En este artículo introductorio, aprenderás qué es Apache Hive y sus fundamentos como tecnología de Data Warehouse. Tampoco te pierdas todas sus aplicaciones en Big Data, arquitectura, sus casos de uso, ventajas y desventajas.

Contenidos
¿Qué es Apache Hive?
Hive es una tecnología distribuida diseñada y construida sobre Hadoop. Permite hacer consultas y analizar grandes cantidades de datos almacenados en HDFS, en la escala de petabytes. Tiene un lenguaje de consulta llamado HiveQL o HQL que internamente transforma las consultas SQL en trabajos MapReduce que ejecutan en Hadoop. El lenguaje de consulta HQL es un dialecto de SQL, que no sigue el estándar ANSI SQL, sin embargo es muy similar.
El proyecto comenzó en el 2008 y fue desarrollado por Facebook para hacer que Hadoop se comportara de una manera más parecida a un data warehouse tradicional. La tecnología Hadoop es altamente escalable, sin embargo tiene dos problemas principales:
- Dificultad de uso: La API de Java es complicada de usar y se necesita experiencia específica para tratar con diferentes formatos de ficheros y sistemas de almacenamiento.
- Orientado a operaciones Batch: No soporta operaciones de acceso aleatorio y no está optimizado para gestionar ficheros pequeños.
Los datos gestionados por Hive son datos estructurados almacenados en HDFS. Así, optimiza de forma automática el plan de ejecución y usa particionado de tablas en determinadas consultas. También soporta diferentes formatos de ficheros, codificaciones y fuentes de datos como HBase.
Una consulta típica en Hive ejecuta en varios data nodes en paralelo, con trabajos MapReduce asociados. Estas operaciones son de tipo batch, por lo que la latencia es más alta que en otros tipos de bases de datos. Además, hay que considerar el retardo producido por la inicialización de los trabajos, sobre todo en el caso de consultar pequeños datasets.
Hive incorpora Beeline, un cliente basado en JDBC para hacer consultas por línea de comandos contra el componente HiveServer, sin necesitar las dependencias de Hive. Por otro lado, también incorpora Hive CLI, un cliente basado en Apache Thrift, que usa los mismos drivers que Hive.
Hive como Data Warehouse
Cuando se empezaba a generalizar el procesamiento de datos de negocio masivos, se usaban las mismas bases de datos para procesar las transacciones y para hacer consultas analíticas. Sin embargo, las organizaciones pronto empezaron a separar las consultas analíticas a una base de datos distinta llamada Data Warehouse.
Esta base de datos contiene copias de solo lectura de todos los datos en los sistemas transaccionales y operacionales (OLTP). Los datos se extraen periódicamente de las bases de datos OLTP, se transforman y se limpian para adaptarlos esquemas que facilitan la analítica y se insertan en el Data Warehouse (OLAP). Este es el proceso conocido como ETL.
El modelo OLTP (Online Transaction Processing) requiere operaciones transaccionales. Es una categoría de procesamiento basada en tareas transaccionales, generalmente consisten en actualizar, insertar o eliminar pequeños conjuntos de datos. Para mantener su integridad, estas bases de datos deben cumplir las propiedades ACID, que garantizan la Atomicidad, Consistencia, Aislamiento y Durabilidad de las transacciones.
¿Quieres Convertirte en Ingeniero de Datos?
Por otra parte, aunque Hive está más cerca de ser una base de datos tipo OLAP (Online Analytical Processing), tampoco satisface la parte en línea o la rapidez de respuesta, como hace Apache Kylin. Estas herramientas típicamente están optimizadas para consultar grandes conjuntos de datos o todos los registros disponibles.
Aunque Apache Hive no es una herramienta de ETL específica, permite a los usuarios escribir consultas SQL para realizar operaciones de ETL en grandes conjuntos de datos almacenados en Hadoop. Existen otras herramientas de ETL que pueden ser más adecuadas para ciertos escenarios de uso, por ejemplo, Apache NiFi.
Estructura de datos en Hive
Hive proporciona una estructura basada en tablas sobre HDFS. Soporta tres tipos de estructuras: Tablas, particiones y buckets. Las tablas se corresponden con directorios de HDFS, las particiones son las divisiones de las tablas y los buckets son las divisiones de las particiones.
Hive permite crear tablas externas, similares a las tablas en una Base de datos, pero a la que se les proporciona una ubicación. En este caso, cuando se elimina la tabla externa, los datos continúan en HDFS.
Las particiones en Hive consisten en dividir las tablas en varios subdirectorios. Esta estructura permite aumentar el rendimiento de las consultas en el caso de usar filtros con cláusula WHERE.
Otro concepto importante en Hive son los Buckets. Son particiones hasheadas, en las que los datos se distribuyen en función de su valor hash. Los Buckets pueden acelerar las operaciones de tipo JOIN si las claves de particionado y de JOIN coinciden. Debido a los beneficios de las particiones, se deben considerar siempre que puedan optimizar el rendimiento de las consultas realizadas.
| ENTIDAD | EJEMPLO | UBICACIÓN |
|---|---|---|
| base de datos | testdb | $WH/testdb.db |
| tabla | T | $WH[/testdb.db]/T |
| partición | fecha=’01012020′ | $WH[/testdb.db]/T/fecha=01012020 |
| bucket column | userid | $WH[/testdb.db]/T/fecha=01012020/000000_0 … $WH[/testdb.db]/T/fecha=01012020/000032_0 |
Hive también permite una operación de sampling sobre una tabla, por la que se obtienen valores aleatorios o una «muestra» sobre la que realizar analítica o transformaciones sin tener que tratar el dataset completo, que en ocasiones es inviable.
La política del esquema es schema-on-read, de forma que solo se obliga en las operaciones de lectura. Esta propiedad permite a Hive ser más flexible en la lectura de los datos: un mismo dato se puede ajustar a varios esquemas, uno en cada lectura. Los sistemas RDBMS tienen una política schema-on-write, que obliga a las escrituras a cumplir un esquema. En este caso acelera las lecturas.
Arquitectura de Apache Hive: Componentes

En Hive 3 se deja de soportar MapReduce. Apache Tez lo reemplaza como el motor de ejecución por defecto. Tez es un framework de procesamiento que mejora el rendimiento y ejecuta sobre Hadoop Yarn, que encola y planifica los trabajos en el clúster. Además de Tez, Hive también puede usar Apache Spark como motor de ejecución.
Hive Server
HiveServer 2 (HS2) es la última versión del servicio. Se compone de una interfaz que permite a clientes externos ejecutar consultas contra Apache Hive y obtener los resultados. Está basado en Thrift RPC y soporta clientes concurrentes.
Hive Metastore
Reside en una base de datos relacional como MySQL, PostgreSQL o Apache Derby (base de datos interna), donde persiste la información. Mantiene un seguimiento de los metadatos, las tablas y sus tipos mediante Hive DDL (Data Definition Language). Además, el sistema se puede configurar para que también almacene estadísticas de las operaciones y registros de autorización para optimizar las consultas.
En las últimas versiones de Hive, este componente se puede desplegar de forma remota e independiente, para no compartir la misma JVM con HiveServer. El HCatalog o Hive Catalog es una parte de Hive Metastore, y es la herramienta que permite acceder a sus metadatos, actuando como una API. Al poder desplegarse de forma aislada e independiente, permite que otras aplicaciones hagan uso del Schema sin tener que desplegar el motor de consultas de Hive.

Hive LLAP
Hive LLAP (Low Latency Analytical Processing) fue añadido como motor a Hive 2.0. Requiere Tez como motor de ejecución y aporta funcionalidades de caché de datos y metadatos en memoria, acelerando mucho algunos tipos de consulta. Es especialmente significativo en consultas repetitivas para las que ofrecer tiempos de respuesta menores al segundo.
LLAP se compone de un conjunto de demonios que ejecutan partes de consultas Hive. Las tareas de los ejecutores, por tanto, se encuentran dentro de los demonios y no en los contenedores. En este caso, la sesión Tez tendrá solamente un contenedor, que corresponde al coordinador de consultas.
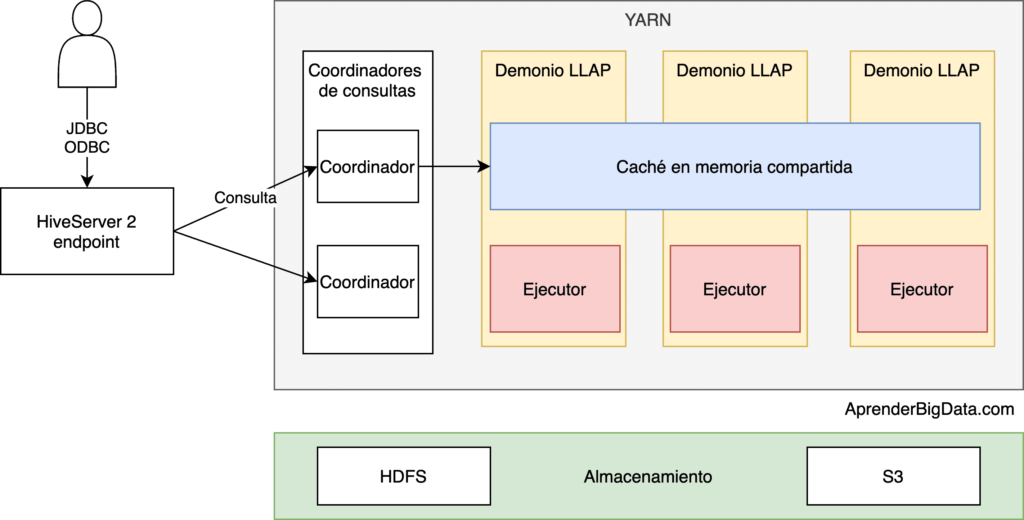
Hive LLAP tiene en cuenta las transacciones ACID y tiene una política de desalojo de caché personalizable y optimizada para operaciones analíticas. También soporta federación de consultas en HDFS, almacenamiento de objetos e integración con tecnologías de streaming y de tiempo real como Apache Kafka y Apache Druid.
Es una tecnología similar a Apache Impala pensada para cargas big data. Hive LLAP es ideal en entornos empresariales de Data Warehouse, en los que nos podemos encontrar consultas repetitivas pero muy pesadas en su primera ejecución, con transformaciones complejas y joins sobre grandes cantidades de datos.
Ventajas
- Reduce la complejidad de la programación MapReduce al usar HQL como lenguaje de consulta (dialecto de SQL).
- Está orientado a aplicaciones de tipo Data Warehouse, con datos estáticos, poco cambiantes y sin requisitos de tiempos de respuesta rápidos.
- Permite a los usuarios despreocuparse de en qué formato y dónde se almacenan los datos.
- Incorpora Beeline: una herramienta por línea de comandos para realizar consultas con HQL.
Desventajas
- Hive no es la mejor opción para consultas en tiempo real o de tipo OLTP (Online Transaction Processing).
- Hive no está diseñado para usarse con actualizaciones de valores al nivel de registro.
Entre las limitaciones de Apache Hive, se encuentran las siguientes relativas al lenguaje SQL:
- La subconsulta debe aparecer en el lado derecho de la expresión.
- Una misma consulta sólo puede tener una expresión de subconsulta.
- No admite subconsultas anidadas.
- El predicado de la subconsulta debe aparecer como una conectiva de nivel superior.
- Las subconsultas admiten cuatro operadores lógicos en los predicados de las consultas: IN, NOT IN, EXISTS y NOT EXISTS.
- Los operadores lógicos IN y NOT IN solo pueden seleccionar una columna en la subconsulta WHERE.
- Los operadores EXISTS y NOT EXISTS deben tener al menos un predicado relacionado.
- El lado izquierdo de la subconsulta debe calificar todas las referencias a las columnas de la tabla.
- Las subconsultas correlacionadas con sentencias GROUP BY sólo pueden devolver una fila.
- Sólo se permite hacer referencia a columnas de la consulta principal en la cláusula WHERE de la subconsulta.
- Los predicados de la subconsulta que hacen referencia a columnas de la consulta principal deben utilizar el operador de predicado igual (=).
- El predicado de la subconsulta no puede referirse únicamente a las columnas de la consulta principal.
- Todas las referencias no cualificadas a las columnas de la subconsulta deben resolverse en las tablas de la subconsulta.
Ejemplo de consulta en Apache Hive
A continuación vamos a escribir un ejemplo de consultas en Apache Hive con HiveQL. Los comandos en HiveSQL son muy parecidos a SQL estándar. Para empezar podemos crear una base de datos:
CREATE DATABASE mydb;
USE mydb;La sintaxis para crear una tabla es la siguiente:
CREATE TABLE IF NOT EXISTS mydb.pagina (
view_time INT,
user_id BIGINT,
page_url STRING,
ip STRING
PARTITIONED BY (dt STRING)
CLUSTERED BY (user_id) INTO 32 BUCKETS
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS ORC;Con ello, hemos creado una tabla llamada pagina con 4 columnas. Se ha especificado una partición y la columna user_id se usará para el bucket. El formato indica ORC (Binario).
Para insertar datos podemos cargarlos de un fichero o bien insertar los valores desde la propia consulta:
LOAD DATA LOCAL INPATH '/tmp/pagina_2020-01-01.txt'
OVERWRITE INTO TABLE mydb.pagina
PARTITION (dt='2020-01-01');
INSERT INTO TABLE mydb.pagina partition(dt='2020-01-01')
values (1,1,'s1','t1');Especificando LOCAL, indicamos que el fichero se encuentra en el sistema de ficheros local. Por defecto, interpretará que el fichero se encuentra en HDFS.
Hive vs Spark, ¿Cuál es mejor?
Ambas son herramientas muy populares en big data. Hive es mejor opción para analítica en volúmenes de datos masivos usando SQL. Spark proporciona una alternativa más rápida y moderna que MapReduce.
Es difícil decir de manera general si Hive es «mejor» que Spark o viceversa, ya que depende de las necesidades específicas de cada usuario y el contexto en el que se estén utilizando estas herramientas.
Hive y Spark son dos plataformas de análisis de datos muy diferentes, cada una con sus propias ventajas y desventajas. Hive es una herramienta de análisis de datos basada en SQL que se ejecuta en Hadoop y permite a los usuarios realizar consultas SQL en grandes conjuntos de datos almacenados en HDFS. Por otro lado, Spark es un motor de procesamiento de datos en tiempo real diseñado para el procesamiento rápido de grandes conjuntos de datos.
Algunas de las principales diferencias entre Hive y Spark incluyen:
- Velocidad: Spark es conocido por su rendimiento rápido y puede ser más adecuado para el procesamiento en tiempo real de grandes conjuntos de datos. En comparación, Hive puede ser más lento y menos adecuado para el procesamiento en tiempo real.
- Lenguajes de consulta: Hive utiliza SQL como lenguaje de consulta, mientras que Spark admite varios lenguajes de programación, como Python, R y Scala. Esto puede ser una ventaja para Spark, ya que permite a los usuarios elegir el lenguaje más adecuado para sus necesidades.
En general, es importante evaluar las necesidades y elegir la herramienta más adecuada para el contexto.
Apache Hive vs Apache Pig
Apache Hive y Apache Pig son dos componentes muy usados del ecosistema Hadoop. A veces son confundidos ya que pueden hacer cosas parecidas. Ambas tecnologías simplifican la escritura de programas MapReduce complejos, y ahorran a los usuarios la curva de aprendizaje que supone. Ambos utilizan un lenguaje similar a SQL para soportar operaciones de consulta de datos.
La diferencia principal es que Apache Hive utiliza SQL directamente, por lo que es más fácil de aprender para los profesionales habituados a las bases de datos. Aunque ambos soportan la creación de UDFs, es mucho más fácil su uso en Pig con Pig Latin.
Pig se utiliza principalmente para programar, mientras que Apache Hive es más usado por analistas de datos y en la creación de reportes e informes para crear informes y es el más utilizado por los analistas de datos.
| Apache Hive | Apache Pig | |
|---|---|---|
| Tipo de datos | Estructurados | Estructurados y semiestructurados |
| Lenguaje | HiveQL | Pig Latin |
| Particionado | Soporta particionado | No soporta particionado |
| Arquitectura | Opera en el servidor | Opera como un cliente |
| JDBC y ODBC | Soporta JDBC y ODBC | No soporta JDBC y ODBC |
Siguientes Pasos y Formación
A continuación, tienes los dos cursos de Udemy que te recomiendo para aprender más sobre Hive:

Aprendiendo Hive en el ecosistema de Apache Hadoop
En este curso para principiantes aprenderás a usar Hive desde cero. Instalarás la heramienta y trabajarás con consultas SQL para analizar datos.

Hive Básico a avanzado. Consultas en Hadoop
Aprende en este curso todos los conceptos clave de Apache Hive. Incluye también casos de uso que se suelen plantear en las entrevistas para determinar el conocimiento de esta tecnología.
También te dejo mis recomendaciones de los mejores libros en Amazon ¡Imprescindible para profesionales Big Data!
- Apache Hive Essentials
- Practical Hive: A Guide to Hadoop’s Data Warehouse System
- Apache Hive Cookbook
- Programming Hive
- The Ultimate Guide To Programming Apache Hive: A Reference Guide Document (Versión Kindle)
Preguntas Frecuentes Apache Hive – FAQ
¿Qué es Apache Hive?
Hive es una herramienta de Data Warehouse open source que funciona con Hadoop y permite consultar grandes cantidades de datos estructurados con un dialecto de SQL llamado HiveQL (HQL)
¿Cómo funciona Apache Hive?
Apache Hive transforma las sentencias del dialecto de SQL a trabajos MapReduce que ejecutan en un clúster Hadoop. Después devuelve los resultados al cliente.
¿Cómo se estructuran los datos en Apache Hive?
Los datos en Hive se almacenan en estructuras lógicas llamadas tablas. Las tablas se dividen en particiones y las particiones se dividen en Buckets.
¿Sigue siendo relevante Apache Hive?
Hive ha sido una herramienta popular para el análisis de datos en grandes empresas durante muchos años, y sigue siendo ampliamente utilizado en la actualidad.
Sin embargo, con el tiempo han surgido otras herramientas de análisis de datos que pueden ser más adecuadas para ciertos escenarios de uso. Por ejemplo, Apache Spark es un motor de procesamiento de datos en tiempo real que puede ser más rápido y eficiente para el procesamiento de grandes conjuntos de datos en comparación con Hive. Además, herramientas como Presto e Impala han surgido como opciones más modernas para el análisis de datos en Hadoop y pueden ofrecer un rendimiento superior en algunos casos.
En general, Hive sigue siendo una herramienta relevante para el análisis de datos en Hadoop, pero es importante evaluar las opciones disponibles y elegir la herramienta más adecuada para nuestras necesidades.
A continuación el vídeo-resumen. ¡No te lo pierdas!

Arquitecto de Datos con más de 10 años de experiencia en el sector del Big Data. Autor de cursos de formación en tecnologías Big Data, Cloud y Streaming completados por más de 7000 alumnos en Udemy y otras plataformas. Miembro de la Apache Software Foundation desde 2019.


