En esta entrada realizamos una introducción a Apache Flume y repasamos sus aspectos clave. En qué consiste esta herramienta de ingesta Big Data y su arquitectura.

Contenidos
Aspectos clave de Apache Flume
Apache Flume es una herramienta de software distribuida y open source. Se encarga de recopilar, agregar y mover datos desde diversas fuentes hasta almacenamientos de datos.
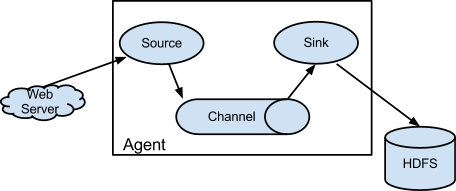
En el esquema podemos observar que el agente de Flume se compone de tres piezas: Source, Channel y Sink. Como ejemplo, los datos son recibidos en el sistema de un servidor web externo con la finalidad de escribirlos en HDFS (Hadoop Distributed File System) como almacenamiento persistente distribuido.
Componentes de Apache Flume
A continuación, listamos los componentes más importantes:
- Evento: Son las unidades de datos transportadas por el agente de Flume. Implementado como un array de bytes.
- Agente: Contenedor para alojar subcomponentes que permiten mover los eventos.
- Source: Receptor de eventos
- Interceptor: Transformador de eventos
- Channel: Buffer de eventos
- Sink: Toma eventos del canal y los transmite hacia el siguiente componente
Apache Flume proporciona componentes específicos que incluye en su distribución de modo nativo para interaccionar con otros sistemas. A continuación, se listan algunos de los más conocidos:
- Source Spool-dir directory
- Syslog Source
- Apache Kafka Sink
- Timestamp Interceptor
- Morphline Interceptor
En Flume los mensajes pueden llegar duplicados pero nunca perderse. A esta propiedad o garantía de entrega se le denomina at-least-once delivery.
Cursos Recomendados de Apache Flume
Te recomiendo estos curso en Udemy para familiarizarte con las herramientas de ingesta en Hadoop que te resultarán muy útiles:

Flume y Sqoop para ingestas Big Data
En este curso aprenderás a importar datos a través de ejemplos prácticos en HDFS, Hive y HBase de múltiples fuentes con la ayuda de Flume y Sqoop.

Big Data con Spark, Hadoop, Sqoop, Hive y Flume
En este curso podrás aprender herramientas básicas en big data como Hadoop, Spark, Sqoop y Flume desde cero. Te lo recomiendo como curso de iniciación si pretendes trabajar con este stack.
Preguntas Frecuentes Flume – FAQ
¿Para qué se usa Apache Flume?
Flume es una herramienta Big Data usada para mover y agregar datos desde diversas fuentes hacia almacenamientos de datos centralizados
¿Qué diferencias existen entre Apache Flume y Apache Kafka?
Aunque ambos sistemas son muy versátiles, Apache Kafka se usa más frecuentemente como broker de mensajería en streaming. Flume, por otra parte, se usa en entornos Hadoop y Big Data para ingestar y agregar grandes cantidades de datos hacia un almacenamiento centralizado.
A continuación el vídeo-resumen. ¡No te lo pierdas!

Arquitecto de Datos con más de 10 años de experiencia en el sector del Big Data. Autor de cursos de formación en tecnologías Big Data, Cloud y Streaming completados por más de 7000 alumnos en Udemy y otras plataformas. Miembro de la Apache Software Foundation desde 2019.


