En esta entrada aprenderemos qué es un Data Lake en el mundo del Big Data y sus diferencias con los Data Silos y los Data Warehouses. Además, exploraremos las alternativas que existen para construir data lakes con tecnologías modernas y aprovechando los servicios cloud.

Contenidos
¿Qué es un Data Lake?
Un data lake o lago de datos es un repositorio centralizado que permite almacenar, compartir, gobernar y descubrir todos los datos estructurados y no estructurados de una organización a cualquier escala. Es el lugar en el que se vuelcan los datos en bruto.
Los data lakes no requieren un esquema predefinido, se pueden almacenar y procesar datos sin esquema y en cualquier formato sin la necesidad de conocer cómo se van a explotar en el futuro. Esta característica evita que sean necesarios complejos procesos ETL (Extracción, Transformación y Carga) de limpieza y preparación.
Entre las características más importantes de los data lakes se encuentra su flexibilidad en almacenar diferentes tipos de datos, que proporciona la agilidad necesaria para los procesos de ingesta. También es muy importante que proporcione suficiente trazabilidad, y de esta manera poder determinar los cambios que han sufrido los datos en los procesos de transformación o ingesta.
Buenas prácticas en Data Lakes
Un buen data lake debe permitir la ingesta de datos estructurados y no estructurados y almacenarlos con seguridad y con las debidas protecciones de acceso, incluso en tiempo real. Estas restricciones de acceso pueden ser de lectura o de modificación al nivel del dato e incluyen todas las capas de autenticación y autorización. Además, debe proporcionar un catálogo que permita a los analistas y profesionales descubrir los datos que contiene.
Es común que existan varias referencias a los mismos tipos de datos en un único data lake. Puede darse el caso de que los datos almacenados tengan etiquetas diferentes pero se refieran al mismo concepto. De esta forma, se debe generar una relación para que los analistas conozcan su existencia.
A menudo se usan mecanismos de compresión para disminuir el espacio usado por los datos. Este mecanismo debe ser compatible con las lecturas de tecnologías como Hive, Impala o HBase. Se deben evaluar las opciones disponibles en cuanto a ahorro de espacio y disminución de performance. Los protocolos más comunes son Snappy y LZO (performance) o GZip (espacio).
Aparte de estos puntos, en cualquier enterprise data lake (lago de datos empresarial) es necesaria su conexión con herramientas analíticas, de reporting, de procesamiento y de inteligencia artificial y de esta forma extraer valor de los datos de la organización.
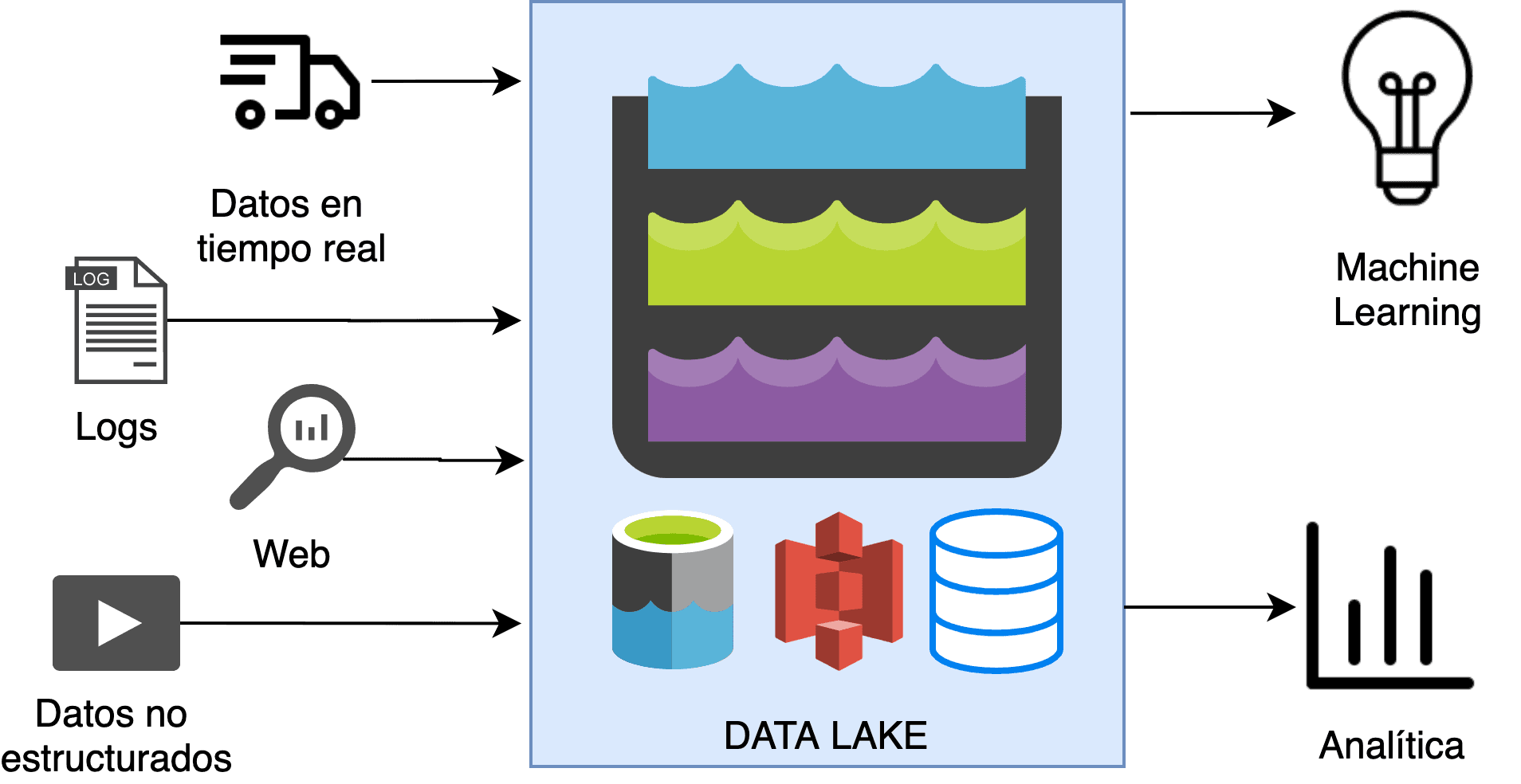
Es importante anotar que en cualquier proyecto de creación de data lake empresarial hay que prestar especial atención al seguimiento y al desarrollo de un catálogo de los datos. No es suficiente con crear el lago y volcar todos los datos en él, sino que debemos evaluar constantemente las oportunidades de sacar partido a estos datos.
Puntos clave en la arquitectura de un data lake
Para implementar un lago de datos correctamente, deberemos tener en cuenta los puntos listados a continuación.
- Identificar los objetivos de la organización para el lago
- Separación de cómputo de almacenamiento, para escalar de forma independiente en función de las necesidades
- Definir el catálogo de datos para diferentes perfiles de datos
- Establecer backups y estrategias de recuperación de desastres
- Implementar los mecanismos de trazabilidad, metadatado y de gobierno del dato
- Determinar las tecnologías del lago considerando las habilidades de los usuarios y su rendimiento
- Usar herramientas de automatización y DevOps
- Diseñar la seguridad del data lake con la autenticación, autorización y privacidad necesarias
Data Silos
Los silos de datos ocurren cuando no existe un lugar o un sistema centralizado en el que almacenar todos los datos de la organización. Un silo, por tanto, hace más complicado descubrir nuevos datos, ya que cada uno de ellos está controlado por un departamento independiente, con diferentes políticas e incluso tecnologías.
La razón principal de adopción de data lakes en las compañías es evitar los silos de datos, que suelen producirse en adquisiciones o a causa de un crecimiento rápido y poco controlado.
¿Quieres Convertirte en Ingeniero de Datos?
Los silos de datos pueden dar la sensación de ser necesarios para permitir mayor flexibilidad a los equipos, iterar de forma más rápida y ajustar sus políticas a sus necesidades de una manera sencilla. Sin embargo, desde un punto de vista global, dificultan en gran manera extraer valor de los datos y descubrir nuevas ideas. Además, es necesaria la creación de procesos y permisos para recoger datos de muchas fuentes independientes y diversas para agregarlos más tarde. Estos procesos son más eficientes al trabajar juntos.
Al adoptar un data lake como repositorio central se pueden elegir tecnologías que permitan escalar los sistemas fácilmente. Aquí, todos los equipos pueden seguir funcionando de forma independiente, pero con la capacidad de acceder de una forma sencilla a todos los datos de la organización si fuera necesario.
Data Lake vs Data Warehouse
La diferencia entre estos dos conceptos no es estricta, ya que data lake se suele usar como término para herramientas de gestión y de almacenamiento de datos que no cumplen el concepto tradicional de data warehouse. Por tanto, el data warehouse suele ser un subconjunto de las tecnologías involucradas en el despliegue de data lakes. Los Data Warehouses son más lentos y complejos de implementar que los Data Lakes.
Generalmente estos dos conceptos conviven. Por un lado, se proporciona la flexibilidad de almacenar datos estructurados y accedidos frecuentemente en el data warehouse. Por otro lado, todo el data lake permite tener una gran capacidad de almacenamiento de datos estructurados, semi-estructurados y no estructurados. En cuanto al procesamiento de datos, los data lakes suelen necesitar un servicio separado como Spark. Los Data Warehouses aportan este servicio de procesamiento.
El data warehouse comprende los componentes del data lake encargados de tratar datos estructurados. En un data lake la preparación de los datos para su análisis podría realizarse en el momento en el que sea necesario, mientras que en un data warehouse es más sencillo explotar directamente los datos con herramientas de business intelligence (BI).
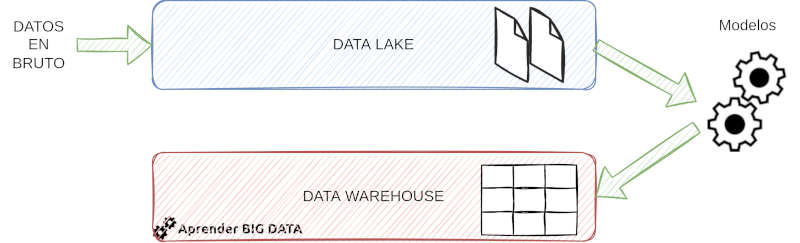
Los Data Lakes se han asociado a servicios de almacenamiento cloud como S3 o ADLS, mientras que los Data Warehouses se han asociado a servicios de bases de datos OLAP. Esta diferencia se está volviendo más difusa con servicios como Snowflake o Databricks con Delta Lake.
Inteligencia artificial y Data Lakes
Los lagos de datos son una herramienta fundamental para el desarrollo de inteligencia artificial (AI) y machine learning (ML) ya que son procesos basados en grandes conjuntos de datos y de naturaleza diversa.
Estos procesos usan algoritmos estadísticos que se entrenan sobre datos existentes y así son capaces de tomar decisiones sobre nuevos datos (inferencia) y de descubrir nuevos patrones o relaciones. Mediante estos algoritmos es posible generar modelos que toman decisiones inteligentes sobre datos que no existían.
Observamos una relación directa entre la cantidad de datos disponibles para entrenar los modelos y sus resultados. De forma general, cuantos más datos se tienen disponibles, el modelo se entrenará mejor y por tanto tomará mejores decisiones con una mayor precisión.
La ventaja de disponer de un buen data lake para estas operaciones es evidente. Cada vez toman más importancia los procesos de machine learning en las organizaciones, y muchos modelos les permiten optimizar costes y estimar la demanda futura, lo que tiene un impacto enorme en los resultados empresariales. Mejorar estos procesos, por tanto, se vuelve de vital importancia, y aumentar su precisión está muy valorado.
Azure Data Lake
La fuente de datos y principal sistema de almacenamiento en Azure para cualquier Data Lake es ADLS (Azure Data Lake Storage). ADLS Gen2 extiende la funcionalidad del almacenamiento de objetos de Azure Blob Storage y lo convierte en un sistema de ficheros compatible con los conectores de Hadoop. Tiene un coste por uso y una escalabilidad prácticamente ilimitada.
Además, Azure proporciona clústers de varios tipos como servicio en HDInsight. Con él, se pueden desplegar de forma sencilla clústers de Hadoop, Spark o Kafka, en función de las necesidades.
La pieza del catálogo de Azure para desarrollar las ETLs e integración de datos es Azure Data Factory. De una forma visual facilita la creación de flujos de datos entre los sistemas de la organización.
AWS Data Lake
Amazon Web Services (AWS) proporciona varias opciones para implementar nuestro Data Lake empresarial. Estos lagos se componen de varias tecnologías que podemos dividir por categorías.
Como fuente de datos, Amazon S3 (Simple Storage Service) se encuentra en el centro de cualquier sistema de AWS. Este servicio de almacenamiento de objetos proporciona la durabilidad y escalabilidad necesaria. Es la pieza equivalente a ADLS en Azure.
Por otro lado, Amazon Redshift permite desplegar un data warehouse como servicio. Usa SQL para las consultas y es totalmente compatible con S3 como capa de almacenamiento en varios formatos. Además, nos permite procesar los datos almacenados con streams.
Si queremos un servicio en el que desplegar tecnologías open source del ecosistema Hadoop, podemos usar Amazon EMR (Elastic MapReduce), que nos proporciona clusters flexibles.
Como tecnología de ingesta de datos y ETL, podemos desplegar AWS Glue. Este servicio nos permite enriquecer los datos y realizar las validaciones que necesitemos para preparar nuestros datos para analítica.
Cloudera Data Lake
Otra forma de desplegar un data lake es mediante la distribución de Hadoop de Cloudera. Estas tecnologías permiten el despliegue de lagos de datos a medida sobre hardware propio o bien en cloud. Está basada en tecnologías Hadoop y open source y el almacenamiento de datos se realiza en HDFS.
La distribución más moderna de Cloudera es CDP (Cloudera Data Platform) y hace un uso completo de las capacidades de despliegue de componentes en cloud para ofrecer soluciones híbridas y multi-cloud.
Cursos de Data Lake
Con estos dos cursos podrás aprender cómo implementar lagos de datos en la nube desde cero, una habilidad básica para cualquier ingeniero de datos.

Introducción al diseño de Data Lakes en AWS
Con este curso oficial de AWS en Coursera aprenderás los conceptos básicos de un Data Lake en la nube rápidamente, además de explorar las herramientas y servicios serverless en AWS. Empezarán explicando sus componentes y a lo largo de las 14 horas de curso aprenderás las mejores prácticas.

Modernizando Data Lakes con Google Cloud
Este curso ofrecido directamente por Google te enseñará cómo usar Google Cloud y sus soluciones de datos para modernizar e implementar Data Lakes potentes y eficientes en la nube.
Preguntas Frecuentes Data Lakes – FAQ
¿Qué es un Data Lake?
Un Data Lake es un repositorio centralizado que permite almacenar, compartir, gobernar y descubrir grandes cantidades de datos estructurados y no estructurados de una organización a cualquier escala
¿Para qué sirve un Data Lake?
La utilidad principal de un Data Lake es almacenar copias en bruto de los datos de una organización para su explotación en procesos de análisis, reporting y machine learning para extraer valor
¿Cuál es la diferencia entre un Data Warehouse y un Data Lake?
La diferencia principal entre estos dos términos es que un Data Warehouse contiene datos estructurados y filtrados ya preparados para procesos analíticos, mientras que un Data Lake puede contener todo tipo de datos, incluso sin un propósito definido.
¿Qué es un Data Silo?
Un Data Silo o silo de datos es un repositorio independiente que aloja los datos de un determinado departamento o sección de una organización con un propósito específico. Cada uno con diferentes políticas o tecnologías
A continuación, el vídeo-resumen. ¡No te lo pierdas!

Arquitecto de Datos con más de 10 años de experiencia en el sector del Big Data. Autor de cursos de formación en tecnologías Big Data, Cloud y Streaming completados por más de 7000 alumnos en Udemy y otras plataformas. Miembro de la Apache Software Foundation desde 2019.

![Lee más sobre el artículo Mejores cursos de Java en Udemy [Actualizado]](https://aprenderbigdata.com/wp-content/uploads/Mejores-cursos-udemy-Java-300x169.jpg)