En esta entrada aprenderemos en qué consiste Apache Kylin y cómo implementar procesamiento OLAP sobre Hadoop.
Vamos a ver los componentes, su arquitectura y los conceptos más interesantes alrededor de esta tecnología para que puedas incorporarla a tus proyectos Big Data.

Contenidos
¿Qué es Apache Kylin?
Apache Kylin es un proyecto open source que permite realizar procesamiento analítico distribuido para Big Data. Está mantenido por la comunidad y la Apache Software Foundation.
Kylin nos proporciona las propiedades de un Data Warehouse analítico OLAP en tiempo real. Consigue llevar estas capacidades al mundo distribuido y de esta forma permite escalar horizontalmente.
El objetivo de Kylin es servir a los clientes un sistema capaz de devolver los datos con baja latencia. Para ello tiene conectores con sistemas externos de BI como Tableau, Qlikview o JDBC/ODBC, una API Rest y se pueden realizar consultas en ANSI SQL con Apache Calcite, que optimiza las consultas que se escriben.
Kylin tiene una versión empresarial llamada Kyligence. Esta versión es de pago y tiene ciertas diferencias. Kyligence no usa HBase como capa de almacenamiento sino una tecnología llamada KyStorage. También aporta integración multi cloud con AWS y Azure y nos proporciona más conectores y un soporte avanzado.
Para entender cómo funciona Apache Kylin y su arquitectura debemos repasar el concepto de cubo OLAP en un Data Warehouse.
¿Qué es OLAP?
OLAP (Procesamiento analítico online) es un término que se usa para denominar al análisis de datos de registros en varias dimensiones.
El procesamiento OLAP también se conoce como cubos. Un cubo OLAP se caracteriza por contener datos con varias dimensiones o categorías además de una dimensión temporal. Estas columnas o dimensiones representan los campos por los que se van a agregar los datos.
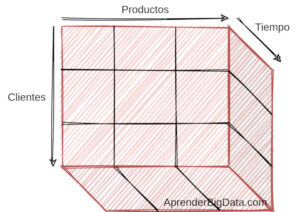
Detrás de una agregación siempre existe una función, como puede ser un sumatorio. A su vez, cada agregación se convierte en un cubo.
Para acelerar los tiempos de respuesta, es común precalcular las consultas de agregación o agrupación. Realizar estos cálculos en tiempo de consulta sería muy costoso e ineficiente. Además, los tiempos de respuesta aumentarían considerablemente.
OLAP es un proceso que toma los datos ya presentes en un Data Warehouse como Apache Hive para iniciar los precálculos de los cubos.
Los sistemas tradicionales como las bases de datos relacionales tienen problemas para distribuir estos precálculos y realizarlos en tiempo real de forma escalable (Big Data).
¿Quieres Convertirte en Ingeniero de Datos?
El concepto de OLAP en tiempo real consiste en realizar los precálculos a medida que llegan los datos al sistema. Cada vez que se realiza una de estas operaciones, el resultado está disponible para su consulta.
Arquitectura de Apache Kylin
Apache Kylin soporta varias fuentes de datos: Apache Hive, Apache Kafka, Hadoop y bases de datos relacionales.
Como motor de procesamiento, en el que realiza las preagregaciones de los cubos OLAP, Kylin usa Hadoop o Spark.
Por último, Apache Kylin se apoya en un clúster de HBase para almacenar las preagregaciones, de forma que la latencia de consulta sea mínima (del orden de milisegundos en un entorno distribuido). Los cubos almacenados se parten en segmentos a partir de una columna.

Para esquematizar el funcionamiento de Kylin debemos entender que transforma los datos de un sistema relacional basado en filas o registros de datos en un sistema de clave valor que almacena todas las combinaciones requeridas. La clave compone las dimensiones, mientras que el valor es el compuesto de las medidas.
Para realizar estas transformaciones se basa en el paradigma map reduce en ambos motores. Se aplican las fases de map, shuffle y reduce, que hacen la explosión combinatoria necesaria para calcular las dimensiones que forman parte del cubo OLAP.
El modelo de datos en Kylin es un diseño en estrella de un cubo. Consiste en una tabla de hechos central y varias dimensiones alrededor de ella que expresan las condiciones de filtro.
Se considera una tabla en Kylin a las fuentes de datos para los cubos, podría ser una tabla en Hive o un topic en Kafka.
Existen dos modelos de procesamiento que conviven en Kylin: el modelo Batch y de tiempo real:
Batch OLAP
Es la primera implementación que se realizó en Kylin. Los pasos que tiene son los siguientes:
- Cargar la tabla de Hive
- Crear el modelo y la descripción del cubo
- Construir el cubo (Hadoop/Spark)
- Acceder al cubo con consultas
Real Time OLAP
En el caso de OLAP en tiempo real el objetivo principal es reducir la latencia de los precálculos.
Para servir consultas en tiempo real, el servidor de consultas (query server) de Kylin examina la query para determinar si los datos se encuentran en el histórico (HBase) o si aún no han sido precalculados.
En el caso de que aún no hayan sido precalculados, se envía la consulta a un nodo real time, que realiza estas operaciones en memoria. Posteriormente, se combinan los resultados de ambas operaciones.
Cómo Ejecutar Apache Kylin en Linux
Para ejecutar Apache Kylin en Linux, se pueden seguir los siguientes pasos:
- Descargar Apache Kylin desde el sitio web oficial de Apache Kylin, en https://kylin.apache.org/download/.
- Descomprimir el archivo de instalación en un directorio local en Linux, utilizando un comando como
tar -xzvf kylin-<version>.tar.gz. - Acceder al directorio de instalación y ejecutar el script de inicio, utilizando un comando como
bin/kylin.sh start. - Verificar el estado del servicio de Apache Kylin, utilizando un comando como
bin/kylin.sh status, y asegurarse de que el servidor se haya iniciado correctamente. - Acceder a la consola de administración de Apache Kylin en un navegador web, utilizando la dirección URL http://localhost:7070/kylin, y utilizar las credenciales de acceso predeterminadas (
ADMIN / KYLIN) para iniciar sesión.
En general, ejecutar Apache Kylin en Linux requiere descargar y descomprimir el paquete de instalación de Apache Kylin, ejecutar el script de inicio del servidor, verificar el estado del servicio y acceder a la consola de administración en un navegador web.
En el caso de dar con algún problema en la ejecución, podemos realizar algunas acciones como verificar el estado del servicio, el archivo de registro, la configuración y los requisitos del sistema:
- Verificar el archivo de registro de Apache Kylin, que se encuentra en el directorio
logsdentro del directorio de instalación de Apache Kylin, y buscar errores o mensajes de advertencia que puedan indicar el problema o la causa del fallo. - Revisar la configuración, especialmente el archivo de configuración principal
kylin.properties, y asegurarse de que los valores estén correctamente configurados y no haya conflictos o errores de sintaxis. - Verificar los requisitos del sistema y las dependencias de Apache Kylin, y asegurarse de que se cumplan en el sistema Linux donde se está ejecutando. Por ejemplo, se debe tener Java 8 o superior instalado y configurado en el sistema Linux.
- Consultar la documentación y la comunidad de Apache Kylin, que incluyen recursos como guías, tutoriales y foros en línea, donde se pueden encontrar soluciones a problemas comunes y consejos para resolver problemas.
Alternativas a Apache Kylin
Otras tecnologías que nos permiten tratar un modelo de procesamiento OLAP en big data son Apache Druid, Atscale o Dremio.
Apache Druid también aporta una solución madura en cuanto a procesamiento OLAP en tiempo real. Druid proporciona bajas latencias combinando los resultados y calculando los históricos en tiempo real.
Siguientes Pasos con Apache Kylin

Apache Kylin: Implementando OLAP sobre la plataforma de Hadoop
Profundiza más en Apache Kylin con este curso de Udemy en inglés que te proporcionará todos los conocimientos clave.
Aprenderás cómo construir y realizar consultas sobre sistemas OLAP con más de 6 horas de vídeo guiadas paso a paso.
Preguntas Frecuentes
¿Qué tipos de datos se pueden analizar con Apache Kylin?
Apache Kylin puede analizar datos transaccionales, logs de servidor, datos de sensores IoT, y cualquier otro tipo de datos almacenados en Hadoop. Su flexibilidad permite modelar datos en diversas formas y realizar análisis multidimensionales complejos.
A continuación, el vídeo-resumen. ¡No te lo pierdas!

Arquitecto de Datos con más de 10 años de experiencia en el sector del Big Data. Autor de cursos de formación en tecnologías Big Data, Cloud y Streaming completados por más de 7000 alumnos en Udemy y otras plataformas. Miembro de la Apache Software Foundation desde 2019.


