En esta entrada repasamos los aspectos clave de la herramienta de ETL para Big Data Apache NiFi.

Contenidos
¿Qué es Apache NiFi? Aspectos clave
Apache NiFi es un sistema distribuido dedicado a extraer, transformar y cargar datos (ETL). Es Open Source y está desarrollado y mantenido por la Apache Software Foundation.
En la web del proyecto podemos encontrar la siguiente definición:
An easy to use, powerful, and reliable system to process and distribute data.
NiFi (o Ni-Fi) ha sido diseñado para poder automatizar de una manera eficiente y visual los flujos de datos entre distintos sistemas: ingesta, enrutado y gestión. Para ello, cuenta con más de 300 conectores externos ya implementados y además es posible añadir conectores a medida.
Uno de los puntos fuertes de NiFi es la capacidad para programar flujos de datos arrastrando y conectando los componentes necesarios sobre los canvas de la web de administración. No es necesario por tanto tener conocimientos de programación específicos, sino entender y configurar correctamente cada uno de los componentes que se quieren usar.
Aunque se pueda considerar una herramienta ETL, NiFi no está realmente optimizado para realizar transformaciones de datos complejas o pesadas. Es posible realizar transformaciones de datos ligeras pero no es un motor de transformaciones batch completo. Aún así es común su uso integrado en sistemas Big Data, ya que ofrece muchas ventajas como herramienta de automatización de ingestas de datos y para realizar transformaciones y limpiezas sencillas.
Componentes principales de Apache NiFi
Componentes Básicos
Flow: El workflow o topología es la definición del flujo de datos que se implementa en NiFi e indica la forma en la que se deben gestionar los datos.
Flowfile: Es el paquete de datos que viaja por el flow entre los procesadores. Está compuesto por un puntero al propio dato útil o contenido (un array de bytes) y metadatos asociados llamados atributos. Los atributos pares clave-valor editables y NiFi los usa para enriquecer la información de provenance. Los metadatos más importantes son el identificador (uuid), el nombre del fichero (filename) y el path.
Para acelerar el rendimiento del sistema, el flowfile no contiene el propio dato, sino que apunta al dato en el almacenamiento local. Muchas de las operaciones que se realizan en NiFi no alteran el propio dato ni necesitan cargarlo en memoria. En concreto, el dato se encuentra en el llamado repositorio de contenido (Content Repository)

Processor: Los procesadores son los componentes principales de NiFi. Se encargan de ejecutar el proceso de extracción, transformación o carga de datos. NiFi permite realizar operaciones diversas en los processors, así como distribuir y programar su ejecución. Estos componentes también proporcionan una interfaz para acceder a los flowfiles y sus propiedades. Se pueden implementar nuevos processors personalizados mediante una api de programación en Java o bien usar los más de 280 processors existentes.
Los processors permiten abstraer la complejidad de la programación concurrente y pueden ejecutar en varios nodos de forma simultánea o bien en el nodo primario del clúster. Además, es posible programar su ejecución mediante cron, tiempo predefinido o mediante eventos de entrada. Los processors también tienen relaciones de salida (connections) en función de su comportamiento, por ejemplo éxito (success), fallo (failure) o reintento (retry). Llevan incorporado un validador de configuración y gráficas con las estadísticas de uso e indicadores de trazabilidad.
Componentes Avanzados
Connection: Son las tuberías de conexión entre dos Processors que les permiten interactuar. Es la encargada de transmitir los flowfiles entre los componentes y de gestionar las colas y su capacidad. Las conexiones actúan como un buffer para los flowfiles, y tienen un sistema de backpressure en función del número de eventos o del tamaño en disco. También es posible establecer la caducidad para los flowfiles o su prioridad. Mediante los funnels, NiFi permite agrupar varias conexiones en una.
Process Group: Agrupación de processors y connections para tratarlos como una unidad lógica independiente dentro del flujo de procesamiento. Para interactuar con el resto de componentes tienen puertos de entrada y de salida que gestionan el envío de flowfiles.
NiFi también incorpora los llamados Remote Process Groups (RPGs). Permiten tratar otra instancia o clúster externo de NiFi como un Process Group con el que interactuar. En vez de mover flowfiles entre diferentes process groups, se mueven entre distintos clústers. Los puertos de entrada y de salida actúan como puertas de entrada para los flowfiles.
Controller Service: Los controller service o controladores se utilizan para compartir un recurso entre distintos processors. Por ejemplo puede ser una conexión a una base de datos, a S3 o a un contenedor de Azure.
Apache NiFi también nos permite crear plantillas (templates) con un flow almacenado. Las plantillas resultan muy útiles para añadir de forma rápida un nuevo conjunto de componentes estándar o mover sub-flujos entre distintos entornos de trabajo.
Arquitectura de Apache NiFi
Apache NiFi es una aplicación Java que ejecuta en la JVM. En la imagen a continuación podemos ver los componentes más importantes de su arquitectura.
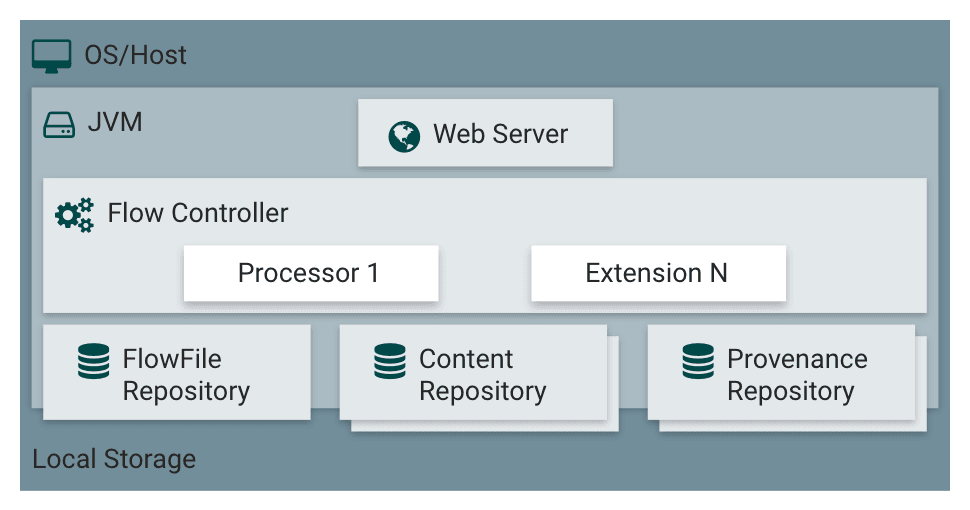
El Flowfile Repository o repositorio de flowfiles almacena los atributos y del estado de cada flujo del sistema, junto a las referencias al contenido. También almacena la cola en la que se encuentra en ese momento. Mantiene solamente el estado más actualizado del sistema mediante el Write-Ahead Log, lo que garantiza recuperar el estado más actualizado frente a una caía del sistema.
Los flowfiles se almacenan en un Hashmap en memoria. Cuando el número de flowfiles en esta estructura excede el establecido en la propiedad nifi.queue.swap.threshold, NiFi los escribe a un fichero swap en disco según su prioridad.
El Content Repository mantiene todo el contenido de los flowfiles. Cada vez que un dato se modifica se realiza una copia para no perder el original (copy on write). Pueden existir varios content repositories en un sistema, cada uno de ellos llamado contenedor y a su vez dividido en secciones.
Por último el Provenance Repository se encarga de almacenar la información de la procedencia y el origen de cada flowfile mediante snapshots a partir de los que se podría restaurar el ciclo de vida de cada uno. Este repositorio añade la dimensión del tiempo.
En los sistemas en los que NiFi tiene un volumen de datos muy alto, es posible que el content repository llene el disco, y en el caso de que el flowfile repository se encuentre en el mismo disco, podría corromper su contenido, por lo que es algo a tener en cuenta al diseñar la solución.
Streaming en NiFi
Para los casos de uso de Streaming, Apache NiFi es una tecnología con sus limitaciones. Por un lado, no está diseñado para realizar joins sobre flowfiles de manera eficiente ni agregaciones de datos en ventanas de procesamiento.
Una de las maneras de tratar los casos de uso de streaming es escribir los registros en un clúster de Apache Kafka. Una vez en Kafka, se podrán procesar fácilmente com Kafka Streams o Apache Flink.
NiFi Registry
Apache NiFi Registry es un subproyecto de Apache NiFi complementario enfocado en el almacenamiento de recursos compartidos en una localización centralizada. Su utilidad principal es el uso como repositorio de configuraciones.
Uno de los usos más comunes de NiFi Registry es almacenar y gestionar las versiones de los flujos en los llamados buckets, así como definir usuarios y permisos de acceso a estas configuraciones. De esta forma podremos tener mucho más control sobre los cambios que se producen en los flujos e incluso restaurar versiones anteriores con facilidad.
MiNiFi
Con la cantidad de dispositivos nuevos IoT y su crecimiento, existe la necesidad de recoger y trasladar los datos que generan a la nube para su explotación. Ingestar y validar estos datos supone un gran desafío en el que NiFi puede jugar un papel fundamental.
MiNiFi es el proyecto de NiFi para dispositivos de este tipo. Actúa como agente ligero que puede enviar datos a un sistema NiFi y realizar operaciones sencillas en el lugar en el que se generan los datos. Realiza una tarea complementaria con un consumo mínimo de recursos. Existen agentes en C++ y Java. El agente en C++ es más ligero en uso de memoria y disco pero no contiene todos los processors disponibles en la versión Java. Estos agentes garantizan la entrega de datos y la gestión de colas, buffers y backpressure.
Ejemplo de flujo en NiFi
En la imagen a continuación podemos ver un ejemplo de un flujo en Apache NiFi. Este flujo se compone de tres processors: GenerateFlowFile, PutFTP y PutFile.

También existen 3 conexiones, cada una de ellas se corresponde un un evento particular generado por el processor del que parte. Actúan de cola para los flowfiles generados.
El propósito del flujo es generar flowfiles aleatorios en el primer processor, escribirlos en un servidor FTP en el segundo processor, y en el caso de que esta escritura falle o sea rechazada, escribir los datos en el disco local mediante el processor PutFile. Esta última operación se reintentará en el caso de fallo de la escritura.
Monitorización en Apache NiFi
La monitorización de instancias de Apache NiFi y de sus flujos de datos es fundamental para tener visibilidad del proceso y de sus posibles errores. NiFi aporta varias capacidades de monitorización integradas en la plataforma y también la posibilidad de exportar datos hacia sistemas externos.
Una forma de hacer esto, es usando en endpoint que proporciona NiFi para Prometheus. Esto permite exportar los datos de monitorización de las instancias y sus flujos para crear dashboards completos.
NiFi también permite crear reporting tasks desde su interfaz gráfica. Las reporting tasks pueden ser de muchos tipos, por ejemplo para Prometheus o de tipo Query SQL. Con esta última, podremos realizar consultas SQL a los datos de monitorización internos almacenados por NiFi y definir los sistemas en los que terminan las métricas como puede ser una base de datos, Apache Kafka o Flink para generar alertas en tiempo real.
Por otro lado, NiFi también almacena de forma persistente la información de estado y el rendimiento de sus nodos.
Ventajas
- Facilidad de uso mediante UI
- Escalable horizontalmente
- Gran cantidad de componentes out-of-the-box (processors y conectores)
- Es posible implementar nuevos componentes y procesadores (programando con la API de Java)
- Se encuentra en constante evolución y con una gran comunidad
- Incorpora auditoría del dato
- Tiene integrada la validación de configuraciones
- Política de Usuarios (LDAP)
- Software multiplataforma
- Linaje de datos integrada, de cara a cumplir regulaciones.
- Uso para enrutar mensajes a microservicios
- Integrado en Cloudera Data Platform (CDP) – Cloudera Flow Management (CDF)
Inconvenientes
- Las versiones por debajo de 1.x no disponen de HA
- Consumo de recursos de hardware muy elevado en función de la carga de procesamiento
- Otras herramientas como Apache Flume son más ligeras y adecuadas para realizar transformaciones de datos simples
Alternativas a Apache NiFi
Existen alternativas a Apache NiFi como soluciones para gestionar dataflows, cada una con sus particularidades:
- Streamsets
- Azure Data Factory
- AWS Data Pipeline
Mucha gente se pregunta el motivo de usar NiFi cuando ya se está usando Apache Kafka como punto de entrada al sistema de datos. Debemos tener en cuenta que Kafka está diseñado para casos de uso de streaming y manejar ficheros de datos pequeños.
NiFi puede manejar ficheros de datos mucho más grandes que Apache Kafka. Además, NiFi proporciona una interfaz muy potente que permite controlar y administrar las operaciones de ingesta y de transformación de forma sencilla y centralizada. También debemos tener en cuenta la gran cantidad de conectores y procesadores que aporta NiFi, por lo que ambas tecnologías son complementarias.
Curso recomendado de Apache NiFi: Siguientes Pasos
Aprende Apache NiFi a fondo con mi curso desde cero. Al final del curso, serás capaz de diseñar e implementar perfectamente tus propias pipelines de movimiento, transformación de datos y sistemas de ingesta con Apache NiFi
El curso te enseñará a desenvolverte con esta tecnología en un entorno profesional e implementar soluciones que manejen datos en muy poco tiempo. Cubre desde los conceptos teóricos más básicos como su funcionamiento y componentes hasta la implementación de flujos de datos complejos y un proyecto práctico guiándote paso a paso. ¡Aquí abajo tienes un enlace con el cupón!
Apache NiFi desde cero: La guía esencial
Artículo recomendado: Seguridad en Apache NiFi
Preguntas Frecuentes de Apache NiFi – FAQ
¿Para qué se usa Apache NiFi?
Apache NiFi es una herramienta open source para integrar y automatizar flujos de datos. Permite realizar operaciones de transformación, extracción y carga sobre grandes cantidades de datos con gran flexibilidad y de una manera visual.
¿Es Apache NiFi una herramienta ETL?
Apache NiFi se puede considerar una herramienta de ETL o formar parte de un sistema más complejo. Sin embargo, NiFi no está optimizado para realizar transformaciones de datos muy complejas y pesadas de tipo batch.
¿Qué es un flow file en Apache NiFi?
Un flow file en NiFi es un contenedor de datos que viaja por el flujo. Se compone de la carga útil (dato) y los metadatos asociados llamados atributos editables que soportan las operaciones de NiFi.
¿Qué es un procesador en Apache NiFi?
Un procesador o processor de NiFi es el componente encargado de ejecutar alguna acción sobre los datos o el flujo. Proporcionan la interfaz para acceder a los flow files y sus contenidos.
¿Cuál es la diferencia entre NiFi y MiNiFi?
MiNiFi son los agentes de NiFi que se colocan cerca de las fuentes de datos (en localizaciones remotas). Tienen un conjunto de procesadores reducido y menos consumo de recursos que NiFi.
A continuación el vídeo-resumen en español. ¡No te lo pierdas!

Arquitecto de Datos con más de 10 años de experiencia en el sector del Big Data. Autor de cursos de formación en tecnologías Big Data, Cloud y Streaming completados por más de 7000 alumnos en Udemy y otras plataformas. Miembro de la Apache Software Foundation desde 2019.



Si bien se establecen «desventajas» cuales serían las funcionalidades que podría tener Nifi para ser más completo?
NiFi es una herramienta modular, que depende de la implementación de los procesadores. Para determinar si NiFi es una tecnología adecuada para nuestro caso de uso debemos analizar si cuenta con procesadores y conectores desarrollados, mantenidos y actualizados para interactuar con los sistemas que nos interesan