En el siguiente artículo realizamos una comparativa de las herramientas ETL empresariales más usadas y comparamos sus pros y contras para tomar la mejor decisión informada al elegir una herramienta para un proyecto Big Data.

Explicamos brevemente en qué consiste una herramienta ETL y las consideraciones que se deben tener en cuenta para elegir una herramienta ETL para un proyecto.
Contenidos
¿Qué son las herramientas ETL?
Las herramientas de tipo ETL: Extract, Transform, Load son un componente esencial para data warehousing y analítica y se encargan de asegurar la integración de datos entre bases de datos y aplicaciones mediante los siguientes pasos:
- Los datos se descargan en el formato adecuado para su análisis
- Los datos se enriquecen con información adicional
- Se registra y documenta su origen (provenance)

Para ello, podemos dividir el flujo en las siguientes funciones o fases:
1. Extracción
La fase de extracción consiste en la recuperación de información de varios sistemas de origen, como pueden ser RDBMS en forma de tabla o bien en formato JSON o XML, etc. Las fuentes de datos pueden ser muy variadas, como bases de datos relacionales o no relacionales, ficheros, aplicaciones SaaS, CRMs, ERPs, APIs, páginas web o sistemas de logs.
2. Transformación
Esta fase involucra varios procesos, con los que los datos extraídos validan o se transforman en un formato útil o fácil de entender. Por ejemplo, puede consistir en alguno de las siguientes acciones:
- Eliminar las entradas duplicadas, incompletas, incorrectas o expiradas (deduplicación, normalización)
- Eliminar los campos innecesarios de los registros
- Realizar un filtrado y una validación de los datos
- Reordenar los datos no estructurados en datos estructurados
- Unir los datos de diferentes fuentes con operaciones JOIN
3. Carga
Esta es la fase final del proceso ETL en la cual los datos se cargan en un almacén de datos. Existen dos tipos de cargas:
- Carga completa: Todos los datos se mueven al almacén al mismo tiempo.
- Incremental: El movimiento de datos se produce en lotes, con una velocidad de refresco.
Como vemos en la imagen del Workflow de una ETL, generalmente se comienza extrayendo datos de bases de datos relacionales o ficheros, en la imagen se incluyen bases de datos relacionales como SQL Server, DB2 u Oracle, así como ficheros planos.
Debido a la disparidad de estos datos, la siguiente fase es la de transformación, en la cual se realizan las operaciones necesarias para homogeneizar los datos y prepararlos para almacenarlos en un Data Mart. Para realizar estas transformaciones, es frecuente apoyarse en un Data Warehouse que almacena datos con diversas características, como puede ser Amazon Redshift.
Existe también otro tipo de procesos llamado ELT que permite afrontar este problema con otras particularidades. Te recomiendo leer el artículo sobre la diferencia entre los procesos ETL y ELT.
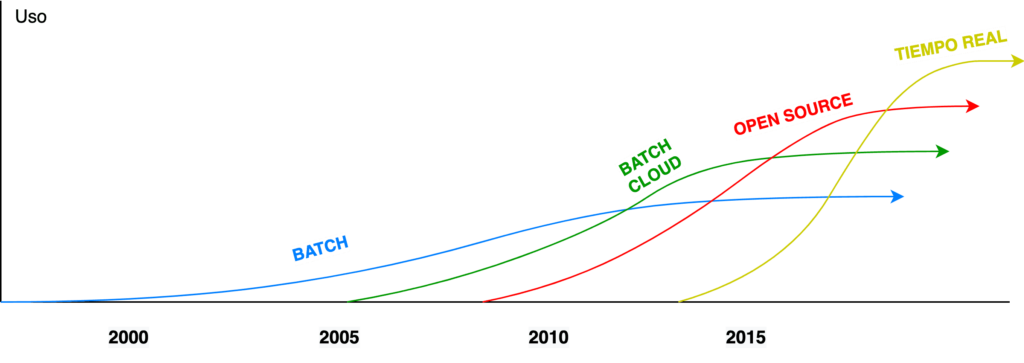
En los últimos años se han popularizado las herramientas ETL para tiempo real o streaming frente a los procesos de tipo Batch. Los casos de uso que requieren bajas latencias y obtener información de valor lo más rápido posible han aumentado mucho con los dispositivos IoT para Big Data y el enfoque hacia mejorar la experiencia de usuario.
Herramientas ETL más usadas – Pros y Contras
A continuación analizamos cada una de las siguientes tecnologías ETL o de integración de datos, con los pros y contras más importantes para ayudarte a tomar una decisión acertada y conocer las alternativas disponibles en el mercado.
Apache NiFi
Apache NiFi es una herramienta gratuita y open source mantenida y desarrollada por la Apache Software Foundation. Permite definir flujos o topologías de una forma visual, muy sencilla e intuitiva a la vez que flexible para ETLs. Las unidades de procesamiento o carga de datos se denominan processors y se pueden extender con funcionalidad personalizada.
Pros:
- Licencia Apache 2.0
- Concepto de programación de flujo de datos
- Integración con Data Provenance y auditoría
- Posibilidad de manejar datos binarios
- Componentes disponibles
- Interfaz de usuario simple con grafos visuales
- Política de Usuarios (LDAP)
Contras:
- Falta de estadísticas por registro procesado
- Consumo de recursos elevado
Streamsets
Streamsets es una plataforma empresarial centrada en construir y ejecutar procesos batch y flujos de datos en streaming. Se puede desplegar on premise y en cloud y está preparada para escalar cómodamente. Streamsets se divide en varios componentes que se pueden configurar y desplegar por separado.
Pros:
- Estadísticas individuales por registro
- Visualización pensada para realizar debugging
- Interfaz de usuario atractiva
- Facilidades para streaming
Contras:
- No existe configuración JDBC reutilizable
- Los cambios de configuración en el procesador requieren detener todo el flujo de datos
Apache Airflow
Apache Airflow es una plataforma gratuita y open source para crear, programar y monitorizar flujos de trabajo. Está basada en Python, el lenguaje con el que se definen los trabajos, y es compatible con gestores de recursos como Mesos y Yarn.
Pros:
- Visualización clara
- Interfaz fácil de usar
- Solución escalable
Contras:
- No es adecuado para streaming
- Requiere añadir operadores adicionales
AWS Data Pipeline
AWS Data Pipeline es la solución propuesta por la cloud de Amazon Web Services para transferir y transformar datos en la nube. Esta solución no es gratuita y Amazon cobra por uso. Permite realizar transformaciones de datos sencillas y se integra con buena parte de las tecnologías y servicios de Amazon en la nube.
Pros:
- Facilidad de uso
- Flexibilidad
- Precio razonable
Contras:
- Falta integración de funciones
AWS Glue
AWS Glue es el servicio de Amazon en la nube para realizar ETL orientado a Big Data. Se encarga de administrar y ejecutar los trabajos ETL definidos por el usuario, así como escalar de forma automática los recursos necesarios. Usa Scala o Python para definir las extracciones y las transformaciones de datos.
Pros:
- Soporta numerosas fuentes de datos
- Integración con los servicios y el ecosistema de AWS
- Servicio serverless
Contras:
- Cantidad de acciones y de trabajo manual
- Poca flexibilidad, orientado a usuarios de AWS
Talend
Talend es una solución ETL empresarial open source. Contiene integraciones listas para usar con numerosas herramientas y tecnologías en cloud y on-premise. Su versión de pago ofrece componentes adicionales alrededor del gobierno del dato y gestión e incorpora la monitorización de los procesos de integración del dato y ETL. Permite descubrir fácilmente datos y relaciones. El cuadrante de Gartner para herramientas de integración de datos le asigna la categoría de líder.
Pros:
- Gran cantidad de integración con tecnologías externas listas para usar
- Versión open source gratuita disponible
- Interfaz sencilla con funcionalidad de arrastrar y soltar
- Extensible fácilmente con scripts y librerías en Java
Contras:
- Es posible que sean necesarios perfiles expertos en java para crear elementos ad-hoc
Informatica PowerCenter
Este producto de la empresa Informatica ha sido desarrollado como una solución empresarial para la integración del dato. Para su uso, es necesaria una licencia comercial y soporta su despliegue en clouds de AWS y Azure.
Pros:
- Abundante documentación y formación
- Facilidad de uso para gente no técnica ejecutando trabajos
- Buena herramienta para integrar procesos de inteligencia artificial
- Buena Madurez y rendimiento
Contras:
- Necesidad de licencia comercial con precio elevado
- Curva de aprendizaje más elevada que otras herramientas
- Integración
Ab Initio
Ab Initio es una herramienta especializada en la integración del dato y procesamiento de grandes volúmenes de datos con varias estrategias.
Pros:
- Facilidad de gestión de grandes volúmenes de datos con optimización del procesamiento
- Buena integración con plataformas Mainframe
Contras:
- Precio elevado
- Documentación de difícil acceso
- Solución realmente eficiente a partir de grandes volúmenes de datos y en grandes entornos empresariales
Pentaho
Pentaho es la herramienta ofrecida por la empresa Hitachi para procesos ETL empresariales. Ofrece Pentaho Data Integration (PDI), también llamada Kettle para realizar transformaciones y migraciones de datos entre aplicaciones. Tiene versiones enterprise y open source (community edition). En la versión empresarial, la herramienta añade componentes adicionales a su catálogo.
Pros:
- Interfaz gráfica intuitiva y fácil de usar (arrastrar y soltar)
- Versión gratuita (community edition)
Contras:
- Plantillas limitadas
Azure Data Factory
Azure Data Factory es el servicio cloud para ETLs en la nube de Azure. Tiene una interfaz de usuario que permite implementar flujos de datos, ETL y ELT sin la necesidad de usar código.
Pros:
- Integración con servicios de Azure
- Evita mantener infraestructura y su sobrecoste
¿Quieres Convertirte en Ingeniero de Datos?
Otras herramientas a considerar:
Entre los software ETL, también tenemos alternativas menos populares pero que debemos considerar como las siguientes: Oracle Data Integrator (ODI), Xplenty, Striim, Fivetran, Stitch, Alooma, Skyvia, Panoply, Hevo Data, Matillion, FlyData (Amazon Redshift), Bluemetrix, Apache Hop.
Cómo elegir una Herramienta ETL para Big Data
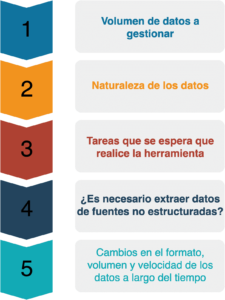
A continuación se incluye la lista de parámetros a considerar al elegir una herramienta ETL para big Data.
1. Volumen de datos a gestionar
¿La herramienta está diseñada para la recuperación de datos desde una única fuente o desde múltiples fuentes? Las herramientas utilizadas para la recuperación de datos de una sola fuente difieren de las diseñadas para la recuperación de datos de múltiples fuentes.
2. Naturaleza de los datos
Los datos pueden ser estructurados y no estructurados y provenir de diversas fuentes.
En ocasiones, los datos deben procesarse en un formato que sea uniforme y comprensible para las herramientas analíticas.
También se debe verificar si la herramienta ETL tiene la capacidad de transformar un tipo particular de datos producidos por otras herramientas en la organización.
3. Tareas que se espera que realice la herramienta
¿De qué sistemas recuperará los datos y dónde se entregarán?
Se debe comprender el tipo de datos que se espera que la herramienta recupere y procese, así como el punto final de entrega para todo el proceso ETL.
4. Consideraciones adicionales
- Evaluar si es necesario extraer datos de fuentes no estructuradas como por ejemplo páginas web, email, etc.
- Forma de gestionar la pérdida o indisponibilidad de datos durante la extracción.
- Cambios en los formatos de datos.
- Aumento en el volumen y en la velocidad de los datos a lo largo del tiempo.
- Coste de la herramienta en el tiempo y posibles ampliaciones futuras.
Siguientes Pasos con ETL
En mi opinión, estos son los tres mejores cursos para aprender acerca de procesos ETL, en qué consisten, cómo implementar y sacar partido a sus ventajas y las mejores herramientas en el mercado. Te darán todo el conocimiento teórico y práctico que necesitarás para implementar procesos ETL en tu entorno de data warehouse y big data:
Paso 1:

Apache NiFi desde cero: La guía esencial
Al final de este curso de Apache NiFi, serás capaz de diseñar e implementar perfectamente tus propias pipelines de movimiento, transformación de datos y sistemas de ingesta. Aprenderás a desenvolverte en un entorno profesional e implementar soluciones que manejen datos en muy poco tiempo y paso a paso.
Paso 2:

Fundaciones de ETL para ETL en entornos Data Warehouse
Este curso disponible en Coursera y ofrecido por IBM es la especialización en fundamentos de BI con SQL, ETLs y Data Warehouse. Consta de 4 módulos: Linux y Scripting, Bases de datos y SQL para Data Science con Python, ETL y Pipelines de datos con Shell, Airflow y Kafka y por último Data Warehousing y Analítica BI.
Paso 3:

Testing de ETL: De principiante a experto
Este curso te resultará muy util para aprender los mecanismos de testing que existen para herramientas ETL, entender los escenarios y profundizar en tu conocimiento.
Preguntas Frecuentes
¿Cuál es la función principal de las herramientas ETL?
La función principal de las herramientas ETL es automatizar el proceso de extracción de datos de diferentes fuentes, transformarlos para cumplir con los requisitos del análisis de datos y cargarlos en un destino, como un data warehouse o un sistema de análisis.
¿Qué es el "data wrangling" y cómo se relaciona con ETL?
El «data wrangling» es el proceso de limpiar y transformar datos brutos en un formato utilizable para el análisis. Se relaciona con ETL porque ambos procesos implican la transformación de datos. Sin embargo, el data wrangling suele ser más flexible y ad hoc, mientras que ETL es más estructurado y automatizado.
¿Qué es un workflow en el contexto de ETL?
Un workflow en el contexto de ETL es una secuencia de tareas automatizadas que define el proceso completo de extracción, transformación y carga de datos. Los workflows permiten la automatización, repetición y gestión de los procesos ETL, asegurando que los datos sean procesados de manera eficiente y consistente.
A continuación el vídeo-resumen. ¡No te lo pierdas!
ETL y Big Data: Qué es en 1 minuto

Arquitecto de Datos con más de 10 años de experiencia en el sector del Big Data. Autor de cursos de formación en tecnologías Big Data, Cloud y Streaming completados por más de 7000 alumnos en Udemy y otras plataformas. Miembro de la Apache Software Foundation desde 2019.


![Lee más sobre el artículo Mejores Cursos de Oracle Online [Actualizado]](https://aprenderbigdata.com/wp-content/uploads/Cursos-online-Oracle-300x169.jpg)
Que ETL usar para datos espaciales
Que ETL usar para datos geograficos
Echo de menos Cloud Data Integrator dentro de IICS
MUY BUENA INFORMACION