En esta entrada vamos a explicar en qué consiste MapReduce de Hadoop y su aplicación en el procesamiento de grandes cantidades de datos para Big Data.

En estos artículos tenemos la introducción a los otros dos componentes de Apache Hadoop:
Contenidos
¿Qué es MapReduce?
Anteriormente, en los sistemas tradicionales, las tecnologías se han enfocado en traer los datos a los sistemas de almacenamiento. Sin embargo, en los procesos Hadoop, se trata de acercar el procesamiento al lugar en donde se encuentran almacenados los datos y así aprovechar técnicas de paralelización, aumentando de manera importante la escalabilidad y el rendimiento de los sistemas que trabajan con grandes cantidades de datos.
Hadoop MapReduce es un paradigma de procesamiento de datos caracterizado por dividirse en dos fases o pasos diferenciados: Map y Reduce. Estos subprocesos asociados a la tarea se ejecutan de manera distribuida, en diferentes nodos de procesamiento o esclavos. Para controlar y gestionar su ejecución, existe un proceso Master o Job Tracker. También es el encargado de aceptar los nuevos trabajos enviados al sistema por los clientes.
Este sistema de procesamiento se apoya en tecnologías de almacenamiento de datos distribuidas, en cuyos nodos se ejecutan estas operaciones de tipo map y reduce. El sistema de ficheros distribuido de Hadoop es HDFS (Hadoop Distributed File System), encargado de almacenar los ficheros divididos en bloques de datos. HDFS proporciona la división previa de los datos en bloques que necesita MapReduce para ejecutar. Los resultados del procesamiento se pueden almacenar en el mismo sistema de almacenamiento o bien en una base de datos o sistema externo.
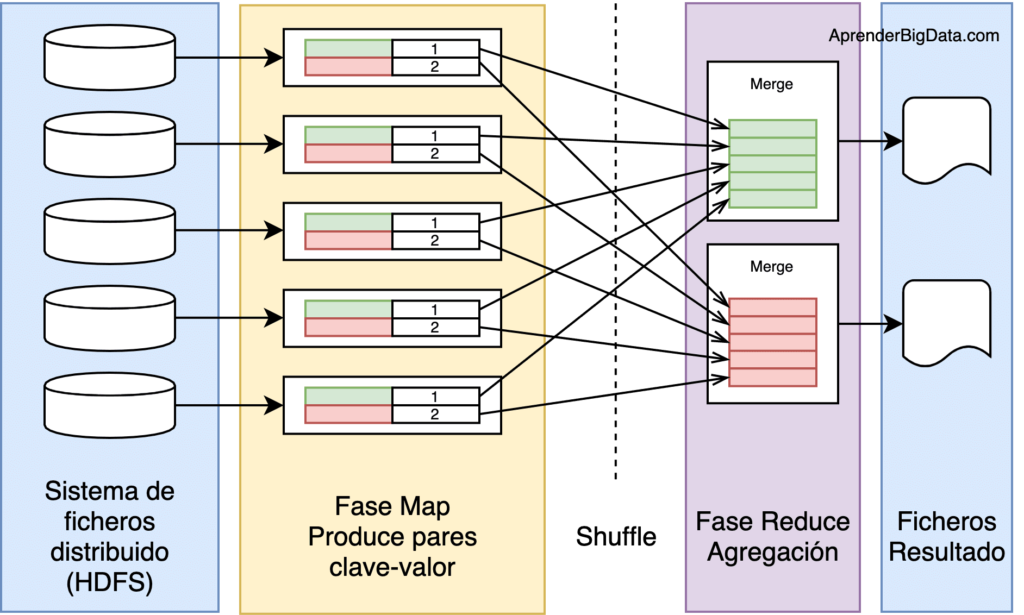
Fases en Hadoop MapReduce
En un trabajo Hadoop MapReduce, se dividen los datos de entrada en fragmentos independientes que son procesados por los mappers en paralelo. A continuación, se ordenan los resultados del map, que son la entrada para los reducers. Generalmente, las entradas y salidas de los trabajos se almacenan en un sistema de ficheros, siendo los nodos de almacenamiento y de cómputo los mismos. También es muy común que la lógica de la aplicación no se pueda descomponer en una única ejecución de MapReduce, por lo que se encadenan varias de estas fases, tratando los resultados de una como entrada para los mappers de la siguiente fase.
Esta característica, permite ejecutar las tareas de cada fragmento en el nodo donde se almacena, reduciendo el tiempo de acceso a los datos y los movimientos entre nodos del clúster.
El framework también se encarga de gestionar los recursos, planificar, reiniciar y monitorizar las tareas con el gestor de Hadoop YARN, que tiene un único Resource Manager y un Node Manager en cada nodo del clúster.
¿Quieres Convertirte en Ingeniero de Datos?
La fase Map se ejecuta en subtareas llamadas mappers. Estos componentes son los responsables de generar pares clave-valor filtrando, agrupando, ordenando o transformando los datos originales. Los pares de datos intermedios, no se almacenan en HDFS.
La fase Shuffle (sort) puede no ser necesaria. Es el paso intermedio entre Map y reduce que ayuda a recoger los datos y ordenarlos de manera conveniente para el procesamiento. Con esta fase, se pretende agregar las ocurrencias repetidas en cada uno de los mappers.
La fase Reduce gestiona la agregación de los valores producidos por todos los mappers del sistema (o por la fase shuffle) de tipo clave-valor en función de su clave. Por último, cada reducer genera su fichero de salida de forma independiente, generalmente escrito en HDFS.
Limitaciones en Hadoop MapReduce
MapReduce es la implementación básica de un framework de procesamiento en paralelo para cargas big data. Sin embargo, tiene ciertas limitaciones que otras tecnologías intentan mejorar.
En MapReduce, hasta que la fase map completa su procesamiento, los reducers no empiezan a ejecutar. Tampoco se puede controlar su orden de ejecución. Entre las alternativas, se encuentran Apache Spark, Apache Hive o Pig. Aunque las ideas principales se mantienen respecto a MapReduce, son capaces de usar HDFS de manera más eficiente para determinados tipos de trabajos. Por lo tanto, debemos conocer estas tecnologías y ser capaces de seleccionar la más adecuada para nuestro caso.
Ejemplo de programa Hadoop MapReduce con código Java
El ejemplo más común de una aplicación MapReduce es el Word Count. Consiste en contar las ocurrencias de cada palabra en un conjunto de documentos. El lenguaje principal para programar trabajos Hadoop MapReduce en HDFS es Java.
El programa se divide en 3 componentes: el driver (punto de entrada de la aplicación), la implementación del mapper y la implementación del reducer.
A continuación, se detalla el código mínimo de cada componente. Estos fragmentos de código carecen de todas las funcionalidades deseables para funcionar en un entorno Hadoop, pero son muy útiles para demostrar la forma de programar con el paradigma MapReduce y cómo descomponer una aplicación para ajustarse al framework.
Las funciones que representan map y reduce deben ser serializables, para lo que se implementan dos interfaces proporcionadas por Hadoop
Implementación del Driver
El método main especifica las rutas y los formatos de entrada y de salida y los tipos de los pares claves/valor que se van a utilizar. Por último, con el método waitForCompletion envía el trabajo y monitoriza el progreso.
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf, "Ejemplo Word Count");
job.setJarByClass(WordCount.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
Path outputPath = new Path(args[1]);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
outputPath.getFileSystem(conf).delete(outputPath);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
Implementación de Map (Mapper)
El mapper procesa una línea del texto, que divide por palabras separadas por espacios, y posteriormente emite un par de clave-valor, siempre de la forma <palabra, 1>.
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
Implementación de Reduce (Reducer)
La implementación del reducer se centra solamente en sumar los valores, es decir, las ocurrencias de cada clave. En este ejemplo son las palabras.
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
Siguientes Pasos, Formación y Cursos de MapReduce
Aprende Hadoop MapReduce a fondo con el siguiente curso recomendado. Está disponible en Coursera y ofrecido por la Universidad de San Diego. Con este curso aprenderás los conceptos clave de Hadoop MapReduce. La ventaja es que podrás ir al ritmo que consideres adecuado, tanto en las clases de teoría como en los ejercicios y laboratorios que tendrás disponibles.
Curso completo de la Plataforma Hadoop
Curso muy recomendado con el que consolidarás conceptos fundamentales para convertirte en experto. Se divide en 4 módulos con 26 horas de contenido:
- Fundamentos de Hadoop
- Stack de Hadoop
- HDFS
- MapReduce
- Apache Spark
También, te recomiendo leer el siguiente libro:
Preguntas frecuentes – FAQ
¿Qué es MapReduce en Hadoop?
MapReduce es el paradigma de programación y de procesamiento de Hadoop. Consiste en dividir el trabajo en múltiples tareas independientes que se pueden paralelizar para procesar cantidades masivas de datos en un clúster.
¿Cuál es la diferencia entre MapReduce y Yarn?
Yarn es el componente de Hadoop responsable de la gestión de los recursos del clúster y de la planificación de los trabajos. Estos trabajos, pueden ser de tipo mapReduce, que es el framework de programación paralela en Hadoop e indica cómo realizar el procesamiento.
¿Cuáles son los componentes de un trabajo MapReduce?
Un trabajo o programa MapReduce se divide en tres componentes principales. El driver es el punto de entrada y define la parametrización y el entorno. La clase mapper es responsable de la primera fase y se encarga de filtrar y de transformar cada dato original generando un par clave-valor. Por último, la clase reducer se encarga de agregar los resultados producidos por los mappers mediante su clave.
¿Spark usa MapReduce?
MapReduce está diseñado para usar el disco como sistema de almacenamiento, mientras que Apache Spark usa memoria, y de esta forma acelera el procesamiento. Apache Spark también puede usar el disco al igual que Hadoop MapReduce.
A continuación el vídeo-resumen. ¡No te lo pierdas!

Arquitecto de Datos con más de 10 años de experiencia en el sector del Big Data. Autor de cursos de formación en tecnologías Big Data, Cloud y Streaming completados por más de 7000 alumnos en Udemy y otras plataformas. Miembro de la Apache Software Foundation desde 2019.


