En esta entrada repasamos los aspectos clave de Cloudera y las tecnologías que componen la distribución de Hadoop más popular para Big Data.

Contenidos
Aspectos Clave de Cloudera
Cloudera es la empresa de software responsable de la distribución de Big Data basada en Apache Hadoop más extendida. La plataforma integra varias tecnologías y herramientas para crear y explotar Data Lakes, Data Warehousing, Machine Learning y Analítica de datos.
Fue fundada en el año 2008 en California por ingenieros de Google, Yahoo y Facebook, haciendo disponible de esta forma una plataforma que incluía Apache Hadoop.
En el año 2019, las empresas Cloudera y Hortonworks, líderes en el sector del Big Data, se fusionan para convertirse en una compañía con el objetivo de proporcionar una arquitectura del dato moderna y basada en cloud.
Gran parte de los desarrollos de Cloudera han sido publicados como software open source con aportaciones a la comunidad, principalmente a la Apache Software Foundation. Uno de los proyectos más populares donados a la fundación por Cloudera es Apache Impala, un motor de consultas SQL para Hadoop.
Cloudera CDH
CDH (Cloudera’s Distribution including Apache Hadoop) es la distribución de Cloudera con Apache Hadoop orientada a empresas. La última versión es Cloudera 6 (CDH 6). Está disponible como paquetes RPM y paquetes para Debian, Ubuntu o Suse. Cloudera proporciona CDH en varias modalidades.
La versión más completa y empresarial es Cloudera Enterprise, que incluye suscripciones por cada nodo del clúster, Cloudera Manager y el soporte técnico. Por otro lado, Cloudera Express es una versión más sencilla, sin actualizaciones o herramientas de disaster recovery. Por último, existe una versión gratuita de CDH: Cloudera Community. Permite desplegar un clúster con un número de nodos limitado.
Es posible ejecutar Cloudera desde un contenedor Docker. Proporciona una imagen Docker con CDH y Cloudera Manager que sirve como entorno para aprender Hadoop y su ecosistema de una forma sencilla y sin necesidad de Hardware potente. También es útil para desarrollar aplicaciones o probar sus funcionalidades.
Cloudera CDP
En el año 2019 Cloudera presenta la nueva plataforma CDP (Cloudera Data Platform), con mejoras respecto a las versiones anteriores y compatibilidad extendida con entornos cloud como Azure, AWS y próximamente Google.
CDP se ha construido como un Enterprise Data Cloud (EDC) o Cloud de datos empresarial. Este conjunto de tecnologías alrededor de Hadoop permiten implementar multitud de casos de uso sobre la misma plataforma.
CDP puede desplegarse en infraestructura on premises, de forma híbrida y multi-cloud sin perder de vista la seguridad y el gobierno de los datos (governance) para cumplir con la regulación. Todos los despliegues en los diferentes entornos se realizan y gestionan desde un panel de control centralizado. Esto aplica en despliegues sobre infraestructura on-premises (CDP Private Cloud) y pública (CDP Public Cloud).
Además, CDP permite desagregar el almacenamiento del cómputo mediante el uso de contenedores y Apache Hadoop Ozone, un almacenamiento de objetos distribuido. De esta forma es posible conseguir mayor escalabilidad.
¿Quieres Convertirte en Ingeniero de Datos?
En CDP desaparecen algunas las tecnologías presentes en CDH como Apache Pig, Cruch, Sqoop, Flume, Storm, Druid y Mahout, que deberán reemplazarse con las tecnologías Apache Spark, Flink y NiFi. Además, el componente Apache Sentry se reemplaza por Apache Ranger y Cloudera Navigator por Apache Atlas.
CDP Public Cloud
En CDP Public Cloud podemos crear y administrar lagos de datos para analítica y machine learning sin instalar ni administrar el software de la plataforma. Los servicios son administrados por Cloudera y desplegados sobre un proveedor cloud como AWS, Azure o GCP. También, permite realizar el escalado de recursos dinámico en función de la carga de trabajo y de sus prioridades.
Componentes Principales de CDP Public Cloud
- Consola de Administración (Shared Data Experience – SDX): Encargado de la administración de entornos, lagos de datos, recursos del entorno y gestión de usuarios.
- Data Lake: Contiene los datos usando S3 (AWS) o ADLS (Azure) como capa de almacenamiento principal. Es el componente principal que debemos desplegar. También proporciona los servicios de Apache Ranger, Atlas y Knox.
- Data Hubs: Es el servicio que nos permite ejecutar y administrar clusters de trabajo con Cloudera. Proporciona un conjunto de clusters predefinidos que ejecutan junto al Data Lake.
- Data Engineering (Data Analytics Studio, HDFS, Hive, Hue, Livy, Oozie, Queue Manager, Spark, Yarn, Zeppelin, Zookeeper)
- Flow Management (Nifi, Nifi Registry, Zookeeper)
- Streams Messaging (Kafka, Schema Registry, Streams Messaging Manager, Zookeeper)
- Data Warehouse (CDW): Creación automática de data warehouses y data marts independientes que escalan automáticamente con Kubernetes. Incluye Warehouses virtuales de Impala y de Hive LLAP. Permite su explotación por analistas de datos y equipos de Business Intelligence (BI).
- Machine Learning (CML): Servicio de creación de entornos colaborativos para inteligencia artificial y de machine learning con notebooks. También ejecuta con contenedores en Kubernetes.
- Data Engineering Experience (CDE): Servicio que permite ejecutar clusters de Apache Spark y ejecutar trabajos en contenedores con autoescalado.
CDP Private Cloud
CDP Private Cloud nos permite desplegar nuestro entorno de Cloudera en nuesta cloud privada, máquinas virtuales o hardware bare-metal. Es la evolución de CDH. El Clúster Base de CDP Private Cloud incluye el Cloudera Manager, HDFS/Ozone, HMS, Ranger y Atlas.
En esta modalidad también podemos desplegar las llamadas experiencias sobre la instalación base que nos permite ejecutar Cloudera Data Warehouse (CDW) y Cloudera Machine Learning (CML) sobre una plataforma de contenedores Red Hat Openshift dedicada.
En la siguiente tabla podemos ver las diferencias entre las versiones de CDP Public Cloud y CDP Private Cloud:
| CDP Public Cloud | CDP Private Cloud | |
|---|---|---|
| Licenciamiento | Por hora (bajo demanda) | Por nodo (suscripción anual) |
| Almacenamiento | ADLS / S3 / GCS | HDFS / Ozone / Kudu |
| Contenedores (Experiencias) | AKS / EKS / GKE | Red Hat Openshift / Embebido |
| Nodos de Data Hub | EC2 / Máquina Virtual / GCE | Bare Metal o Máquina Virtual |
| Ciclo de vida | Primer despliegue | Tres meses después |
| Gestión, linaje, auditoría y seguridad | SDX | SDX |
| Replicación | Replication Manager | Replication Manager |
Cloudera CDF
CDF o Cloudera Data Flow compone la parte de CDP enfocada al streaming de datos en tiempo real. Es la evolución de la anterior distribución Hortonworks DataFlow (HDF). Contiene las piezas de software necesarias para realizar la ingesta, las transformaciones y la analítica sobre flujos de datos.
Todas las piezas de CDF están integradas con Apache Atlas para gestionar el linaje del dato y con Apache Ranger como herramienta de auditoría y autorización centralizada. La distribución se divide en varios módulos que incluyen varias soluciones. Dependerá del caso de uso la elección de la solución que mejor se adapte.
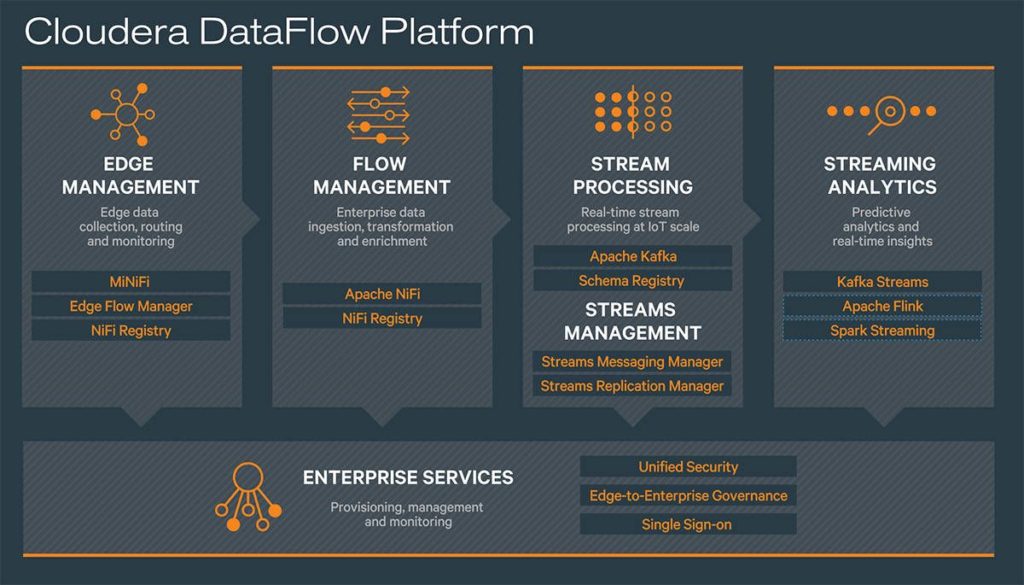
CDF resulta útil en múltiples casos de uso:
- Movimiento de datos entre diferentes data centers o hacia infraestructura cloud
- Recolección y analítica de logs de diversas fuentes de datos
- Analítica en streaming en búsqueda de patrones o modelos de inteligencia artificial
- Ingesta y transformación de datos de clientes de fuentes de datos
- Procesamiento en streaming y de tiempo real
- Captura e ingesta de datos de sensores e IoT para su análisis posterior
Las herramientas incluidas en CDF más importantes son:
- MiNiFi + NiFi para recolección e ingesta de datos.
- Apache Kafka para procesamiento de Streaming, además incluye:
- Schema Registry: Gestión centralizada y versionado de esquemas
- Streams Messaging Manager (SMM): Monitorización y gestión
- Streams Replication Manager (SRM): Motor de replicación (MirrorMaker2)
- Kafka Streams, Apache Flink y Spark Streaming para analítica.
Componentes de Cloudera
Cloudera integra en su distribución varias herramientas, que se pueden desplegar o no en función de las necesidades del cliente. Actualmente contiene más de 50 componentes open source. A continuación, se presentan los más importantes:
Tecnologías propietarias
Cloudera Manager es la aplicación responsable de la gestión de clusters Big Data. Se encarga de instalar y controlar los servicios activos y actúa como herramienta de administración para los operadores y administradores de Cloudera.
Cloudera Navigator es la pieza encargada del Data Governance que complementa Cloudera Manager. Se integra con las tecnologías de Apache Hadoop y permite monitorizar y auditar los accesos y establecer las políticas de acceso a los datos y a los recursos del clúster. Además, también es posible visualizar el linaje de los datos y consultar los metadatos
El servicio de Cloudera para desplegar de forma programática y automatizada clústers se llama Cloudera Director. Permite gestionar, desplegar y escalar entornos cloud a través de cloudera manager y el proveedor de cloud.
Otra pieza central es el Cloudera Workbench o Cloudera Data Science Workbench (CDSW). Es una plataforma colaborativa que permite desarrollar y desplegar trabajos de tipo Data Science y Machine Learning con R, Python o Scala en un entorno personalizable y adecuado a estas necesidades.
Tecnologías Open Source CDP
Los componentes Open Source de Cloudera están integrados alrededor del core de Apache Hadoop como tecnología de procesamiento y de almacenamiento distribuido. Entre ellos se encuentran tecnologías clave del ecosistema Hadoop.
Hue (Hadoop User Experience)
Apache Hue es la interfaz web para la gestión de Hadoop. Permite crear tablas en Hive, realizar consultas, navegar el sistema de ficheros, cambiar permisos y propietarios.
También puede diseñar jobs de MapReduce y conocer su estado. Además permite realizar la gestión por parte de los administradores de las cuentas de usuario.
Apache Sqoop (SQL to Hadoop)
Es una herramienta diseñada para transferir datos entre Hadoop y bases de datos relacionales. Al igual que Flume, es una herramienta de ingesta de datos para Hadoop, aunque Sqoop se caracteriza por poder importar y exportar datos estructurados.
Permite importar tablas individuales o bases de datos enteras a HDFS de una manera sencilla y eficiente. Con Sqoop, también es posible importar datos desde bases de datos relacionales directamente a tablas Hive. Cuando ejecutamos un comando en Sqoop, la tarea se divide en subtareas, que realizan la operación Map de forma distribuida y paralela.
Apache Zookeeper
Servicio centralizado que permite mantener conexiones estables entre servidores con distintas tecnologías. Actúa de coordinador de servicios big data y trabajos Hadoop. Zookeeper se usa principalmente para mantener aplicaciones distribuidas funcionando de forma correcta. También gestiona algunas configuraciones y permite el consenso en los sistemas.
Provee una interfaz simple para mantener la consistencia de datos.
Apache Hive
Hive Permite realizar consultas sobre los datos almacenados en HDFS mediante el lenguaje HQL (Hive Query Language), muy similar a SQL. Compone la base de un Data Warehouse con gran escalabilidad.
Apache Impala
Impala es un motor de consultas SQL para Hadoop inicialmente desarrollado por Cloudera. Permite realizar consultas interactivas de baja latencia sobre datos almacenados en HDFS sin la necesidad de movimiento de datos. Es muy usada en consultas analíticas y Business Intelligence.
Apache Oozie
Oozie es el planificador de workflows para administrar trabajos de Hadoop. Gestiona los trabajos y permite tratarlos como una sola unidad lógica. Permite agregar dos tipos de trabajos: workflow y coordinator. Los trabajos de tipo workflow se componen de una secuencia de acciones que deben ser ejecutadas en serie. Los trabajos Oozie coordinator son ejecutados cuando se cumple la condición de que los datos necesarios para la tarea estén disponibles.
Apache HBase
Es una base de datos no relacional, columnar y distribuida creada sobre el sistema de ficheros de Hadoop (HDFS) que puede escalar horizontalmente.
HBase utiliza un modelo de datos muy similar al de Google Big Table diseñado para proporcionar acceso aleatorio a una gran cantidad de datos estructurados. Tiene un modelo tolerante a fallos para almacenar columnas dispersas, muy comunes en big data. Está escrito en Java.
Apache Hadoop
Incluye los servicios HDFS, Yarn y Hadoop MapReduce.
La función de Yarn en Hadoop es la de proporcionar un entorno que gestione los recursos para realizar trabajos de computación. Yarn distribuye el trabajo teniendo en cuenta dónde se encuentras los datos a procesar del clúster. Además, Yarn también gestiona las ejecuciones de los programas y los recursos disponibles.
HDFS es el sistema de ficheros distribuido de Hadoop, optimizado para almacenar grandes cantidades de datos y mantener varias copias para garantizar la disponibilidad.
En HDFS, los ficheros son divididos en bloques de un mismo tamaño (128 MB) y distribuidos en los nodos que forman el clúster.
Apache Spark
Spark es el framework de computación distribuido más popular para desarrollar aplicaciones paralelas y tolerantes a fallos. Se basa en el modelo MapReduce y lo extiende con capacidades de streaming y de consultas interactivas. Incluye librerías de machine learning como MLlib y de streaming y soporta los lenguajes de programación Java, Scala, Python y R.
Apache Kafka
Kafka es un sistema de intermediación de mensajes basado en el modelo publicador/subscriptor en el que varios productores y subscriptores pueden leer y escribir. Se ha convertido en una plataforma de streaming de eventos distribuida y eje central de muchas arquitecturas Big Data.
Otros Servicios
- Atlas: Proporciona las capacidades de gobierno del dato para cumplir los requisitos regulatorios en el data lake. Ofrece gestión de metadatos, clasificación y catálogos para los elementos.
- Knox: Actúa como puerta de enlace de las aplicaciones. Proporciona un único punto de acceso para las peticiones REST y HTTP hacia los servicios del clúster.
- Kudu: Tecnología de almacenamiento columnar distribuido desarrollado para Hadoop. Está enfocado a almacenar datos estructurados con acceso aleatorio de baja latencia. Es un motor orientado a conectar HDFS y HBase como base de datos NoSQL.
- Livy: Servicio que proporciona una interfaz REST para interactuar con el clúster de Spark. Es posible ejecutar trabajos y conocer los resultados de manera síncrona o asíncrona.
- Ozone: Almacenamiento de objetos distribuido y escalable para Hadoop. Puede ejecutar en entornos de contenedores como Kubernetes YARN.
- Ranger: Proporciona una interfaz para gestionar y monitorizar la seguridad de los datos y de los servicios y componentes de la plataforma.
- Solr: Base de datos NoSQL escalable y tolerante a fallos que permite realizar búsquedas de texto potentes e indexar documentos.
- Tez: Framework de procesamiento distribuido optimizado.
- Zeppelin: Notebooks colaborativos y accesibles desde el navegador que permiten realizar análisis de datos con SQL, Python o Scala.
Tecnologías Open Source CDH
Apache Flume
Apache Flume es una solución Java distribuida de alta disponibilidad para recolectar, agregar y mover grandes cantidades de datos no estructurados y semi-estructurados desde diferentes fuentes a un data store centralizado. Es la herramienta de ingesta en el ecosistema Hadoop.
Esta tecnología surge de la necesidad de subir datos de aplicaciones a HDFS. Pueden ser datos generados en streaming y tiempo real como logs, tráfico de red, etc. Cada agente de flume está compuesto por tres piezas: Source (Fuente), Channel (Canal) y Sink (Sumidero). Es extremadamente flexible y tiene numerosos conectores.
Apache Sentry
Es la pieza del ecosistema que se encarga de aplicar las políticas de autorización sobre los componentes del clúster y sobre los datos y metadatos de Hadoop. Permite controlar los privilegios de cada usuario y aplicación del sistema que usan los componentes de Hadoop de forma modular.
Apache Mahout
Mahout proporciona el entorno para crear aplicaciones escalables de Machine Learning. Se compone de librerías específicas escritas en Java y optimizadas para funcionar sobre Hadoop. Entre sus funcionalidades, se incluyen el filtrado colaborativo, clustering y clasificación.
Apache Pig
Pig es la plataforma de scripting para Hadoop, originalmente desarrollada en Yahoo. Proporciona la base para implementar flujos de datos, ETLs y procesamiento distribuido. Tiene dos componentes: Pig Latin y Pig Runtime, el entorno de ejecución.
Provee de un lenguaje de alto nivel llamado Pig Latin para crear flujos de datos que permite escribir programas MapReduce de forma simple y en pocas líneas de código, con una sintaxis similar a SQL. El compilador interno se encarga de convertir Pig Latin en una secuencia de programas MapReduce.
Siguientes pasos y Cursos de Cloudera
Aprende a fondo la tecnología y mantente al día para tus proyectos con estos cursos recomendados de Cloudera. Además, podrás preparar sus certificaciones. En mi opinión, una forma excelente de aportar valor y destacar:

Curso de Especialización en Big Data de Cloudera
Esta especialización de Coursera ofrecida directamente por Cloudera es muy completa y se compone de cuatro módulos de aprendizaje para dominar la plataforma de análisis de datos y si estás interesado, también preparar la certificación:

Guía práctica de instalación de un clúster Cloudera CDH con Hadoop y Spark (CCA 131)
Curso práctico de Udemy que te permitirá introducirte a administrador de Cloudera con multitud de material de aprendizaje sobre el ecosistema Hadoop, Spark y su arquitectura.
Artículos Relacionados:
- Seguridad en Hadoop y Cloudera Data Platform (CDP)
- Disaster Recovery en Cloudera CDP
- Formación y certificaciones en Cloudera
Preguntas frecuentes: Cloudera – FAQ
¿Qué es Cloudera?
Cloudera es la empresa de software responsable de la distribución de Hadoop con el mismo nombre. Su plataforma de Big Data se centra en proporcionar herramientas de Data Warehousing, Machine Learning y Analítica.
¿Qué es Cloudera CDH y CDP?
CDH (Cloudera’s Distribution including Apache Hadoop) es la distribución de Cloudera con Apache Hadoop para empresas. Su función es integrar las distintas piezas de software del ecosistema Hadoop. CDP (Cloudera Data Platform) es la evolución de CDH, integrando Cloudera y Hortonworks como una plataforma del dato híbrida en la nube con funcionalidades adicionales.
¿Cuáles son las alternativas a Cloudera?
Las distribuciones de Hadoop alternativas a Cloudera son Hortonwors (la empresa se ha unido con Cloudera dando lugar a CDP) y MapR. También existen alternativas para cargas Big Data como Databricks y servicios gestionados en la nube de Amazon o Azure.
¿Cuánto cuesta Cloudera?
Cloudera ofrece una versión gratuita de CDH hasta un número de nodos. Para despliegues mayores se debe mantener una suscripción, que incluye el soporte empresarial por parte de Cloudera así como servicios adicionales.
¿Debería obtener una certificación de Cloudera?
Cloudera ofrece varias certificaciones en torno a sus productos y a varios perfiles profesionales. Estas certificaciones son una opción excelente para destacar como experto en las tecnologías y aportar valor a las organizaciones. Recuerda prepararlas correctamente mediante cursos y estudio previo.
A continuación, el vídeo-resumen. ¡No te lo pierdas!

Arquitecto de Datos con más de 10 años de experiencia en el sector del Big Data. Autor de cursos de formación en tecnologías Big Data, Cloud y Streaming completados por más de 7000 alumnos en Udemy y otras plataformas. Miembro de la Apache Software Foundation desde 2019.


