¿Quieres saber qué es y cómo usar Amazon EMR? En esta entrada explico las características del servicio en la nube Amazon EMR para Big Data. Aprende aquí qué te puede aportar en tu estrategia cloud este servicio de AWS.

Contenidos
¿Qué es Amazon EMR?
EMR es una plataforma gestionada en AWS que nos permite ejecutar trabajos Big Data con el ecosistema Hadoop como motor de procesamiento distribuido. Usa instancias de Amazon Elastic Compute Cloud (Amazon EC2) para ejecutar los clusters con los servicios open source que necesitemos, como por ejemplo Apache Spark o Apache Hive.
EMR tiene HDFS como capa de almacenamiento para el clúster. También, nos permite desacoplar el cómputo del almacenamiento usando el servicio S3 para almacenar datos y logs sin límite.
Se puede elegir entre varias versiones que determinan el stack open source que se despliega en el clúster. Incluye Hadoop, Hive, Tez, Flink, Hue, Spark, Oozie, Pig y HBase entre otros.
El sistema también está integrado con otros servicios de AWS y nos proporciona notebooks para ejecutar código en el clúster. Se puede usar Jupyter Lab usando Apache Livy.
Arquitectura de EMR
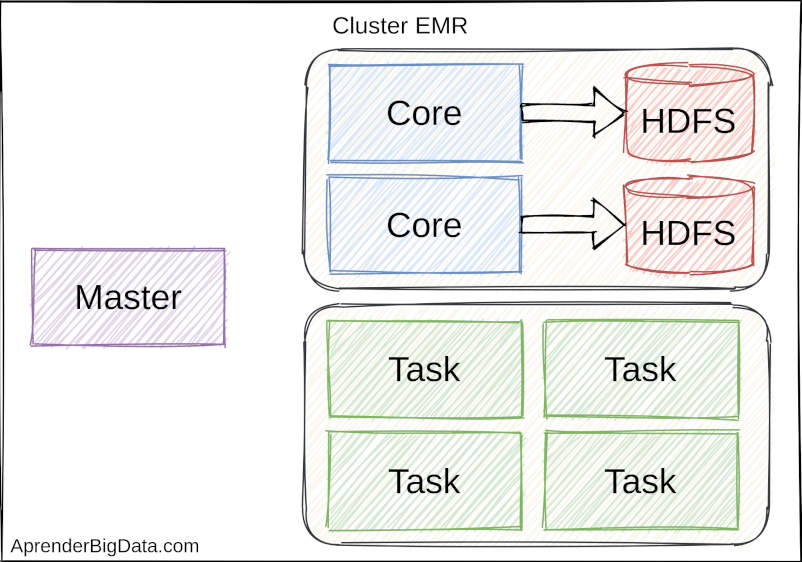
EMR tiene tres tipos de nodos:
Master: Los nodos Master deben estar en funcionamiento para dar servicio al clúster. Se pueden desplegar varios para tener alta disponibilidad. Por defecto, alojan servicios como Hive Metastore.
Core: Estos nodos se encargan de almacenar los datos en HDFS y ejecutar los trabajos, también se pueden escalar.
Task: Estos nodos no almacenan datos por lo que se pueden añadir y eliminar sin riesgos de pérdida de datos. Se usan par añadir capacidad de procesamiento al clúster.
Entre las opciones de despliegue que tiene EMR podemos elegir pago por uso, en función del tiempo o ahorrar en costes usando instancias reservadas, planes de ahorro o instancias spot de AWS.
Escalado en Amazon EMR
En función de las cargas de trabajo que queramos ejecutar, podemos desplegar clusters de EMR específicos para la duración de nuestro trabajo o bien tener un clúster permanente con alta disponibilidad y auto escalable en función de la demanda. El primer caso está aconsejado para trabajos puntuales y más ligeros.
Los despliegues de EMR se pueden escalar de forma automática o de forma manual estableciendo límites de nodos core. Para escalar el clúster se usarán métricas de utilización, tomando en cuenta las réplicas de datos.
En el caso de trabajos de streaming con Spark Streaming deberemos analizar muy bien la capacidad del clúster para escalar con el volumen. Es posible que el clúster pueda añadir capacidad automáticamente pero cuando el volumen de trabajo vuelva a disminuir no sea capaz de reducir el número de nodos, aumentando los costes considerablemente.
Almacenamiento en Amazon EMR
Debemos entender que EMR proporciona dos formas de almacenamiento:
EMRFS: Este sistema de ficheros se basa en el servicio S3. Tiene la capacidad de desacoplar el cómputo del clúster del almacenamiento.
HDFS: Necesita un clúster dedicado. Debemos configurar un factor de replicación para los nodos Core y tenerlo en cuenta para un correcto dimensionamiento.
¿Quieres Convertirte en Ingeniero de Datos?
EMR siempre necesita HDFS, por lo que al menos se necesitará un nodo de tipo Core.
Ambos modos son compatibles, y podemos persistir nuestros datos en el almacenamiento que necesitemos. También, podremos usar s3DistCp para copiarnos datos entre ellos.
En trabajos en los que no se realicen muchas operaciones de lectura, podremos usar EMRFS con S3 para optimizar los costes. En los trabajos con muchas lecturas iterativas (por ejemplo Machine Learning), nos beneficiaremos más de un sistema como HDFS.
Seguridad en Amazon EMR
Cuando ejecutamos un clúster en EMR podemos tener varios usuarios o equipos de trabajo compartiendo sus recursos para ejecutar sus cargas analíticas. Por esta razón, es muy importante tener mecanismos de autenticación, de autorización y de auditoría, que nos van a permitir determinar quién tiene acceso a los datos y mantener un log de acceso.
El proyecto open source que proporciona capacidades de autorización y auditoría es Apache Ranger. Esta tecnología es compatible con el stack de servicios de EMR. AWS proporciona plugins para integrar Apache Ranger 2.0 con Apache Spark, Apache Hive y Amazon S3.
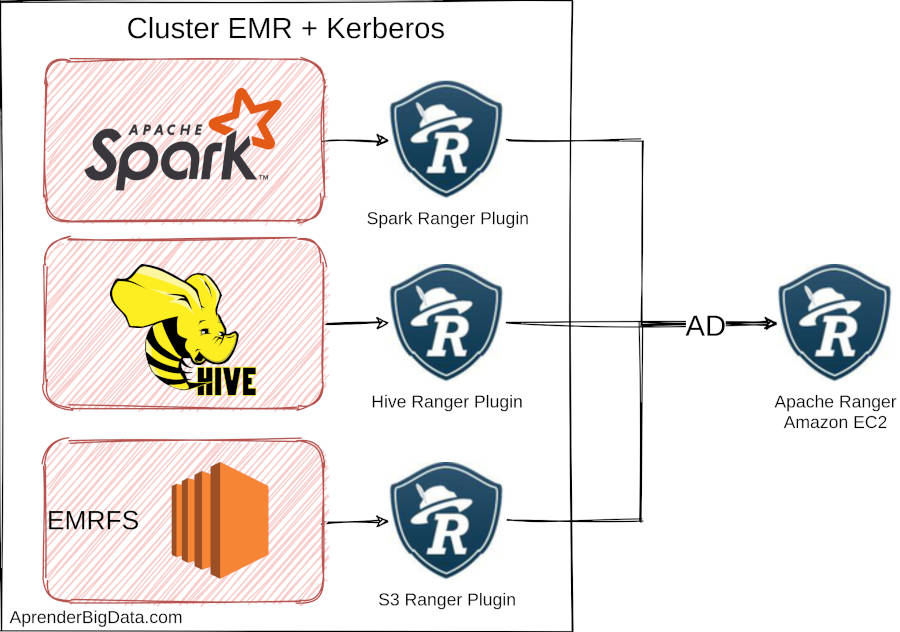
Debemos desplegar y gestionar Ranger fuera de nuestro clúster de EMR y complementarlo siempre con Kerberos como mecanismo de autenticación. Además, deberemos activar TLS entre el servidor de Ranger y los plugins que ejecutan en nuestro clúster de EMR. En Ranger, podremos configurar el acceso al nivel de bases de datos, objetos s3, tablas y columnas.
Cómo ahorrar costes en EMR
Aquí tienes algunas estrategias de alto nivel que debes considerar para reducir el coste de ejecutar tu cluster de Amazon EMR:
- Usa instancias por hora: Las instancias por hora te permiten pujar por la capacidad sobrante de Amazon EC2 a un precio reducido, lo que puede reducir significativamente el coste de ejecutar un cluster. Puedes establecer también el precio máximo que estás dispuesto a pagar por una instancia por hora, y si el precio actual del mercado cae por debajo de esa cantidad, el cluster utilizará las instancias por hora. Si el precio del mercado excede su precio máximo, el cluster cambiará automáticamente a instancias bajo demanda.
- Utiliza el tipo de instancia adecuado: Elije el tipo y tamaño de instancia adecuado para la carga de trabajo. Utilizar instancias más grandes o más potentes puede ser más caro, pero también puede mejorar el rendimiento del cluster.
- Utiliza la cantidad adecuada de instancias: Si utilizas pocas instancias, es posible que el cluster no pueda manejar la carga de trabajo de manera eficiente, lo que puede provocar tiempos de ejecución más largos y mayores costes. Por otro lado, si utilizas demasiadas instancias, seguramente pagues por recursos que no son necesarios.
- Autoescalado de EMR: El Autoescalado de EMR permite ajustar automáticamente el número de instancias en el cluster en función de la carga de trabajo y de los recursos disponibles. Esto puede ayudar a optimizar el coste y el rendimiento del cluster escalando hacia arriba o hacia abajo según sea necesario.
- Almacenamiento intermedio de EMR: El almacenamiento intermedio de EMR permite almacenar y procesar datos intermedios en las instancias del cluster, en lugar de almacenarlos en Amazon S3. Esto puede reducir la cantidad de trasferencia de datos entre el cluster y S3, lo que también ayuda a reducir los costes.
- Utiliza la última versión de EMR: Las versiones más recientes de EMR suelen incluir mejoras de rendimiento y características de optimización de costes.
Conclusión
Podríamos comparar EMR en AWS con HDInsight en Azure. Al igual que HDInsight, Amazon EMR ofrece muchas posibilidades de configuración, con un gran stack de servicios open source.
Cuando usamos EMR, podemos elegir los servicios que queremos incluir en el clúster. Sin embargo en HDInsight los tipos de clúster vienen predefinidos. También, HDInsight está configurado para usar directamente el almacenamiento sobre Azure Blob Storage, lo que incrementa el rendimiento y desacoplamiento desde el principio.
Resulta una opción muy interesante al realizar migraciones desde un clúster local hacia la nube, por ejemplo desde Cloudera. Al proporcionar los mismos servicios, no habría necesidad de adaptar el código o la forma de trabajar.
Cuando usamos EMR debemos tener muy en cuenta las opciones disponibles para ahorrar costes, como el uso de instancias spot y el escalado automático.
Sigue Aprendiendo sobre AWS
Artículo recomendado: Databricks vs EMR
Puedes seguir aprendiendo sobre AWS y EMR para Big Data con este curso de Udemy recomendado (en inglés)

Este curso te introducirá al ecosistema de EMR con Hadoop. Aprenderás a identificar los problemas que resuelve, desplegar EMR y desarrollar aplicaciones.
Preguntas Frecuentes EMR – FAQ
¿Cuál es el precio de Amazon EMR?
El coste total del servicio depende del tipo y tamaño de instancias que use para desplegar. El modelo de coste se calcula por cada segundo de uso.
¿Se puede detener un clúster de EMR?
Un clúster de EMR no se puede detener. Podemos destruir el clúster para eliminar todos los recursos asociados.
A continuación, el vídeo-resumen. ¡No te lo pierdas!

Arquitecto de Datos con más de 10 años de experiencia en el sector del Big Data. Autor de cursos de formación en tecnologías Big Data, Cloud y Streaming completados por más de 7000 alumnos en Udemy y otras plataformas. Miembro de la Apache Software Foundation desde 2019.


