Aprende los aspectos clave del sistema de mensajería para Big Data. En este artículo encontrarás una introducción a Apache Kafka y a algunos de sus componentes básicos y arquitectura. De esta forma, podrás familiarizarte con sus particularidades.

Contenidos
¿Qué es Apache Kafka?
Apache Kafka originalmente consistía en un sistema de intermediación de mensajes basado en el modelo publicador/subscriptor en el que varios productores y subscriptores pueden leer y escribir. Con el tiempo y la evolución del producto se ha convertido en toda una plataforma de streaming de eventos distribuida y el estándar de facto para streaming. Además también podemos considerarla una herramienta complementaria a las bases de datos, proporcionando garantías ACID.
Apache Kafka surgió en la empresa LinkedIn como una cola de mensajería para interconectar varios sistemas de forma escalable. En el año 2011 el proyecto entró en la incubadora de la Apache Software Foundation, en la que se graduó como top-level project en el año 2012. Apache Kafka está escrito en Java y Scala. Es de código abierto (open source), y se distribuye con licencia Apache 2.0. En la actualidad, cuenta con más de 700 contribuidores y más de 40 committers.
Kafka proporciona la plataforma para publicar y suscribirse a flujos de eventos y permite almacenar estos eventos de una forma tolerante a fallos, escalable, persistente y con capacidad de replicación.
Además de almacenar estos eventos, la funcionalidad se extiende con la capacidad de procesarlos en tiempo real, a medida que se reciben de múltiples fuentes de datos. Kafka se integra con numerosas tecnologías, de esta forma, permite construir flujos de datos en tiempo real entre distintos sistemas y aplicaciones de manera desacoplada.
Por estas razones, Apache Kafka es muy popular en la arquitectura Big Data de muchas empresas en la actualidad. Debido a su arquitectura, consigue obtener una baja latencia, escalabilidad horizontal y absorber los picos de carga que pueden ocurrir en el sistema.
Patrón Publish / Subscribe
El patrón publicador / subscriptor (también llamado productor / consumidor, editor / subscriptor o publish / subscribe) es un concepto que debemos tener en cuenta para entender cómo funciona Apache Kafka.
Este patrón se usa para comunicar aplicaciones a través de mensajes: es un sistema de eventos distribuidos en el que un suscriptor tiene interés por ciertos eventos.
El editor o publicador es el que genera los eventos, que más adelante se envían a los subscriptores interesados.
El subscriptor puede incorporar un filtro para consumir solo los mensajes que le interesen. Este suscriptor, por tanto, se suscribe a uno o varios tipos de mensajes, que más adelante denominaremos temas o topics.

Este modelo de mensajería es un paradigma asíncrono y desacoplado en el espacio ya que los editores y los subscriptores no se conocen entre sí (como ocurre en los modelos tradicionales de cliente-servidor).
En un modelo editor-subscriptor, puede existir un proceso intermediario como ocurre en Apache Kafka. Este intermediario aumenta el desacoplamiento, pero también puede ser un cuello de botella y un punto de fallo.
La solución es distribuir este proceso en una red de intermediarios (brokers) que proporciona la escalabilidad y la fiabilidad que necesitamos. Si un broker falla o se queda sin conectividad, otro broker puede tomar su lugar y gestionar las peticiones.
Componentes Básicos de Kafka
A continuación voy a explicar los componentes básicos de Apache Kafka.
Topics
Los Topics en Kafka son las categorías en las que se clasifican los mensajes. Así, podemos entender cada topic como si fuera un flujo de datos.
Particiones
Cada topic está dividido en particiones, que permiten a Kafka distribuir los datos en los nodos conectados (brokers). Es la unidad de paralelismo para dotar a Kafka de escalabilidad horizontal. A cada mensaje que se quiere escribir en un topic, se le asigna una clave de partición. En el caso de que no se le asigne ninguna clave de partición, ésta se calcula de forma aleatoria.
Cada partición tiene un offset asociado. El offset es un identificador incremental asignado a cada mensaje. Con este mecanismo, se puede identificar un mensaje con el nombre del topic que lo contiene, la partición y el offset.

También es interesante mencionar el concepto de compactación de logs en Kafka. Mediante este mecanismo, periódicamente podemos invalidar los registros con clave null y de esta forma limpiar la partición de datos innecesarios, quedándonos únicamente con el último registro para cada clave.
A menudo también se denominan los topics y particiones de Kafka como commit log o log de registro distribuido. Esta estructura de datos ordenados solo permiten anexar al final nuevos registros y además no permiten su eliminación o modificación una vez persistidos (inmutabilidad).
Debemos tener en cuenta que el rendimiento de Apache Kafka es constante respecto al tamaño de los datos persistidos en el disco.
Replicación
Una réplica en Kafka consiste en realizar una copia de una partición disponible en otro broker. Este mecanismo de replicación permite a Kafka ser tolerante a fallos y asegura que no hay pérdida de datos.
Cuando existen varias réplicas disponibles, una de ellas es elegida como líder, y el resto como seguidores. Las réplicas que siguen al líder y están sincronizadas se marcan como ISR (In Sync Replica). Para que un topic se encuentre en un estado sano, el valor de ISR debe ser igual al factor de replicación.
Productores
Se denominan productores a los clientes conectados a Kafka encargados de publicar mensajes en un broker. Son los responsables de serializar, particionar, comprimir y repartir la carga entre los brokers en función de las particiones.
La asignación de mensajes a topics puede realizarse con el método round-robin o con alguna función semántica que determine la partición. Debemos tenerlo en cuenta para intentar tener particiones balanceadas.

Los mensajes están compuestos por una clave, el valor y una marca de tiempo asignada. Se recomienda no almacenar mensajes de más de 1MB, que es el valor por defecto en la configuración.
La escritura por parte del productor incluye 5 pasos:
- Serialización
- Particionado
- Compresión
- Acumulación de registros
- Agrupación por broker y envío
Consumidores
Los consumidores de Kafka son los clientes conectados suscritos a los topics que consumen los mensajes. Cada consumidor tiene asociado un grupo de consumidores. Kafka garantiza que cada mensaje sólo es leído por un consumidor de cada grupo.

En la imagen, un cluster de kafka está formado por dos brokers con 4 particiones con dos grupos de consumidores. En el grupo de consumidores A, Kafka asigna dos particiones a cada consumidor, mientras que en el grupo B, al haber 4 consumidores para 4 particiones, es posible asignar una partición a cada consumidor.
APIs y Complementos de Kafka
Kafka dispone de 4 APIs principales que nos ayudan a implementar nuestras aplicaciones:
- Productor (producer): Permite publicar mensajes en topics de forma sencilla y configurable.
- Consumidor (consumer): Permite a la aplicación suscribirse a topics y recibir mensajes para procesar.
- Kafka Streams y KSQL: Facilita procesar un flujo consumiendo un flujo de entrada de uno o más topics y produciendo un flujo para uno o más topics de salida.
- Kafka Connect: Se trata de un framework que proporciona la capacidad de conectar Kafka con sistemas externos para mover datos hacia o desde nuestro clúster. Para usar un conector y agregar datos a Kafka se puede usar un modelo Pull, por ejemplo con JDBC o bien un modelo push como en las herramientas de CDC (Change Data Capture). Las apis de Kafka Connect Sink y Consumidor son intercambiables, pero la primera ahorra mucho trabajo de implementación y reduce el código y el tiempo que necesitaremos.

Además, proporciona herramientas como Mirror Maker, que nos ayuda a implementar nuestras arquitecturas multi-clúster con mirroring.
Además de estos componentes, existen numerosos conectores a fuentes externas de datos como HDFS, JDBC, S3, FTP, Elasticsearch, etc.
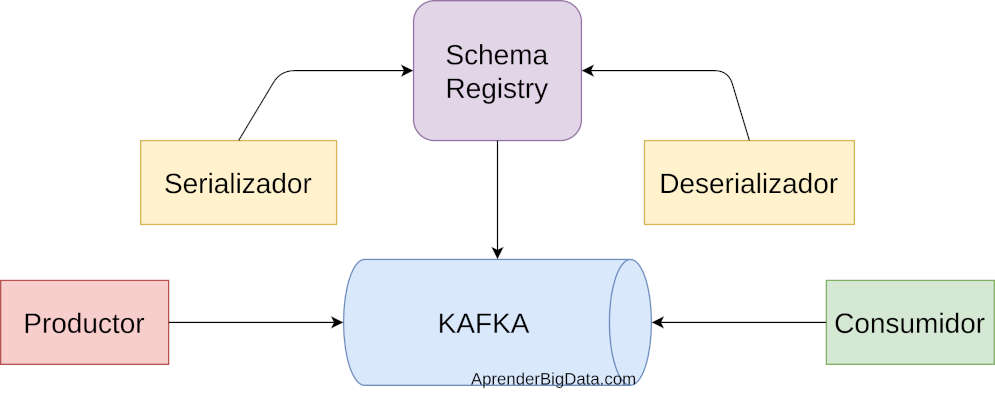
Schema Registry en Kafka
Schema Registry permite registrar esquemas de datos en formato JSON o Avro para Kafka sobre un repositorio centralizado. Permite asegurar que los datos se insertan en el topic correspondiente con un esquema concreto para cumplir la especificación y el entendimiento entre productores y consumidores.
Sirve una API REST para acceder al histórico versionado de los esquemas. Además, también proporciona los serializadores y deserializadores de datos necesarios para los clientes de Kafka.
Schema Registry nos facilita evolucionar el esquema y validar que no hay problemas de compatibilidad. Por ejemplo, para que los nuevos consumidores puedan leer registros antiguos, pero que los consumidores antiguos se deban actualizar para deserializar los nuevos mensajes. Si quisiéramos añadir un nuevo campo obligatorio a un esquema, deberíamos establecer un valor por defecto en este nuevo campo para que los nuevos consumidores puedan usar este esquema al leer registros antiguos.
Schema Registry tiene una interfaz de usuario (UI) que permite registrar nuevos esquemas, visualizarlos y comparar sus versiones de una forma sencilla.
Zookeeper en Apache Kafka
Apache Zookeeper es un servicio que ayuda a gestionar sistemas distribuidos como, por ejemplo, Apache Kafka. Ofrece a sistemas externos capacidades de almacenamiento clave-valor, sincronización y registro de nombres, entre otros.
Zookeeper proporciona a Kafka alta disponibilidad. Entre los nodos de Zookeeper, se elige uno como líder. El resto de nodos del clúster se denominan seguidores, y uno de ellos es elegido como nuevo líder en el caso de que el líder actual tenga un fallo. Generalmente, los clusters de Zookeeper se despliegan con 3 ó 5 nodos.
Para gestionar un clúster de Kafka, Zookeeper almacena información del estado del clúster: detalles de los topics como el nombre, las particiones, las réplicas y los grupos de consumidores.
En el momento en el que Zookeeper detecta que uno de los brokers de Kafka está caído, realiza las siguientes acciones:
- Elige un nuevo broker para tomar el lugar del broker caído.
- Actualiza los metadatos para la distribución de carga de los productores y los consumidores para que no exista pérdida de servicio.
Tras estas acciones, se pueden volver a escribir y leer mensajes con normalidad.
En el año 2019 se propone eliminar la dependencia de Kafka con Zookeeper reemplazándola con un mecanismo interno. Con la versión 2.8 (2021) se introduce la versión beta de KRaft como mecanismo de consenso para el protocolo de quorum. Kafka 3.3 marca este mecanismo como listo para producción. A partir de la versión 3.5 se proporciona un mecanismo de migración y se marca el soporte a Zookeeper como deprecado. Lee más en el artículo de Kafka sin Zookeeper.
Ventajas de Apache Kafka
En esta sección, enumeraré las ventajas más importantes de Apache Kafka:
- Permite desacoplar aplicaciones entre sí (útil en arquitecturas de microservicios)
- Sistema escalable horizontalmente, tolerante a fallos y con baja latencia (Big Data)
- Absorción de picos de carga que pueden ocurrir en el sistema
- Permite construir aplicaciones que reaccionan a eventos en tiempo real
- Referencia en la industria, lo usan las empresas más grandes del mundo
- Garantías de entrega de mensajes exactly-once (exactamente una vez)
- Transacciones a partir de Kafka 0.11
Desventajas de Apache Kafka
Kafka también tiene algunas desventajas, que enumeraré en esta sección:
- Kafka no es una tecnología que esté diseñada para manejar mensajes muy grandes (+ 1MB)
- Pocas opciones de monitorización potentes
- Opciones en Stream processing más limitadas que otras opciones como Apache Flink
- Operaciones de rebalanceo de datos en particiones a veces necesarias, lo que impacta en el rendimiento del sistema
Apache Kafka como base de datos
Si estamos dudando sobre si es posible reemplazar una base de datos con Apache Kafka, debemos tener en cuenta que cada base de datos del mercado tiene unas características diferentes. Para cada caso de uso se debe elegir la base de datos adecuada que cumpla con nuestros requisitos. Debemos plantear preguntas como cuánto tiempo almacenar los datos, qué estructura deben tener o qué tipo de consultas y con qué frecuencia se van a realizar.
Aunque Kafka se puede usar como una base de datos y proporciona garantías ACID, funciona de forma diferente a otras bases de datos. Puede proporcionar una base de almacenamiento persistente para los eventos y consultas pero no reemplaza a otras bases de datos, y debemos tratarla como una herramienta complementaria. La pregunta que debemos hacernos es: ¿necesitamos otro almacenamiento de datos adicional a Kafka en nuestro sistema?
Kafka no proporciona un lenguaje de consulta similar a otras bases de datos, sino que sirve toda una API de consumidores y productores de mensajes con mucha más funcionalidad. Las aplicaciones clientes son sistemas distribuidos que consultan, procesan y almacenan flujos de datos.
Un concepto que debemos evaluar al crear aplicaciones de Kafka es que pueden contener el estado o ser aplicaciones sin estado. Esta decisión es fundamental al crear microservicios, ya que podemos mantener el estado de la aplicación directamente en Kafka, lo que puede resultar una mejor opción o más sencilla que gestionar el estado en la aplicación.
Cómo elegir la distribución de Apache Kafka adecuada
Kafka se distribuye en varias alternativas comerciales que ofrecen soporte empresarial. Las más importantes son Confluent, Cloudera, Red Hat y Amazon MSK. Antes de tomar una decisión debemos analizar las opciones que existen y la forma en la que vamos a operar el servicio ya que todos estos vendors tienen sus fortalezas y debilidades. Por supuesto, siempre está la opción de usar la versión open source.
Confluent
- Enfocado totalmente a Streaming de Eventos de la mano de los creadores de Apache Kafka, donde son el principal contribuidor
- Soporte de la última versión disponible de Kafka
- Ecosistema de conectores, seguridad y herramientas completo
- Integración con proveedores cloud (AWS, Azure, GCP)
Cloudera
- Enfocado a analítica Big Data y lagos de datos con una plataforma que soporta numerosos frameworks de almacenamiento y procesamiento
- Apache Kafka forma parte de la plataforma, y está integrado completamente con las otras tecnologías soportando arquitecturas híbridas
- Integración con proveedores cloud (AWS, Azure, GCP)
Red Hat – IBM
- Enfocado en infraestructura PaaS Cloud con Linux y Kubernetes con Openshift Streams
- Soporte a frameworks open source y activos en la comunidad (CDC con Debezium)
- IBM también comercializa la plataforma de Confluent como parte de IBM Cloud Pak
- Integración con proveedores cloud (AWS, Azure, GCP)
Amazon MSK (AWS)
- Enfocado en infraestructura cloud como servicio manejado e integrado con S3, Lambda o Kinesis
- No tiene algunas características como Kafka Connect o Kafka Streams
- Solo disponible en AWS y el software que ejecuta por debajo (Apache Kafka) se excluye del soporte
Además de estas alternativas, podemos encontrar Azure Event Hubs, la solución SaaS que soporta el protocolo de Kafka. Tiene limitaciones alrededor del soporte a la API de Kafka y no soporta todos los conectores o Schema Registry.
Curso de Apache Kafka: Siguientes Pasos
Si quieres aprender Apache Kafka a fondo y convertirte en experto, no dudes en invertir en tu formación a largo plazo. Para ello, te dejo mi propio curso en español en el que aprenderás desde cero: con partes teóricas y partes prácticas. Es un curso fundamental para quien desee implementar sistemas escalables de procesamiento de datos en tiempo real.
¡Aquí tienes un enlace con el cupón!
Comienza con Kafka: Curso de Apache Kafka desde Cero
Aprende en estos artículos sobre otros brókers de mensajería populares:
Preguntas frecuentes de Apache Kafka – FAQ
¿Para qué se usa Apache Kafka?
Apache Kafka se usa como sistema de intermediación de mensajes entre aplicaciones. Varios suscriptores y publicadores externos pueden leer los mensajes almacenados en Kafka y de esta forma abstraer la complejidad asociada al tratamiento de mensajes de la aplicación.
¿Es Apache Kafka una base de datos?
Kafka es un sistema distribuido que trata los datos como un flujo continuo. Aunque cada vez se agrega mayor funcionalidad sobre este sistema no es una base de datos corriente ni tiene los mismos usos ni aplicaciones. Podemos considerar Kafka como una herramienta que puede complementar a una base de datos.
¿Qué es un bróker de Kafka?
Un bróker de Kafka es un nodo con Kafka instalado que forma parte del clúster. Permite a los suscriptores leer mensajes y se comunica con los demás brókers. Para sincronizarse también puede usar Apache Zookeeper.
¿Qué ventajas tiene Apache Kafka?
Apache Kafka permite desacoplar aplicaciones entre sí que necesiten comunicarse mediante paso de mensajes en tiempo real. Es un sistema escalable y con baja latencia, lo que hace una solución ideal para tratar grandes cantidades de datos en sistemas Big Data.
¿Es Kafka un sistema asíncrono?
Kafka permite implementar a las aplicaciones un sistema de comunicación asíncrono con el patrón publicador-subscriptor. Los productores de mensajes no deben esperar a que se consuman para continuar sus operaciones.

Arquitecto de Datos con más de 10 años de experiencia en el sector del Big Data. Autor de cursos de formación en tecnologías Big Data, Cloud y Streaming completados por más de 7000 alumnos en Udemy y otras plataformas. Miembro de la Apache Software Foundation desde 2019.


