No necesitas tener años de experiencia para usar Elasticsearch en tus proyectos. Lo mejor es que esta base de datos incluye un motor de búsqueda de texto muy potente que te permitirá implementar diferentes aplicaciones con facilidad.
Si quieres explotar esta tecnología al máximo no te pierdas la entrada, en la que vamos a aprender en un mini tutorial las particularidades, los casos de uso y las ventajas que ofrece Elasticsearch.

Contenidos
¿Qué es Elasticsearch?
Elasticsearch es una base de datos NoSQL open source muy popular en Big Data basado en Apache Lucene como motor de búsqueda. La empresa que da soporte al producto es Elastic, de la que forman parte la mayor parte de los committers del proyecto, que está escrito en el lenguaje de programación Java.
Lucene es un proyecto de la Apache Software Foundation que implementa un motor de búsqueda de texto. Este proyecto se integró en Elasticsearch y su uso se ha extendido al entorno corporativo.
Además, Elasticsearch nos permite almacenar datos de una forma escalable y realizar búsquedas de texto más avanzadas que las disponibles en SQL o con expresiones regulares. Esto resulta muy útil, por ejemplo para realizar búsquedas y análisis de logs o en datos de métricas.
También, permite reconocer lexemas, abreviaturas, extraer las posiciones de las palabras, sus frecuencias de aparición, etc.
Arquitectura de Elasticsearch
Para entender la arquitectura y el funcionamiento de Elasticsearch debemos conocer qué son los shards. Cada shard es una instancia de un índice de Lucene, que contiene un subconjunto de los datos.
Los shards son las unidades de distribución de datos del clúster. Por defecto hay 5 shards por índice. Elastic puede manejar un hilo de ejecución por cada shard aumentando la paralelización de las búsquedas y operaciones.
Existen shards primarios, que son los primeros en indexar un documento, y shards réplicas, que replican la indexación y las búsquedas a partir de las operaciones de los shards primarios. Por defecto existe 1 réplica por cada shard primario. Además, es posible realizar snapshots y restaurar backups de todos los datos e índices.
El índice de Lucene es un shard en Elasticsearch. A su vez, Lucene divide el shard en segmentos y puntos de commit (commit points). Los segmentos son índices invertidos, que aceleran las búsquedas y dependen de puntos de commit que forman las estructuras de datos con los documentos.

En el esquema podemos ver la relación entre los segmentos y los índices de Elasticsearch y Lucene.
Roles del Clúster
Cuando se despliega como clúster, debemos considerar los roles que pueden tomar los nodos. Cada nodo del clúster puede ejecutar uno o varios roles.
- Master node: Se encarga de realizar la gestión de los índices, la distribución de los shards en los nodos de datos (data nodes) y su seguimiento.
- Data node: Encargados de almacenar los shards y ejecutar los procesos de búsqueda y de indexación.
- Ingest node: Este tipo de nodo se encarga de realizar la ingesta de los datos. Para ello, escucha las entradas de datos que se producen y los escribe. Estas operaciones las realiza en memoria.
- Coordinating node: Nodos encargados de balancear la carga y de preprocesar los datos en las fases de agregación.
Es recomendado separar estos roles en diferentes nodos en clusters grandes (a partir de 10 nodos).
Los servicios del clúster se comunican entre ellos por el puerto TCP 9300. También se puede habilitar el autodescubrimiento de nodos, de forma que se facilita la configuración del clúster.
La configuración de Elasticsearch es muy flexible, y merece la pena investigar en la documentación por las posibilidades que ofrece. El formato de esta configuración es YAML (yml).
¿Cómo Funciona Elasticsearch?
La información en Elasticsearch se organiza mediante índices. Cada documento se trata como un elemento de un índice. Dentro de un documento existen campos, que son las propiedades del documento.
Un documento es autocontenido puesto que contiene toda la información necesaria respecto a su estructura. Elasticsearch puede definir dinámicamente los esquemas llamados mappings a partir de los documentos que se indexan.
| Elasticsearch | Base de datos Relacional |
|---|---|
| Índice | Base de datos |
| Documento | Fila (registro) |
| Campo | Columna |
| Mapping | Esquema |
Por ejemplo, podemos usar la API para crear un nuevo índice con un mapping explícito de la siguiente forma:
PUT /mi-indice-000001
{
"mappings": {
"properties": {
"edad": { "type": "integer" },
"email": { "type": "keyword" },
"nombre": { "type": "text" }
}
}
}
Si queremos interaccionar mediante la API, podemos hacerlo con una llamada CURL desde la consola especificando nuestro endpoint (localhost) y el content-type (JSON):
curl -X PUT "localhost:9200/mi-indice-000001?pretty" -H 'Content-Type: application/json' -d'
{
"mappings": {
"properties": {
"edad": { "type": "integer" },
"email": { "type": "keyword" },
"nombre": { "type": "text" }
}
}
}
'
De esta forma, habremos creado un índice con tres campos y sus tipos de datos: edad (entero), email (keyword) y nombre (texto). Posteriormente también es posible modificar este índice añadiendo nuevos campos.
En cualquier momento podemos consultar el mapping de un índice con una consulta de tipo GET a la API:
curl -X GET "localhost:9200/mi-indice-000001/_mapping?pretty"
...
{
"mi-indice-000001" : {
"mappings" : {
"properties" : {
"edad" : {
"type" : "integer"
},
"email" : {
"type" : "keyword"
},
"nombre" : {
"type" : "text"
}
}
}
}
}
También podemos usar la API GET /_cat/indices para listar los índices.
En el futuro, escribiré más entradas explicando en profundidad las queries en Elasticsearch y cómo usar filtros avanzados.
Herramientas
Elasticsearch dispone de numerosas herramientas para realizar consultas y explotar los datos almacenados. Por un lado, existen clientes REST como curl o Postman que nos permiten interaccionar directamente con la API. Por otro lado, tenemos clientes para muchos lenguajes de programación como Python o Java. Incluso existe la posibilidad de usar SQL para las consultas junto con ODBC o JDBC.
También debemos conocer Kibana, la interfaz oficial de Elastic, que es un proyecto muy popular. Es una aplicación de servidor que requiere Elasticsearch y permite implementar interfaces de monitorización y de visualización de datos.
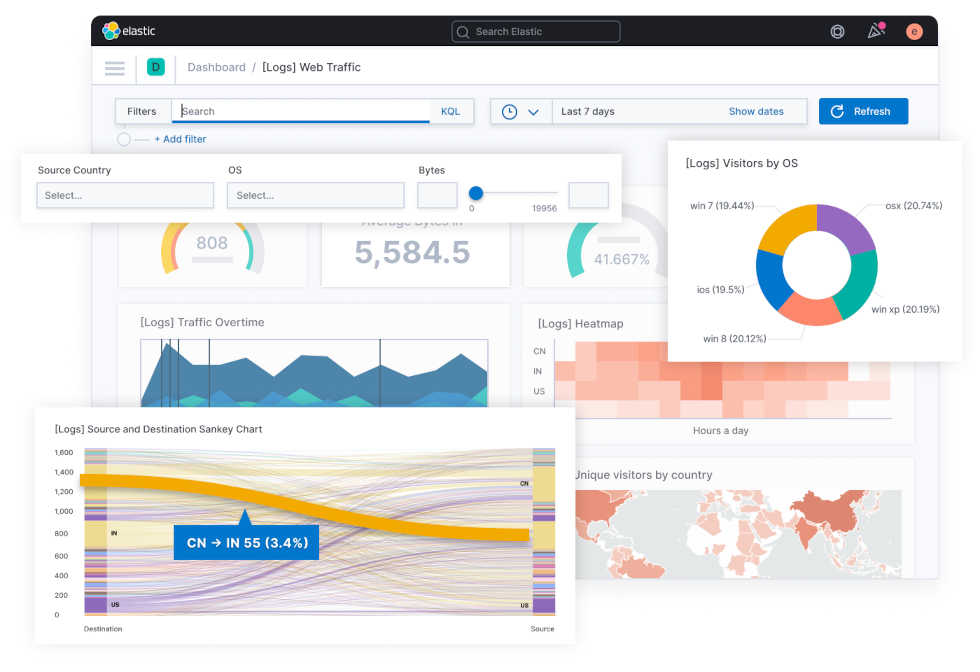
Kibana forma parte de un stack muy conocido abreviado como ELK, compuesto por las tecnologías opensource Elasticsearch, Logstash y Kibana. En este stack, Elasticsearch es el motor de búsquedas analítico, Logstash se encarga de la ingesta y de las transformaciones de datos. Por último, Kibana nos permite visualizar los datos.
También, es común introducir Apache Kafka como buffer de datos antes de Logstash. De esta forma, aumentamos la capacidad del sistema y su tolerancia a fallos.
Una alternativa a Kibana también muy popular para visualizar datos con Elasticsearch es Grafana. Esta herramienta de visualización open source es similar a Kibana, aunque algo más orientada a monitorización de métricas.
Casos de Uso
Entre los casos de uso podemos destacar los siguientes ejemplos:
- Almacenamiento y búsqueda en logs
- Machine learning
- Monitorización de métricas de clusters o de redes
- Datos de geoposicionamiento
- Almacenamiento de series temporales y datos numéricos
Ventajas de Elasticsearch
Las principales ventajas de usar Elasticsearch en los proyectos son las siguientes:
- Acceso a los datos en tiempo real
- Construido con APIs REST para acceder a todas sus capacidades
- Sistema distribuido, escalable y tolerante a fallos
- Compatible con gran cantidad de sistemas y lenguajes de programación al estar basado en JSON
- Indexación de documentos basada en Apache Lucene
Alternativas a Elasticsearch
Elasticsearch se compara generalmente con otras bases de datos NoSQL y sistemas de búsqueda de documentos. Entre estas herramientas se encuentran MongoDB o Solr. También se puede comparar con Lucene, aunque es el corazón de Elasticsearch.
MongoDB es una base de datos más flexible, orientada a manejar datos de todo tipo y en prácticamente cualquier proyecto. En el caso de Elasticsearch, ofrece la ventaja de proporcionar un motor de búsqueda distribuido mucho más avanzado. Esto le da una ventaja, por lo que en ocasiones se complementa con otras bases de datos NoSQL.
¿Quieres Convertirte en experto en Análisis de Datos?
Azure también ofrece su servicio de Elasticsearch. Este incluye el stack ELK con integración completa. Lo mismo sucede con AWS, que proporciona estas herramientas como servicio e integradas con toda su suite de productos.
Cómo Instalar Elasticsearch
Instalar Elasticsearch es muy sencillo. Podemos descargar la versión que necesitemos para nuestro sistema operativo desde la web de Elastic.
Una vez descargado el fichero, lo descomprimimos y vemos que tiene la estructura de directorios típica. Para iniciar una instancia con la configuración por defecto en Linux, ejecutaremos el comando:
./bin/elasticsearch
Cuando está en ejecución, podemos usar la propia API para consultar su estado. Por ejemplo con Postman o con la utilidad curl desde la consola de Linux:
curl -X GET "localhost:9200/_cat/health?v=true&pretty"
Otra opción es usar Docker si necesitamos un entorno local para desarrollo o pruebas. Por ejemplo, si queremos descargar la versión 7.10.1, usaremos el siguiente comando de Docker:
docker pull docker.elastic.co/elasticsearch/elasticsearch:7.10.1
Además, podemos crear un clúster sencillo usando Kubernetes:
apiVersion: elasticsearch.k8s.elastic.co/v1
kind: Elasticsearch
metadata:
name: quickstart
spec:
version: 7.10.1
nodeSets:
- name: default
count: 1
config:
node.store.allow_mmap: falseSiguientes Pasos, Formación y Cursos Recomendados
Continúa formándote sobre Elasticsearch y explota todas las ventajas de esta tecnología NoSQL con estos dos cursos online recomendados, los mejores de Coursera y de Udemy:

Arquitectura de bases de datos, escalado y NoSQL con Elasticsearch
Este curso de la Universidad de Michigan en Coursera es una excelente forma de iniciarse en el uso de Elasticsearch desde cero. Te enseñará los conceptos básicos y cómo se compara con otras bases de datos relacionales como PostgreSQL.
Guía completa de Elasticsearch y ELK Stack: Elasticsearch, Logstash, Kibana
Con este curso podrás aprender en 12 horas a usar Elasticsearch, Logstash y Kibana para analizar y visualizar datos. El instructor explica paso a paso cómo implementar una solución de análisis de logs con el stack ELK de forma práctica.
Aquí tienes los mejores libros recomendados para aprender más sobre Elasticsearch:
- Elasticsearch 7.0 Avanzado: una guía práctica para diseñar, indexar y consultar motores de búsqueda distribuidos avanzados (inglés)
- La guía definitiva de Elasticsearch: un motor de análisis y búsqueda distribuido en tiempo real (inglés)
- Elasticsearch en acción (inglés)
Preguntas Frecuentes Elasticsearch – FAQ
¿Para qué sirve Elasticsearch?
Elasticsearch es una base de datos y un potente motor de búsqueda que se usa para analizar grandes cantidades de datos con baja latencia. Es un sistema open source, distribuido y escalable, lo que le permite implementar numerosos casos de uso.
¿Elasticsearch es una base de datos?
Elasticsearch es una base de datos NoSQL documental, almacena datos no estructurados y semi estructurados y el principal mecanismo de consulta no es SQL.
¿Por qué es tan rápido Elasticsearch?
Elasticsearch es capaz de dar respuestas de búsqueda con muy baja latencia ya que no busca directamente en el texto sino en sus índices. Estas estructuras de datos están optimizadas para devolver rápidamente las correspondencias correctas.
¿Cuál es la diferencia entre Elasticsearch y Logstash?
Elasticsearch actúa como base de datos y motor de búsqueda. Logstash puede realizar la ingesta de datos actuando como servidor. En este proceso, también puede realizar transformaciones de datos en tiempo real.
A continuación, el vídeo-resumen. ¡No te lo pierdas!

Arquitecto de Datos con más de 10 años de experiencia en el sector del Big Data. Autor de cursos de formación en tecnologías Big Data, Cloud y Streaming completados por más de 7000 alumnos en Udemy y otras plataformas. Miembro de la Apache Software Foundation desde 2019.



{kind=link}