En este artículo aprenderás en qué consiste el servicio de Azure para Big Data HDInsight, que nos va a permitir ejecutar nuestras cargas de trabajo Big Data en la nube con los servicios que estamos acostumbrados.

Contenidos
¿Qué es Azure HDInsight?
Azure HDInsight o HDI es la solución gestionada de analítica en Microsoft Azure. Está construida sobre plataformas open source como Hadoop, Spark, Hive o Kafka. La versión actual es HDInsight 4.0.
En HDI se pueden desplegar 5 tipos de clusters:
- Apache Hadoop: Este clúster incluye HDFS, MapReduce, Yarn, Hive, Pig, Sqoop y Oozie.
- Apache Spark: Incluye los componentes del clúster de Hadoop y Spark.
- Interactive Query: Incluye Hive LLAP, para tener caché en memoria, acelerar y hacer interactivas las consultas de Hive.
- Apache HBase: Incluye HBase, para usar cuando se necesite acceso aleatorio y en tiempo real a los datos.
- Apache Kafka: Incluye Kafka y Zookeeper.
Aunque no es posible crear clusters que combinen estos tipos y servicios, sí que es posible crear los clusters del tipo que necesitemos en la misma red virtual compartida de Azure.
Los clusters de HDInsight no tienen opción de parar ni reanudar su ejecución, por lo que deberemos destruirlos completamente cuando ya no necesitemos el servicio.
Los trabajos de Spark se pueden ejecutar fácilmente con la API de Apache Livy, que viene ya integrado en el clúster. También se pueden planificar con Oozie.
El Enterprise Security Package (ESP) es una funcionalidad adicional que añade la capacidad a los clusters de HDI de integrarse con Apache Ranger y Azure Active Directory (AAD).
El coste de HDI es simplemente el de los recursos que se despliegan, como el tipo y el número de las máquinas virtuales, las redes, etc. No tiene un coste por servicios. El único coste adicional es en el caso de que activemos el ESP, que es proporcional a los recursos de Azure usados.
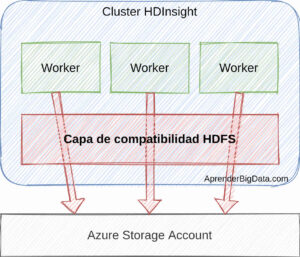
Almacenamiento en Azure
Clusters Volátiles
Los clusters de HDI tardan en desplegar de 10 a 15 minutos. Este despliegue se puede realizar con el asistente de Azure o programáticamente a través de Azure CLI. Aquí dejo una referencia con los comandos para gestionar los recursos de HDI.
Una opción interesante consiste en usar estos recursos como clusters volátiles, que se despliegan para ejecutar cargas de trabajo particulares y se destruyen cuando terminan sus trabajos, quedando los datos en el almacenamiento de Azure (ADLS).
Por defecto, HDI despliega los servicios de Ambari, Hive y Oozie sobre una base de datos Azure SQL gestionada por HDI. Es posible indicar una base de datos externa o no manejada por HDI para poder usar también con otro clúster.
Esta funcionalidad, nos permite desplegar un nuevo clúster sobre una base de datos existente y de esta forma tener un control absoluto de la misma y hacerla persistente.
Autoescalado de Recursos
HDI también permite hacer que los recursos de nuestros clusters aumenten y disminuyan cuando la carga de trabajo aumente o disminuya respectivamente. Este proceso es automático, y se puede configurar de dos maneras:
- En función de la carga: El clúster aumentará el número de nodos workers basándose en la actividad del clúster.
- Autoescalado planificado: Permite planificar unos tiempos en los que se aumentará o reducirá el número de nodos del clúster. Podemos configurar franjas de horas o de días según nos convenga.
HDI monitorizará métricas como la CPU libre, la memoria en uso, la memoria libre o el número de aplicaciones por nodo para determinar cuándo añadir más nodos o reducir su número.
¿Quieres Convertirte en Ingeniero de Datos?
Esta funcionalidad es muy útil para absorber los picos de carga que se puedan producir. Sin embargo, debemos estudiar bien nuestros procesos, ya que es posible que HDI no sea capaz de desalojar bien determinados nodos (por ejemplo executors de spark que se quedan con una tarea) y por tanto infrautilizar nuestra infraestructura, con el sobrecoste que esto supone.
En el caso de Kafka, la funcionalidad de autoescalado no se encuentra disponible para evitar escenarios de pérdida de datos.
Notebooks en Azure HDInsight
Los clusters de HDI con Spark, proporcionan Jupyter y Zeppelin notebooks, que podemos usar para probar y desarrollar nuestras aplicaciones. Los notebooks pueden ser de tipo PySpark, PySpark3 o Spark con Scala.
Los notebooks de Jupyter se podrán almacenar en la cuenta de almacenamiento de Azure que tengamos configurada, por lo que los podremos reutilizar entre clusters.
También, podemos configurar Livy para usar Jupyter desde nuestra máquina local.
Databricks vs HDInsight
Como vimos en el artículo de introducción a Databricks, es una solución con características similares a Azure HDInsight para ejecutar nuestros procesos analíticos en la nube.
Ambas soluciones están disponibles en Azure e integrados con el almacenamiento ADLS Gen2. HDI, al estar basado en el stack de tecnologías open source, puede resultar en una alternativa de migración más directa para los equipos que quieran trasladar sus trabajos a la nube pública.
En cuanto al coste, debemos tener en cuenta que Databricks tiene un coste por servicio además del coste de la infraestructura. Sin embargo, facilita mucho los despliegues de clusters para cargas de trabajo puntuales o periódicas, funcionalidad que no está presente en HDI.
También, para elegir la alternativa adecuada, debemos evaluar las tecnologías que vamos a utilizar. HDI nos da un abanico muy amplio de servicios que podremos usar en el ecosistema de hadoop. Databricks en una plataforma centrada en Apache Spark, por lo que deberemos considerar también los servicios de Azure y tecnologías complementarias que necesitaremos para tener una solución analítica completa, por ejemplo con Apache Kafka o Delta Lake.
Siguientes Pasos y Formación
Aquí tienes 2 cursos que te recomiendo para aprender más sobre Azure HDInsight con los que ampliar y consolidar tu conocimiento:

Aprende Azure HDInsight en 2 horas
Este curso te enseñará los conceptos básicos de Azure HDI en muy poco tiempo. Podrás aprender a desplegar los componentes de Hadoop en la nube de Azure.

Hadoop en Azure. Introducción al Big Data usando HDInsight
Curso para principiantes que deseen aprender sobre la solución Big Data de Hadoop en Azure que propone Microsoft con HDI. Se trata de una visión de alto nivel.
También tienes estas 3 publicaciones para que puedas seguir aprendiendo sobre Big Data en Azure y HDInsight:
- Azure HDInsight A Complete Guide
- Mastering Azure Analytics: Architecting in the Cloud with Azure Data Lake, HDInsight, and Spark
- Processing Big Data with Azure HDInsight
Preguntas Frecuentes de Azure HDInsight – FAQ
¿Qué componentes tiene Azure HDInsight?
Azure HDInsight tiene 5 tipos de clusters: Hadoop, Spark, Interactive Query (Hive LLAP), HBase y Kafka. Estos clusters se pueden desplegar según las necesidades que tenga el proyecto.
¿Cómo se almacenan los datos en Azure HDInsight?
HDInsight es compatible con las opciones de almacenamiento de Azure como ADLS (Azure Data Lake Storage) y Azure Storage. Generalmente los clusters de Azure HDI no despliegan el servicio de HDFS, sino que proporcionan una interfaz para que los componentes de Hadoop usen el almacenamiento de Azure.
¿En qué se diferencia Azure HDInsight de Databricks?
Azure HDInsight nos proporciona muchas tecnologías del ecosistema hadoop en sus tipologías de clusters. Databricks está centrada en Apache Spark, por lo que serán necesarias tecnologías complementarias para proporcionar una solución analítica completa.
A continuación, un breve vídeo-resumen. ¡No te lo pierdas!

Arquitecto de Datos con más de 10 años de experiencia en el sector del Big Data. Autor de cursos de formación en tecnologías Big Data, Cloud y Streaming completados por más de 7000 alumnos en Udemy y otras plataformas. Miembro de la Apache Software Foundation desde 2019.


