Esta entrada pretender ser un punto de partida para aprender los conceptos básicos de Apache Hadoop, su relación con el Big Data y cuáles son sus componentes principales y casos de uso. ¡No te lo pierdas!

Contenidos
¿Qué es Apache Hadoop?
Debemos entender que Apache Hadoop es un framework de software que aporta la capacidad de ejecutar aplicaciones distribuidas y escalables, generalmente para el sector del Big Data. Así, permite a las aplicaciones hacer uso de miles de nodos de procesamiento y almacenamiento y petabytes de datos.
Hadoop es una de las tecnologías más populares en el ámbito de aplicaciones Big Data. Es usado en multitud de empresas como plataforma central en sus Data Lakes (Lagos de datos), sobre la que se construyen los casos de uso alrededor de la explotación y el almacenamiento de los datos.
Además, es una plataforma sobre la que desarrollar para sacar partido a los datos de las organizaciones, por ejemplo mediante técnicas y modelos de machine learning.
Entre sus principales ventajas se encuentra el hecho de que está diseñado para ejecutar sobre hardware sencillo, normal y corriente. La potencia del sistema se encuentra en que todos los nodos juntos actúan como un clúster con la capacidad de escalar horizontalmente al agregar más nodos.
Historia
En el año 2006, los dos componentes que formaban parte de Hadoop: MapReduce y HDFS se cedieron a la Apache Software Foundation como proyecto open source. Esto impulsó su adopción como herramienta Big Data en proyectos en muchas industrias. El proyecto fue desarrollado en el lenguaje de programación Java.
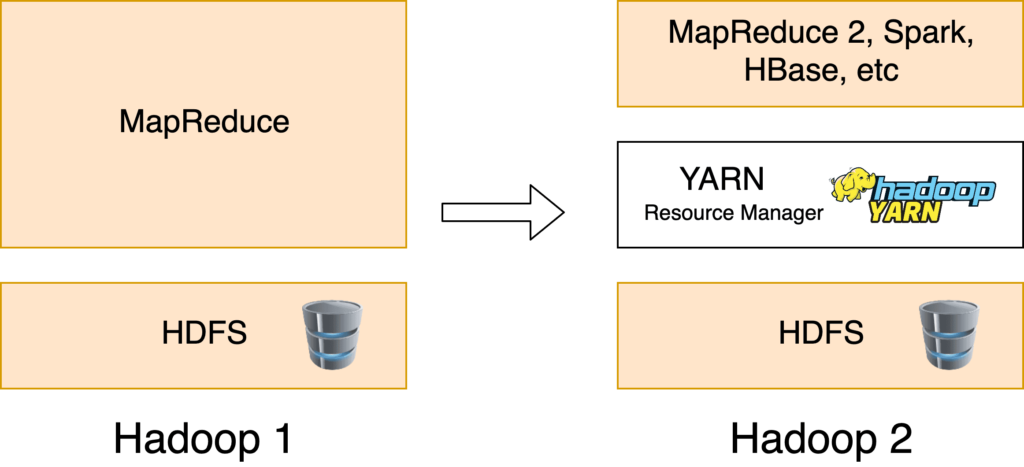
La versión 1.0 de Hadoop fue publicada en el año 2012. La versión 2.0 se publicó en el año 2013 añadiendo Yarn como gestor de recursos y desacoplando HDFS de MapReduce. En el año 2017 se publicó Hadoop 3.0 añadiendo mejoras.
Arquitectura de Hadoop
Anteriormente, en los sistemas tradicionales, las tecnologías se han enfocado en traer los datos a los sistemas de almacenamiento. Sin embargo, en los procesos Hadoop, se trata de acercar el procesamiento al lugar en donde se encuentran almacenados los datos y así aprovechar técnicas de paralelización, aumentando de manera importante la escalabilidad y el rendimiento de los sistemas que trabajan con grandes cantidades de datos.
¿Quieres Convertirte en Ingeniero de Datos?
La arquitectura de Hadoop y su diseño está basado en la idea de que mover el procesamiento es mucho más rápido, fácil y eficiente que mover grandes cantidades de datos, que pueden producir altas latencias y congestión en la red. El sistema de ficheros distribuido de Hadoop (HDFS) proporciona a las aplicaciones la capacidad de acceder a los datos en el lugar en el que se encuentren almacenados.
Componentes Principales
Para comprender completamente cómo funciona Hadoop debemos entender sus tres componentes principales. Hemos dedicado una entrada a cada uno de ellos:
Además de estos componentes, el módulo Hadoop Common aporta las utilidades y librerías comunes del proyecto que soportan el resto de componentes y permiten desarrollar las aplicaciones.
HDFS (Hadoop Distributed File System) es el componente principal del ecosistema Hadoop. Esta pieza hace posible almacenar data sets masivos con tipos de datos estructurados, semi-estructurados y no estructurados. Proporciona la división de los datos en bloques que necesita MapReduce para ejecutar sus fases map y reduce. Está optimizado para almacenar grandes cantidades de datos y mantener varias copias en el clúster para garantizar una alta disponibilidad y tolerancia a fallos.
Por último, Yarn (Yet Another Resource Negotiator) es una pieza fundamental en el ecosistema Hadoop. Es el framework que permite soportar varios motores de ejecución incluyendo MapReduce, y que proporciona un planificador agnóstico a los trabajos que se encuentran en ejecución en el clúster. También se encarga de proporcionar los recursos computacionales necesarios para los trabajos como memoria o cpu.
Ecosistema Hadoop
Alrededor del framework de Hadoop, compuesto por las tres piezas fundamentales: MapReduce, HDFS y Yarn, han surgido todo un conjunto de tecnologías que la complementan y cumplen funciones específicas. Por ejemplo existen tecnologías que facilitan la ingesta de datos hacia el clúster de Hadoop, otras que aceleran el procesamiento o bien facilitan la búsqueda de datos.
En cuanto a las distribuciones de Hadoop, la distribución más extendida y usada en la actualidad es Cloudera. Tras la fusión con Hortonworks se ha convertido en líder de mercado. Se ha encargado de agrupar e integran gran cantidad de estas tecnologías para poder realizar los despliegues de lagos de datos de una manera sencilla y acorde a las necesidades.

Tecnologías relacionadas
Los proyectos open source más populares del ecosistema formado alrededor de Apache Hadoop seguramente te sonarán. Se trata de los siguientes:
- Spark: Motor de procesamiento en memoria compatible con HDFS. Aumenta la velocidad de MapReduce en 100 veces. Soporta aplicaciones ETL, Machine learning y Streaming de datos así como consultas SQL.
- Ambari: Herramienta para gestionar y provisionar clústers de Apache Hadoop y tecnologías relacionadas. Proporciona una interfaz web sencilla y amigable para visualizar y monitorizar el estado del sistema y de todos sus componentes, así como establecer alertas y visualizar estadísticas.
- Oozie: Permite ejecutar y planificar en el tiempo trabajos y tareas en Hadoop mediante configuraciones XML.
- Pig: Proporciona el lenguaje de programación Pig Latin, con sintaxis parecida a SQL. Transforma los programas en sentencias MapReduce que ejecutan en un clúster Hadoop.
- Storm: Componente encargado de procesar flujos de datos en tiempo real. Su uso suele ir acompañado de Apache Kafka.
- Tez: Framework de programación de flujos de datos. Es la evolución de MapReduce que ejecuta sobre Yarn optimizando el código para alcanzar mejoras de hasta 10 veces en el rendimiento. Muchas tecnologías están adoptando Tez como motor de ejecución principal.
- Zookeeper: Servicio de coordinación para aplicaciones distribuidas, tolerante a fallos. Generalmente, se despliega en 3 nodos.
Consulta de datos
- Hive: Proporciona la interfaz SQL a Hadoop necesaria para convertirse en un Data Warehouse. Transforma las consultas SQL en trabajos MapReduce sobre datos estructurados. Hive no es apropiado para realizar consultas de baja latencia.
- HBase: Base de datos NoSQL distribuida y escalable para datos estructurados sobre HDFS con formato de columnas y operaciones CRUD (Create, Read, Update, Delete).
- Hue: Permite escribir consultas SQL y conectar con los catálogos y con las bases de datos del clúster para analizar datos de forma interactiva.
- Impala: Base de datos SQL sobre Hadoop. Proporciona la capacidad de realizar consultas concurrentes y de baja latencia para analítica y Business Intelligence (BI).
Ingesta de datos
Además de estas tecnologías, debemos comprender el conjunto de tecnologías que se usan para introducir datos en un clúster Hadoop. Este proceso se llama ingesta de datos y generalmente se lleva a cabo por una combinación de los siguientes componentes:
- Flume: Actúa como buffer para introducir datos en el lago.
- Sqoop: Herramienta especializada para ingestas de datos con fuente en bases de datos externas y con destino HDFS.
- Kafka: Sistema muy usado con un modelo pub-sub que divide los datos en temas con bajas latencias. Los consumidores pueden suscribirse para recibir los mensajes.
Alternativas a Hadoop
Para evaluar las alternativas a Hadoop que existen en el mercado debemos tener en cuenta que menudo podemos integrar diversas tecnologías para resolver el problema que se nos plantea.
Apache Hadoop ha formado todo un ecosistema alrededor muy flexible, del que debemos seleccionar solamente los componentes que necesitemos para evitar recargar nuestro sistema con piezas a las que no se va a sacar partido.
Podemos poner el conocido Hadoop vs Spark como ejemplo. Ambas tecnologías pueden convivir perfectamente en una solución Big Data completa. HDFS proporcionarán la base sobre la que podrán ejecutar las cargas Spark en el caso de que necesitemos realizar transformaciones de los datos complejas. De esta forma, nos podremos aprovechar de un sistema de almacenamiento distribuido y con las réplicas necesarias para garantizar la alta disponibilidad del dato.
Servicios Cloud
No debemos olvidar que los proveedores cloud como AWS o Azure proporcionan servicios gestionados basados en Apache Hadoop. Por ejemplo, con el servicio HDInsight de Microsoft Azure, podemos desplegar y escalar clústers de varios tipos predefinidos de una manera sencilla y transparente. Con EMR, en AWS, podemos desplegar el ecosistema de Hadoop. Estos servicios tienen muchas ventajas asociadas al ahorro de costes de infraestructura y de gestión y es importante analizarlos.
Además de su uso como servicio, podemos considerar alternativas basadas en la nube como Databricks. Este servicio proporciona Spark como servicio, pudiendo desplegar clústers y cargas de trabajo bajo demanda y con escalabilidad automática. Tenemos que tener en cuenta que este tipo de soluciones resuelven el problema del procesamiento de nuestros datos pero no proporcionan el sistema de almacenamiento como HDFS.
Si el objetivo es obtener una plataforma del dato como Data Warehouse totalmente gestionado se pueden evaluar otras soluciones como Snowflake. Esto permite abstraer aún más el despliegue al ser software como servicio. Hadoop no se trata de una base de datos NoSQL y tiene unos costes asociados a su complejidad.
¿Cómo integrar Hadoop en tu empresa?
Si deseas integrar Hadoop en tu empresa, ten en cuenta las siguientes consideraciones, pasos y mejores prácticas
- Define el uso: Usa metas pequeñas y alcanzables que ayuden a procesar los datos. Comienza por definir las formas de acceder a los datos que necesitan los usuarios.
- Calidad del dato: Debemos monitorizar Hadoop como cualquier otra herramienta más en la organización.
- Uso de frameworks existentes: No es necesario inventar nuevos métodos, usa frameworks que ya existen en tu organización para supervisar el acceso a los datos como Spring. De esta forma, los desarrolladores podrán centrarse en la lógica de negocio y en implementar nuevas estrategias.
- Linaje de datos: Debemos realizar un seguimiento del linaje de los datos a través de sus metadatos. Existen herramientas que permiten realizar este seguimiento desde el origen hasta el destino.
- Modelado de datos: Modela los datos de acuerdo a los patrones de procesamiento y de acceso.
- Seguridad: Implementa seguridad de acceso basada en Active Directory y LDAP. Refuerza la seguridad del clúster con servicios como Sentry.
Siguientes Pasos, Formación y Cursos de Hadoop
Aquí tienes dos cursos muy recomendados con los que consolidarás conceptos fundamentales para convertirte en experto de estas tecnologías fundamentales para los ingenieros de datos.
Curso completo de la Plataforma Hadoop
Aprende Hadoop a fondo con este. Está disponible en Coursera y ofrecido por la Universidad de San Diego. Con este curso aprenderás los conceptos clave de Hadoop MapReduce. La ventaja es que podrás ir al ritmo que consideres adecuado, tanto en las clases de teoría como en los ejercicios y laboratorios que tendrás disponibles. Se divide en 4 módulos con 26 horas de contenido que ya han cursado más de 140000 estudiantes.
- Fundamentos de Hadoop
- Stack de Hadoop
- HDFS
- MapReduce
- Apache Spark

Introducción a Big Data con Hadoop y Spark
En este curso ofrecido por IBM en Coursera podrás aprender los conceptos básicos de Hadoop y spark aplicando ejemplos. Cuenta con más de 11 horas de contenido y más de 6000 estudiantes. Se divide en 6 módulos:
- Qué es Big Data
- Introducción al ecosistema Hadoop
- Apache Spark
- Dataframes y Spark SQL
- Desarrollo y Runtime
- Monitorización y configuración
También tienes mi libro favorito de Hadoop:
Preguntas frecuentes – FAQ
¿Para qué sirve Hadoop?
El uso principal de Hadoop es de almacenar y procesar grandes cantidades de datos (Big Data). Proporciona un framework con alta disponibilidad, escalabilidad y tolerancia a fallos, lo que la convierten en una buena solución para convertirse en lagos de datos para organizaciones.
¿Cómo funciona Hadoop?
Hadoop es un sistema distribuido con tres componentes principales: HDFS, MapReduce y Yarn. HDFS proporciona el sistema de ficheros distribuido dividiendo los ficheros de datos en bloques. MapReduce es el modelo de procesamiento dividiendo el trabajo en múltiples tareas independientes y paralelizables. Yarn se encarga de planificar los trabajos y de gestionar los recursos hardware.
A continuación, te dejo un vídeo-resumen con las mejores prácticas para integrar Hadoop en la empresa:

Arquitecto de Datos con más de 10 años de experiencia en el sector del Big Data. Autor de cursos de formación en tecnologías Big Data, Cloud y Streaming completados por más de 7000 alumnos en Udemy y otras plataformas. Miembro de la Apache Software Foundation desde 2019.


