Aprende en esta entrada por qué Apache Spark es un gran framewordatk y motor de procesamiento distribuido para los proyectos de ingeniería del software y Big Data. Analizamos sus aspectos clave, componentes y ejemplos sencillos de código.

Contenidos
Aspectos clave de Apache Spark
Apache Spark es un framework de procesamiento open source distribuido para Big Data. La característica principal es el uso que hace de las estructuras de datos en memoria llamadas RDD, con lo que consigue aumentar el rendimiento frente a herramientas como Hadoop considerablemente.
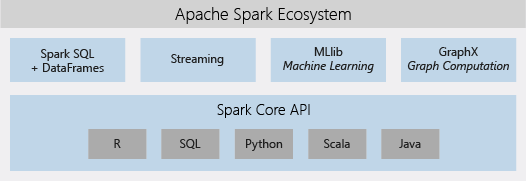
Spark fue desarrollado originalmente en la universidad de Berkeley y está escrito en Scala. Debido a la popularidad que ha tenido, se han desarrollado librerías y extensiones de la propuesta inicial. Estas han convertido a Spark en una plataforma diversa, que puede manejar casi todas las cargas de trabajo: batch, streaming, interactivas, grafos, etc.
- Procesamiento en memoria: Apache Spark es 100 veces más rápido en memoria y 10 veces más rápido en disco que Hadoop MapReduce, para ello necesita más recursos.
- Soporta múltiples lenguajes: Spark tiene APIs disponibles en los lenguajes Java, Scala, Python y R.
- Analítica avanzada: Para ello, soporta consultas SQL y su uso para Machine Learning con librerías de data science como MLlib y GraphX.
- Abstracción RDD (Resilient Distributed Dataset): consiste en una colección inmutable de elementos en memoria distribuída.
- Evaluación perezosa: Las transformaciones sobre los datos solo se resuelven al ejecutar una acción sobre ellos.
Ventajas
Si eres un desarrollador o ingeniero de datos implementando proyectos Big Data con demandas de rendimiento, Apache Spark es un framework de procesamiento que deberías contemplar.
Por un lado, Apache Spark tiene una gran base de desarrolladores y de contribuidores globalmente, por lo que se actualiza periódicamente con nuevas funcionalidades y tiene un soporte excelente en la comunidad. Gran parte de los desarrolladores de Spark también están involucrados en Databricks, la plataforma cloud basada en Spark.
Por otro lado, proporciona la escalabilidad necesaria para obtener un gran rendimiento en el procesamiento de datos batch y streaming. Su optimizador y motor de ejecución distribuye las operaciones en los datasets de forma que se pueden obtener resultados de forma eficiente.
Además, Spark soporta numerosas fuentes de datos y entornos de ejecución. Entre las fuentes de datos más comunes se encuentran HDFS, Hive, HBase o Cassandra. Puede ejecutar en entornos cloud, en contenedores con Kubernetes o en clusters de Apache Hadoop.
Ejemplos de Código Apache Spark
Visita este artículo para aprender cómo crear un proyecto de Apache Spark con IntelliJ.
Antes de escribir la lógica de nuestra aplicación, debemos inicializar una sesión de Spark. Este será el punto de partida. Se puede realizar fácilmente usando el builder de SparkSession:
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder()
.appName("Hello World con Spark")
.getOrCreate()
También, es muy común importar la conversión implícita para convertir RDDs a DataFrames o para usar la notación con el símbolo $:
import spark.implicits._
El siguiente ejemplo está escrito en Scala. Es una aplicación spark básica de tipo wordcount. Lee un fichero de texto, lo divide por palabras y cuenta las ocurrencias de cada palabra.
val textFile = sc.textFile("/tables/internet_archive_scifi_v3.txt")
val counts = textFile.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsTextFile("/tables/wordcountresult")
El ejemplo a continuación realiza el cálculo de la estimación de pi de forma paralela. Es una aplicación intensiva en cómputo.
var NUM_SAMPLES = 900000000
val count = sc.parallelize(1 to NUM_SAMPLES).filter { _ =>
val x = math.random
val y = math.random
x*x + y*y < 1
}.count()
println(s"Pi is roughly ${4.0 * count / NUM_SAMPLES}")
Spark Streaming
Spark Streaming extiende la funcionalidad de Spark para realizar procesamiento de datos en streaming o en tiempo real. Funciona como un wrapper sobre Spark batch, agrupando los datos recibidos en pequeños micro-batches, con lo que consigue unos buenos tiempos de respuesta. Es compatible con Yarn como gestor de trabajos en el clúster.
Proporciona dos tipos de operadores. El primer tipo son operadores que transforman DStream en un DStream diferente, incluyen operadores con y sin estado. El segundo tipo son operadores que se encargan de escribir los datos en sistemas externos.
¿Quieres Convertirte en Ingeniero de Datos?
Para mantener una tolerancia a fallos, Spark Streaming usa checkpointing. De esta manera, almacena el estado del sistema en instantes de tiempo para poder recuperar la información en el caso de que ocurra algún error en el driver. Este estado se almacena preferiblemente en un sistema de almacenamiento tolerante a fallos como HDFS.
Los trabajos Spark Streaming añaden una pestaña a la interfaz web de Spark que muestra las estadísticas y métricas de los registros procesados. Muestra gráficas que indican el retraso de planificación, el tiempo de procesamiento, las colas, etc.
Spark SQL
Apache Spark está diseñado para soportar procesamiento de datos distribuidos con un gran rendimiento, en múltiples casos de uso. Spark SQL, es un módulo de Spark para procesar datos estructurados. Es compatible con muchas fuentes de datos como Apache Hive, JDBC y formatos como Avro, Parquet, ORC y JSON.
También es muy eficiente para procesar datos semi-estructurados y está integrado con Hive Metastore y bases de datos NoSQL como HBase. Spark SQL resulta muy útil para incorporar consultas SQL en cargas de trabajo Spark. El caso de uso más común es en Ingeniería de datos, en cargas de trabajo con consultas SQL muy pesadas, que tardan en ejecutar pero no es necesaria una alta concurrencia.
Spark SQL está cobrando una importancia alta en el desarrollo de Spark y es que es de las funcionalidades más demandadas, siendo SQL el lenguaje preferido en tratamiento de datos. Las nuevas versiones de Spark como Spark 3.0 se acercan cada vez más a la compatibilidad completa con el estándar ANSI SQL.
Una vez que hemos inicializado nuestra sesión de Spark, podemos usar consultas SQL sobre un DataFrame (DataSet de Rows) de manera sencilla:
// Registramos el DataFrame como una vista temporal de SQL
df.createOrReplaceTempView("edades")
// Ahora podemos realizar consultas SQL usando ese nombre
val resultados = spark.sql("SELECT * FROM edades")
resultados.show()
Integración de Apache Spark con Almacenamiento de Objetos en la Nube
Los proveedores cloud ofrecen almacenamiento de objetos barato integrado con sus herramientas, los más populares son s3 en AWS y Blob Storage o ADLS en Azure. En estos sistemas, se reemplazan los sistemas de ficheros POSIX tradicionales por la gestión de objetos, a menudo sin espacios de nombres jerárquicos.
Apache Spark puede gestionar estos almacenamientos de objetos a través de conectores que usan sus APIs REST. Estos conectores permiten ver estos sistemas como si fueran sistemas de ficheros con directorios y sus operaciones clásicas.
Aunque puedan ser usados, debemos tener en cuenta que no son sistemas de ficheros tradicionales, y por tanto pueden ofrecer un peor rendimiento en algunas operaciones, como por ejemplo rename. Para determinar si nuestra aplicación Spark va a tener un rendimiento reducido con estos sistemas debemos estudiar las operaciones que realiza.
Siguientes pasos y Curso Recomendado de Spark
Si quieres aprender Apache Spark a fondo y convertirte en experto, no dudes en invertir en tu formación a largo plazo.

PySpark Práctico: Apache Spark para Ingenieros de Datos
Aprende a procesar datos con Apache Spark y PySpark de forma distribuida. Entenderás cómo funciona internamente el framework y las maneras de optimizar las cargas de trabajo con un estilo muy práctico y fácil de seguir.
Además, te dejo mis libros recomendados:
- Spark: The Definitive Guide: Big data processing made simple
- Advanced Analytics with Spark
- High Performance Spark
- Learning Spark: Lightning-Fast Big Data Analysis
- 99 Apache Spark Interview Questions for Professionals (Kindle)
Preguntas Frecuentes Apache Spark – FAQ
¿Apache Spark necesita Hadoop?
Apache Spark puede ejecutar sin Hadoop, no es necesario. HDFS es solamente uno de los sistemas de ficheros soportados por Spark, pero puede usar otros.
¿Cuándo usar Apache Spark?
Debemos contemplar Apache Spark como herramienta de procesamiento de datos distribuida cuando necesitemos implementar procesos de big data y machine learning. Estos procesos deberán beneficiarse de dividir las operaciones y de distribuir los trabajos en un cluster de varios nodos.
¿Qué lenguajes de programación usa Apache Spark?
Apache Spark usa la JVM y está escrito en Java y en Scala. Soporta múltiples lenguajes como Scala y Python. Python está más orientado al desarrollo de aplicaciones de analítica y Data Science.
A continuación el vídeo-resumen. ¡No te lo pierdas!

Arquitecto de Datos con más de 10 años de experiencia en el sector del Big Data. Autor de cursos de formación en tecnologías Big Data, Cloud y Streaming completados por más de 7000 alumnos en Udemy y otras plataformas. Miembro de la Apache Software Foundation desde 2019.


