En esta entrada vamos a explicar en qué consiste HDFS, el sistema de ficheros distribuido de Hadoop. Cuales son sus aplicaciones y funcionamiento para almacenar grandes cantidades de datos para Big Data.

En estos artículos tenemos la introducción a los otros dos componentes de Apache Hadoop:
Contenidos
Introducción a HDFS
HDFS (Hadoop Distributed File System) es el componente principal del ecosistema Hadoop. Esta pieza hace posible almacenar data sets masivos con tipos de datos estructurados, semi-estructurados y no estructurados como imágenes, vídeo, datos de sensores, etc. Está optimizado para almacenar grandes cantidades de datos y mantener varias copias para garantizar una alta disponibilidad y la tolerancia a fallos. Con todo esto, HDFS es una tecnología fundamental para Big Data, o dicho de otra forma, es el Big Data File System o almacenamiento Big Data por excelencia.
Es un sistema distribuido basado en Java que permite obtener una visión de los recursos como una sola unidad. Para ello crea una capa de abstracción como un sistema de ficheros único. HDFS se encarga de almacenar los datos en varios nodos manteniendo sus metadatos. Distribuir los datos en varios nodos de almacenamiento aumenta la velocidad de procesamiento, el paralelismo en las operaciones y permite la replicación de los datos.
Está basado en la idea de que mover el procesamiento es mucho más rápido, fácil y eficiente que mover grandes cantidades de datos, que pueden producir altas latencias y congestión en la red. HDFS proporciona a las aplicaciones la capacidad de acceder a los datos en el lugar en el que se encuentren almacenados.
Historia de HDFS
En el año 2006, Hadoop MapReduce y HDFS se cedieron a la Apache Software Foundation como proyecto open source. Esto impulsó su adopción como herramienta Big Data en proyectos de analítica en muchas industrias.
La versión 1.0 de Hadoop fue publicada en el año 2012. La versión 2.0 se publicó en el año 2013 añadiendo YARN como gestor de recursos y desacoplando HDFS de MapReduce. En el año 2017 se publicó Hadoop 3.0, añadiendo la posibilidad de añadir NameNodes adicionales y mejoras en la compresión de datos.
Características
En HDFS, los ficheros que se almacenan son divididos en bloques de un mismo tamaño (128 MB) y estos se distribuyen en los nodos que forman el clúster. Esta característica hace que el sistema de ficheros no funcione de forma óptima con ficheros pequeños, por lo que deben evitarse. El tamaño de bloque es configurable.

Para conseguir una alta escalabilidad, HDFS usa almacenamiento local que escala horizontalmente. Aumentar el espacio de almacenamiento solamente supone añadir discos duros a nodos existentes o añadir más nodos al sistema. Estos servidores tienen un coste reducido, al tratarse de hardware básico con almacenamiento conectado. HDFS soporta miles de nodos, lo más típico en un cluster es desplegar decenas o cientos de nodos y manejar cientos de terabytes, con la capacidad de escalar a decenas de petabytes
Para mantener la integridad de los datos, HDFS almacena por defecto 3 copias de cada bloque de datos. Esto significa que el espacio necesario en HDFS es el triple, por lo que el coste también aumenta. Aunque la replicación de datos no es necesaria para el funcionamiento de HDFS, almacenar solamente una copia podría suponer pérdida de datos frente a fallos o corrupción de ficheros, eliminando la durabilidad del dato.
¿Quieres Convertirte en Ingeniero de Datos?
El sistema de ficheros en HDFS es jerárquico, como ocurre en otros sistemas de ficheros. El usuario o aplicación debe crear primero un directorio, dentro del cual se podrán crear, eliminar, mover o renombrar ficheros. HDFS proporciona una herramienta por línea de comandos (CLI) para interaccionar con el sistema de ficheros. Aquí tienes una entrada con los comandos más usados de HDFS.
Arquitectura y componentes de HDFS
La arquitectura de HDFS es de tipo maestro-esclavo. Esta basada en dos componentes principales: NameNodes y DataNodes.
NameNode
El NameNode (NN) es el maestro o nodo principal del sistema. No se encarga de almacenar los datos en sí, sino de gestionar su acceso y almacenar sus metadatos. Se asemeja a una tabla de contenidos, en la que se asignan bloques de datos a DataNodes. Debido a esto, necesita menos espacio de disco pero más recursos computacionales (memoria y CPU) que los DataNodes.
Este componente es único nodo que conoce la lista de ficheros y directorios del clúster. El sistema de ficheros no se puede usar sin el NameNode. En Hadoop 2 se introduce el concepto de alta disponibilidad, evitando que exista un único punto de fallo en el sistema.
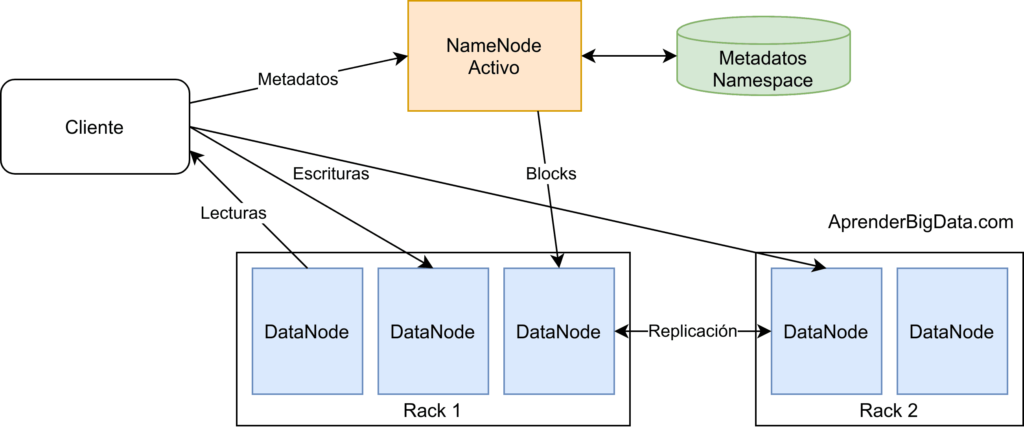
Para conseguirlo, HDFS se puede configurar para que exista un NameNode primario activo y un NameNode secundario en espera (o más de uno a partir de Hadoop 3) que actúa como esclavo. Este último toma el control y responde a las peticiones de los clientes si se detecta algún fallo o el nodo primario deja de estar disponible.
Estos nodos deben estar sincronizados y tener los mismos metadatos almacenados. Existen dos mecanismos para conseguir esta sincronización:
El primer mecanismo es el más común y hace uso de Quorum Journal Nodes (QJM). Los Journal Nodes son demonios ligeros separados que se sincronizan entre ellos. Generalmente existen 3 por cada clúster. El NameNode activo escribe su log en la mayoría de los Journal y el nodo en espera lee los cambios y los aplica a su namespace. Los Journal solamente permiten que exista un NameNode que escriba en su log. En el caso de fallo del NN primario, el NN secundario lee todos los cambios del Journal y después toma el rol de primario.
El segundo mecanismo consiste en usar un almacenamiento compartido entre los NameNodes, sobre el que se escribe el log de cambios.
DataNode
Los DataNodes (DN) se corresponden con los nodos del clúster que almacenan los datos. Se encarga de gestionar el almacenamiento del nodo. Generalmente usan hardware básico con varios discos y una gran capacidad. A causa de su tipología, permiten aumentar la capacidad del sistema de una forma horizontal de forma efectiva y con un coste reducido.
Funcionamiento
HDFS tiene un modelo Write once read many. Significa que no se pueden editar ficheros almacenados HDFS, pero sí se pueden añadir datos. Antes de poder usar HDFS, debemos formatear el NameNode con el comando hdfs namenode -format.
En las operaciones de escritura, el cliente debe comunicar la instrucción previamente al NameNode. El NameNode comprueba los permisos y responde entonces al cliente con la dirección de los DataNodes en los que el cliente deberá empezar a escribir. El primer DataNode copiará el bloque a otro DataNode, que entonces lo copiará a un tercero. Una vez que se han completado estas réplicas se enviará al cliente la confirmación de escritura.
En las operaciones de lectura, el cliente pide al NameNode la localización de un fichero. Una vez que se han comprobado los permisos del cliente, el NameNode envía la localización de los DataNodes que contienen los bloques que componen el fichero al cliente. También envía un token de seguridad que usará en los DataNodes como autenticación.
Por ejemplo, para escribir un fichero en HDFS se puede hacer con la opción -put del comando de terminal. Como ejemplos de operaciones de lectura de ficheros tenemos las opciones -get, -cat o -text. Para hacer referencia al sistema de ficheros de HDFS, generalmente deberemos usar una ruta que comience con hdfs://.
Seguridad en HDFS
Por defecto, HDFS no proporciona ningún mecanismo de seguridad potente. Debemos tener esto en cuenta para implementar nuestra solución en entornos reales. A continuación tienes un resumen de los componentes más importantes. Puedes aprender más en detalle en el artículo de Seguridad en Hadoop y Cloudera.
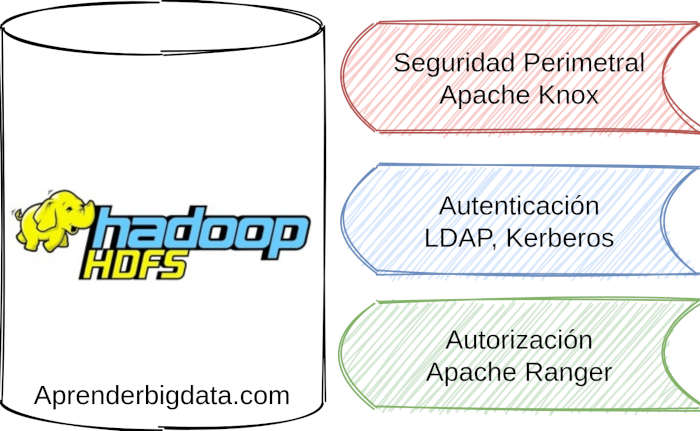
- Apache Knox es un servicio que nos proporciona un punto de acceso único a nuestros clusters de Hadoop para las peticiones REST y HTTP de acceso a los datos y a las ejecuciones de trabajos. Actúa como la seguridad perimetral. Además, tendremos que considerar la implementación de firewalls para aumentar la seguridad.
- LDAP: Para hacer más seguras las operaciones de lectura y de escritura sobre nuestros datos debemos tener integrado un mecanismo de autenticación y de autorización como LDAP en todos nuestros nodos. LDAP actúa como un repositorio central con la información de los usuarios. Antes de consultar o procesar los datos, los usuarios deben autenticarse contra el servidor de LDAP.
- Kerberos: Kerberos es un protocolo de autenticación para las aplicaciones de tipo cliente-servidor. El servidor de Kerberos o KDC verifica las identidades para las peticiones que se realizan a nuestro clúster y almacena los principals.
- Apache Ranger: Ranger actúa como punto central de gestión de accesos, políticas y seguridad de nuestros servicios. Nos permite implementar requisitos de seguridad y gobierno de datos a través de su interfaz gráfica o de su API REST. Se puede usar como mecanismo de autorización común sobre todos los componentes de Hadoop. También, proporciona enmascaramientro de datos para proteger información sensible.
Siguientes Pasos y Cursos de HDFS
Aquí tienes dos cursos muy recomendados con los que consolidarás conceptos fundamentales para convertirte en experto de estas tecnologías fundamentales para los ingenieros de datos. Aprenderás a trabajar desde cero con Hadoop en proyectos big data con todos sus componentes para implementar soluciones completas.
Curso completo de la Plataforma Hadoop
Aprende Hadoop a fondo con este. Está disponible en Coursera y ofrecido por la Universidad de San Diego. Con este curso aprenderás los conceptos clave de Hadoop MapReduce. La ventaja es que podrás ir al ritmo que consideres adecuado, tanto en las clases de teoría como en los ejercicios y laboratorios que tendrás disponibles. Se divide en 4 módulos con 26 horas de contenido que ya han cursado más de 140000 estudiantes.
- Fundamentos de Hadoop
- Stack de Hadoop
- HDFS
- MapReduce
- Apache Spark

Introducción a Big Data con Hadoop y Spark
En este curso ofrecido por IBM en Coursera podrás aprender a implementar un proyecto big data con Hadoop y Apache Spark. Cuenta con más de 11 horas de contenido y más de 6000 estudiantes. Se divide en 6 módulos:
- Qué es Big Data
- Introducción al ecosistema Hadoop
- Apache Spark
- Dataframes y Spark SQL
- Desarrollo y Runtime
- Monitorización y configuración
También, te recomiendo leer el siguiente libro:
Preguntas Frecuentes HDFS – FAQ
¿Para qué se usa HDFS?
HDFS es una tecnología de almacenamiento distribuida. Es muy usada en sistemas Big Data, ya que permite replicar los datos, escalar horizontalmente y distribuir los datos para realizar procesamiento con el framework de Hadoop.
¿En qué se diferencia HDFS de Hadoop?
HDFS es el componente de Hadoop encargado de almacenar los datos en un sistema de ficheros distribuido. Hadoop es un framework de procesamiento distribuido de Big Data.
¿Cómo se almacenan los datos en HDFS?
HDFS divide los ficheros de datos en bloques, generalmente de 128MB de tamaño, estos bloques son replicados y distribuidos en los nodos que componen el clúster.
¿Qué componentes tiene HDFS?
HDFS tiene dos componentes principales: NameNode y DataNode. Los NameNodes son los encargados de almacenar los metadatos y la localización de los bloques que componen cada fichero. Los DataNodes se encargan de almacenar los datos y gestionar los discos.
A continuación, el vídeo-resumen. ¡No te lo pierdas!

Arquitecto de Datos con más de 10 años de experiencia en el sector del Big Data. Autor de cursos de formación en tecnologías Big Data, Cloud y Streaming completados por más de 7000 alumnos en Udemy y otras plataformas. Miembro de la Apache Software Foundation desde 2019.


