorarás conceptos fundamentales como la arquitectura de Databricks, los tipos de clústeres, Delta Lake, Unity Catalog y la integración con Azure Data Lake Storage.
En las secciones prácticas, pondrás manos a la obra utilizando la interfaz gráfica, configurando clústeres, trabajando con notebooks, gestionando costes y securizando accesos
También, tienes este libro disponible en Amazon: Beginning Apache Spark Using Azure Databricks
Puedes aprender más de este ecosistema en el blog de Databricks.
Preguntas Frecuentes – FAQ
¿Para qué se usa Databricks?
Databricks es una herramienta cloud usada para procesar y realizar transformaciones sobre Big Data. También permite explorar estos datos usando modelos de inteligencia artificial. Está basada en Apache Spark.
¿Databricks es gratuito?
Existe una versión gratuita llamada Databricks Free (Antes Databricks Community) que permite usar un pequeño clúster y notebooks con capacidad limitada. La versión de pago aumenta estas capacidades.
¿Qué es un notebook en Databricks?
Un notebook es una herramienta web que presenta un documento colaborativo sobre el que escribir código ejecutable y presentar visualizaciones de datos. Es la herramienta principal de trabajo en Databricks.
¿Qué lenguaje es recomendado para los trabajos de Spark en Databricks?
Para el clúster estándar de Databricks, Scala es el lenguaje recomendado para desarrollar trabajos de Spark. Apache Spark está desarrollado en Scala y es el núcleo de Databricks, aportando mejor rendimiento que Python y que SQL.

Arquitecto de Datos con más de 10 años de experiencia en el sector del Big Data. Autor de cursos de formación en tecnologías Big Data, Cloud y Streaming completados por más de 7000 alumnos en Udemy y otras plataformas. Miembro de la Apache Software Foundation desde 2019.



Hola, como puedo contratar Databricks en Mexico, conoces algun asesor, que pueda contactar?