Recientemente se ha publicado la nueva versión de Apache Spark 3.0. En esta entrada, repasamos algunos de los cambios y mejoras más destacados en esta versión respecto a Spark 2.

Contenidos
Apache Spark 3
La versión de Apache Spark 3.0.0 se ha publicado oficialmente el 18 de junio del 2020. A partir de esta fecha, cualquiera puede usar esta nueva versión del framework de procesamiento open source más popular en Big Data. Este lanzamiento ha incorporado la resolución de más de 3400 tickets con contribuciones de 440 committers.
A modo de recordatorio, comentar que Apache Spark es un framework de procesamiento de datos en memoria distribuido y tolerante a fallos. Además de procesamiento batch, también incorpora capacidades de stream processing y librerías de machine learning. La realidad es que desde su versión inicial en 2010, Apache Spark se ha convertido en el framework más usado para construir pipelines de datos sobre Data Lakes.
Spark 3 ya se encuentra disponible en la plataforma de Databricks versión 7 y es cuestión de tiempo que se integre en otras distribuciones como Cloudera o en servicios de proveedores cloud como AWS o Azure.
Además, algunas pruebas de rendimiento reportan una mejora de velocidad de 2x respecto a la versión anterior: Spark 2.4, debido a las optimizaciones incorporadas.
Cambios destacados
Para empezar, esta versión de Spark añade soporte para Java 11 (SPARK-24417) y para Hadoop 3 (SPARK-23534), eliminando el soporte para la versión anterior: Hadoop 2.6.
También, se ha convertido en una práctica común exportar las métricas de Spark asociadas a la JVM y el GC a sistemas externos como Prometheus. En esta versión se soporta la monitorización con Prometheus mediante un endpoint nativo (SPARK-29429) simplemente activando una configuración. De esta forma, se facilita la generación de alertas en nuestros sistemas.
Apache Spark también sigue avanzando en su compatibilidad con Kubernetes y en esta versión añade soporte para Kerberos (SPARK-23257).
Por último, varios cambios afectan al rendimiento de Spark en analítica avanzada. Entre ellos se encuentran la optimización de consultas SQL con la llamada Adaptive Query Execution (SPARK-31412). Esta mejora consiste en usar las estadísticas generadas en la propia ejecución de la consulta para optimizar su plan de ejecución.
Spark Streaming
En el ámbito del streaming de datos, Spark 3 incluye una nueva interfaz web de usuario (SPARK-29543) más moderna y que reemplaza a la antigua versión.
Esta interfaz muestra información útil y estadísticas para hacer más sencillo el proceso de debugging además de resultar fundamental para monitorizar los trabajos en un entorno de producción con métricas en tiempo real.
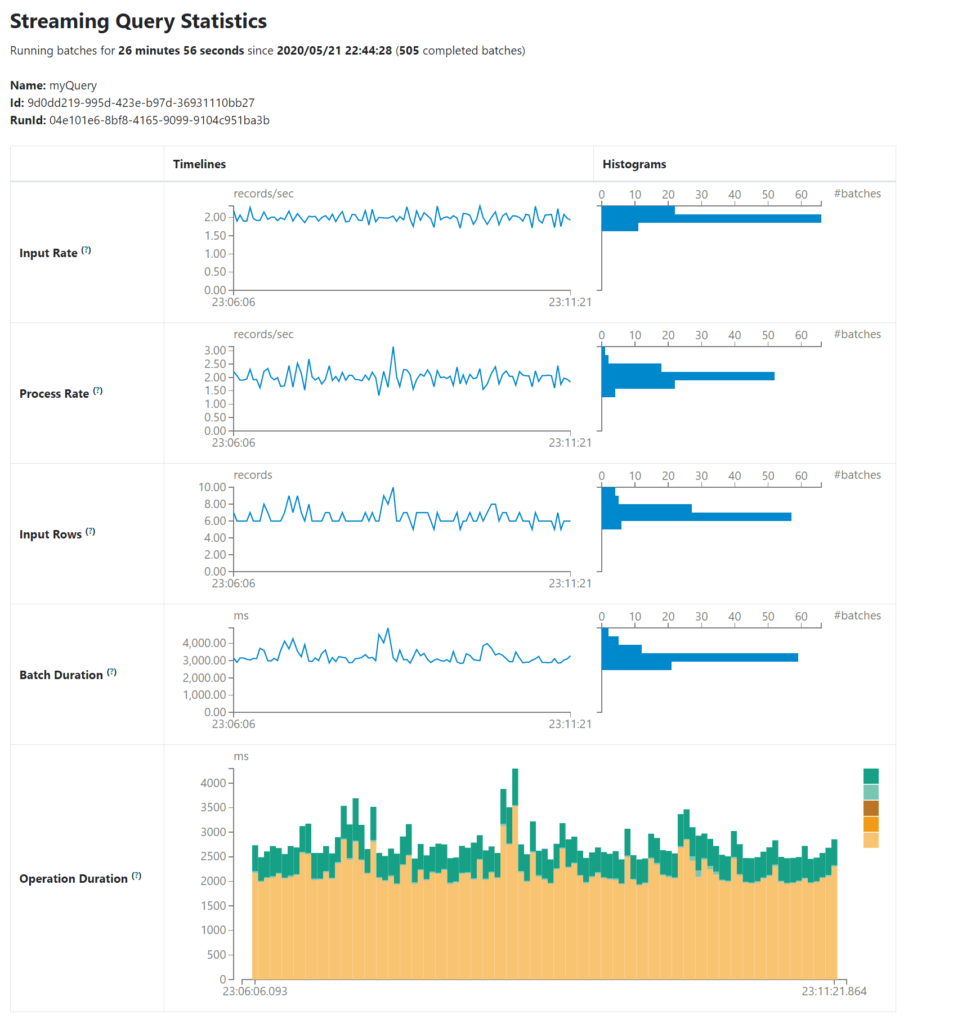
La nueva interfaz de Streaming muestra dos conjuntos de métricas. Por un lado muestra la información agregada del trabajo de streaming y por otro lado muestra información detallada de la consulta en streaming con datos del ratio de entrada de datos, duraciones de las operaciones, latencias, etc.
Spark 3 y ANSI SQL
El principal componente afectado en esta versión es Spark SQL, que incluye el 46% de los tickets resueltos. Los cambios afectan a librerías de alto nivel como Structured Streaming, MLlib, SQL y Dataframes.
Hasta ahora, Apache Spark no se encontraba a la altura del estándar ANSI SQL ya que tenía algunas particularidades diferentes. Con Spark 3 nos acercamos más a este estándar, del que podemos seguir el progreso en este enlace.
¿Quieres Convertirte en Ingeniero de Datos?
También se ha añadido una referencia SQL en la documentación de Spark, lo que es algo que agradecemos todos.
Pandas y PySpark
Esta versión aumenta las funcionalidades de Spark en Python. Incluye un rediseño de la API UDF de Pandas con nuevos tipos y gestión de errores (SPARK-28264).
Además en esta versión se marca el soporte a Python 2 como obsoleto.
Puedes acceder a las notas con los detalles de todos los cambios y mejoras en esta nueva versión de Spark en la publicación oficial.
Siguientes pasos y Curso Recomendado de Spark
Si quieres aprender Apache Spark a fondo y convertirte en experto, no dudes en invertir en tu formación a largo plazo.

PySpark Práctico: Apache Spark para Ingenieros de Datos
Aprende a procesar datos con Apache Spark y PySpark de forma distribuida. Entenderás cómo funciona internamente el framework y las maneras de optimizar las cargas de trabajo con un estilo muy práctico y fácil de seguir.
Siguientes pasos y Formación
Visita el artículo relacionado: Cómo crear un proyecto de Apache Spark con IntelliJ
Además, te dejo algunos libros recomendados:
- Spark: The Definitive Guide: Big data processing made simple
- Advanced Analytics with Spark
- 99 Apache Spark Interview Questions for Professionals (Kindle)
A continuación, el vídeo-resumen. ¡No te lo pierdas!

Arquitecto de Datos con más de 10 años de experiencia en el sector del Big Data. Autor de cursos de formación en tecnologías Big Data, Cloud y Streaming completados por más de 7000 alumnos en Udemy y otras plataformas. Miembro de la Apache Software Foundation desde 2019.


![Lee más sobre el artículo Mejores Cursos de Matemáticas en Udemy [Actualizado]](https://aprenderbigdata.com/wp-content/uploads/Mejores-cursos-Matematicas-Udemy-300x169.jpg)