¿Quieres aprender qué es el Stream Processing? ¿Cuándo debes usarlo? Explora en este artículo las tecnologías open source más populares de stream processing y una comparativa analizando sus características, ventajas y desventajas.

Contenidos
¿Qué es el Stream Processing?
El stream processing está basado en la idea de procesar los datos de forma continua. En cuanto estos datos están disponibles se procesan de manera secuencial. Para ello, se usan flujos de datos infinitos y sin límites de tiempo. La manera tradicional de procesar los datos ha sido en batches, agrupados en grandes lotes, esta técnica se llama batch processing.
Actualmente, los servicios en tiempo real que usan estos mecanismos de stream processing cada vez tienen más demanda. A través de estas técnicas es posible acelerar la velocidad a la que se obtiene valor de los datos y generar acciones para interaccionar con los clientes con poca latencia.

Generalmente, las latencias que se consideran al hablar de los sistemas de tiempo real o de stream processing son del orden de 10 milisegundos a 1 segundo. En función del caso de uso o el ámbito de su aplicación, estas latencias pueden reducirse, aunque supondrán importantes desafíos.
Los requisitos más importantes a tener en cuenta a la hora de implementar una solución analítica en streaming son los siguientes:
- Cantidad de datos que se deben procesar de forma simultánea (picos de carga)
- Latencias extremo a extremo (end to end)
- Garantías de entrega de mensajes que debe asegurar la solución
Casos de uso de Streaming
Las fuentes de datos para casos de uso de stream processing pueden estar presentes en cualquier sector, a continuación tienes listados los más populares:
- Monitorización de sistemas, de redes y de aplicaciones
- Dispositivos Internet of Things (IoT)
- Sistemas de recomendación y optimización de resultados
- Transacciones financieras, detección de fraude y trading
- Seguimiento de usuarios en páginas web y comercio electrónico
- Notificaciones en dispositivos y aplicaciones móviles en tiempo real
Los procesos y flujos de trabajo con datos en streaming más usados son los filtros, la agregación y el enriquecimiento de datos. Los filtros permiten reducir la cantidad de información antes de almacenarla. La agregación consiste en calcular agregados de datos en ventanas temporales y también reducen la cantidad de información persistida.
Por último, el enriquecimiento consiste en agregar información a un dataset en tiempo real. Esto ofrece ventajas respecto a enriquecerla cuando ya se encuentra persistida en un almacenamiento, y es que permite tomar decisiones más rápido con los datos.
Conceptos Básicos en Stream Processing
A continuación vamos a desarrollar algunos conceptos y términos básicos que se han generado alrededor de las tecnologías de stream processing.
Los sistemas de streaming distribuidos tienen tres maneras de gestionar las garantías de entrega de los mensajes en sus protocolos:
- At-least-once: Garantiza que el mensaje siempre se entregará. Es posible que en caso de fallo se entregue varias veces, pero no se perderá ningún mensaje en el sistema.
- At-most-once: Garantiza que el mensaje se entregará una vez o no se entregará. Un mensaje nunca se entregará más de una vez.
- Exactly-once: Garantiza que todos los mensajes se van a entregar exactamente una vez, realizando el sistema las comprobaciones necesarias para que esto suceda.
Existen numerosas aplicaciones que no se pueden permitir la existencia mensajes duplicados o perdidos debido a fallos en la comunicación o en las aplicaciones. Por esta razón es tan importante que existan sistemas que garanticen la entrega exactamente una vez como Apache Kafka o Flink.
Tupla o evento: conjunto de elementos o de tipos de datos simples guardados de forma consecutiva. También, los podemos llamar eventos o mensajes. Los eventos representan un cambio de estado en el sistema y normalmente tienen un orden basado en el tiempo.

Flujo de datos: También llamado stream o stream de eventos. Se trata de una secuencia infinita de tuplas o de eventos en la que el orden importa. Este flujo de datos viaja desde los productores hacia los consumidores de datos.
Definiciones
Ventanas de procesamiento: Dividen los datos de entrada en partes finitas. Permiten tratar las secuencias infinitas con unos recursos limitados como la memoria del sistema. Pueden estar basadas en tiempo o en el número de elementos y se pueden desplazar a medida que se procesa su contenido. Existen varios tipos de ventanas dependiendo de las características del sistema.
Operaciones con y sin estado: Las operaciones sin estado permiten obtener un resultado por cada uno de los eventos procesados. Las operaciones con estado operan sobre un conjunto de elementos para generar una salida.
Para mantener la tolerancia a fallos, los sistemas de streaming usan checkpointing y no eliminan los eventos del sistema una vez procesados. De esta manera, almacenan de forma persistente el estado del sistema en instantes de tiempo y el punto en el que se encuentran para poder recuperar la información en el caso de que ocurra algún fallo de red o en los propios nodos.
Backpressure: Es el mecanismo que indica a la tecnología que los consumidores no pueden procesar más eventos en un instante concreto. Evita que el sistema se sature cuando se publican eventos a más velocidad que la que se consumen. Normalmente, se implementa un mecanismo de buffering. Si se excede su capacidad, se pueden eliminar los eventos con una política definida de tipo LIFO, FIFO, etc. La capacidad de escalar junto a un buen mecanismo de backpressure son esenciales para garantizar la alta disponibilidad y el rendimiento del sistema.
Ventajas del Streaming de Eventos
Entre las ventajas principales se encuentra el desacoplamiento. Por ejemplo, en una arquitectura editor-suscriptor, no es necesario que estos dos componentes se conozcan entre sí. Además, puede existir un intermediario que gestione las colas de mensajes.
Este desacoplamiento de los componentes genera también una independencia en los equipos de desarrollo. Los equipos no necesitan una gran coordinación para trabajar en cada uno de los extremos. También, las tecnologías de streaming nos facilitan implementar una arquitectura de microservicios, con un broker de streaming como mecanismo central de comunicación.
Otra de las razones es la capacidad de los sistemas de streaming de eventos de proporcionar herramientas analíticas en tiempo real. De esta forma, los usuarios y clientes podrán reaccionar a determinados tipos de eventos de una manera más ágil y continua en el tiempo.
Tecnologías de Stream Processing
En la actualidad existen varias tecnologías y frameworks open source de stream processing, todas ellas son de reciente creación, desarrolladas en los últimos años.
Se ha dejado fuera de esta lista a Apache Storm debido a que otras tecnologías han tomado la delantera en cuanto a capacidades y el proyecto está en desuso. Tampoco se ha querido añadir tecnologías puramente cloud como Azure Event Hubs o Amazon Kinesis.
A continuación, se comentan los aspectos más importantes de las más populares:
| SPARK STREAMING | KAFKA STREAMS | FLINK | |
|---|---|---|---|
| Despliegue | Standalone, Yarn, Mesos | Librería (API Java) | Standalone, Yarn, Mesos, Kubernetes |
| Garantías | Exactly once | Exactly once | Exactly once |
| Conectores | Múltiples | Dependiente de conectores de Kafka | Múltiples |
| Gestión de estado | No | Si (RocksDB) | Si (RocksDB) |
| Abstracciones | Tablas, SQL, ML | Tablas, SQL (KSQL) | Tablas, SQL, CEP, ML |
| Retraso de eventos | Si | Si | Si |
| Modelo | Micro-batch | Streaming de eventos individuales | Streaming de eventos individuales |
| Batch | Si | No | Si |
| Comunidad | Gran comunidad, aunque más pequeña en streaming | Más reciente, en crecimiento | Más pequeña pero en rápido crecimiento |
| Casos de uso | Streams ETL | Microservicios, dentro de otras aplicaciones | Todos |
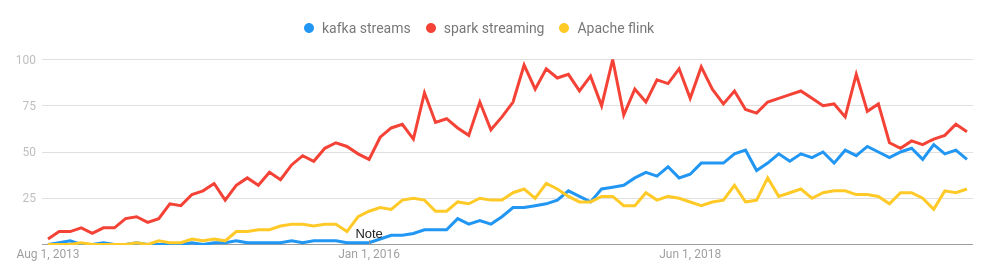
En la siguiente gráfica podemos ver la tendencia desde el año 2013 en las búsquedas de Google de las tres tecnologías de streaming más populares.
Kafka Streams
Kafka Streams es una librería (API) muy popular que permite construir aplicaciones de procesamiento de flujos de datos usando Apache Kafka como sistema de almacenamiento de entrada y de salida de datos. La versión inicial se publicó en enero del 2011.
Aunque Kafka Streams depende de Apache Kafka puede conectarse a sistemas externos y numerosas tecnologías para construir flujos de datos en tiempo real desacoplando aplicaciones y facilitando la implementación de microservicios.
Ventajas
- No necesita un clúster dedicado (usa Kafka)
- APIs de consumidores y productores de mensajes
- Reprocesamiento sencillo de mensajes
- Desacoplamiento de aplicaciones, muy usado en microservicios
- Puede usarse como base de datos
- Procesamiento de eventos individuales, streams nativos
- Garantías de entrega exactly-once
Desventajas
- Acoplado con Apache Kafka
- No tiene mucha adopción para cargas de trabajo pesadas
Spark Streaming
Spark Streaming extiende la funcionalidad de Apache Spark para realizar stream processing. Para ello, agrupa los datos recibidos en pequeños micro-batches e incluye operadores con y sin estado. La versión inicial se publicó en mayo de 2014.
Ventajas
- Facilidad de uso: APIs de alto nivel conocidas y bien mantenidas en la comunidad, con gran cantidad de documentación
- Librerías extensas para grafos y machine learning
- Lenguajes de programación Scala, Java y Python
- Incluye una CLI (Interfaz de línea de comandos) en Scala y Python
- Checkpointing sencillo gracias a micro-batches
- Mayor throughput debido a la gestión en micro-batches
- Soporta una arquitectura lambda
- Garantías de entrega exactly-once
Desventajas
- Mayores latencias de procesamiento a causa de micro-batches
- Parametrización compleja y ajustes manuales
- Solo soporta ventanas basadas en tiempo
Apache Flink
Apache Flink es una plataforma distribuida de stream processing con alta disponibilidad y escalabilidad. Aunque puede realizar procesamiento batch y streaming, ha sido diseñado con una arquitectura orientada al procesamiento de eventos en streaming individuales. La versión inicial se publicó en mayo del 2011.
Ventajas
- Procesamiento de eventos individuales, streams nativos
- Velocidad, baja latencia y throughput configurables
- Ventanas de procesamiento personalizadas basadas en eventos o en tiempo
- Garantías de entrega exactly-once
Desventajas
- Comunidad más pequeña pero en crecimiento
- La adopción para procesamiento batch es baja
Conclusiones
Para elegir un buen sistema de procesamiento en streaming debemos tener muy en cuenta el caso de uso y sus particularidades. Kafka Streams es el sistema más ligero, que puede soportar fácilmente aplicaciones sencillas. Por otro lado, para desarrollar aplicaciones más complejas y pesadas, Flink o Spark son una mejor opción.
Además del caso de uso actual, también debemos considerar la extensión de éstos en el futuro y las nuevas aplicaciones que desarrollemos, de forma que podamos reutilizar el mismo sistema. En el caso de Kafka, si tenemos un clúster de Kafka ya desplegado para otro propósito, debemos estudiar si merece la pena ampliar su uso con Kafka Streams o bien desplegar un nuevo clúster de Flink.
En la actualidad, Apache Flink es un sistema más flexible que Apache Spark. También puede suponer menores latencias y procesamientos más rápidos debido a su arquitectura. Sin embargo, el campo del stream processing avanza muy rápido, y es posible que las tecnologías evolucionen o surjan alternativas interesantes. Debemos conocer estas opciones para ser capaces de tomar la mejor decisión.
Como resumen:
Cuando ya estás usando Apache Spark en tu organización, no necesitas baja latencia, quieres unificar procesos batch y stream y deseas un alto throughput la mejor opción es Spark Streaming.
En el caso de que solo necesites microservicios y Kafka con baja latencia, usa Kafka Streams.
Si necesitas un sistema flexible, con baja latencia y características de procesamiento en streaming avanzado decídete por desplegar Flink.
Formación: Libros y Cursos
Para aprender más sobre estas tecnologías, no dudes en invertir en tu formación. A continuación te presento mis cursos y libros recomendados:

Apache Flink desde cero: La guía Esencial
Flink es una de las tecnologías de streaming más potentes que existen. Con mi curso aprenderás a desarrollar aplicaciones de procesamiento en tiempo real desde cero.

Comienza con Kafka: Curso de Apache Kafka desde cero
Con mi curso de Apache Kafka, aprenderás esta herramienta de streaming desde cero, su arquitectura, APIs y todas sus posibilidades.
Mejores libros de procesamiento en streaming:
- Kafka: La Guía Definitiva
- Kafka Streams – Procesamiento en Streaming en Tiempo Real
- Arquitectura de procesamiento en streaming
- Spark: La Guía Definitiva: Procesamiento Big data simple
- Aprendiendo Spark: Análisis de Big Data ultrarápido
- Procesamiento en Streaming con Apache Flink
Preguntas Frecuentes Stream Processing – FAQ
¿Cuál es la diferencia entre batch y stream processing?
El procesamiento Batch está orientado a procesar agrupaciones grandes de datos con un tamaño finito y determinado. Es la manera típica de procesar grandes cantidades de datos con unos recursos limitados. El procesamiento streaming maneja registros individuales o micro batches con flujos de datos infinitos.
¿Qué es procesamiento en tiempo real?
El procesamiento en tiempo real proporciona resultados a medida que entran eventos en el sistema. Para ello, realiza las operaciones en el momento.
¿Es Flink más rápido que Spark Streaming?
Apache Flink puede procesar datos más rápido que Spark Streaming debido a su arquitectura orientada a eventos. En el caso de Spark Streaming se procesan micro-batches, lo que aumenta las latencias y el posible throughput.

Arquitecto de Datos con más de 10 años de experiencia en el sector del Big Data. Autor de cursos de formación en tecnologías Big Data, Cloud y Streaming completados por más de 7000 alumnos en Udemy y otras plataformas. Miembro de la Apache Software Foundation desde 2019.


