En este artículo aprenderás qué es Apache HBase y cómo hacer NoSQL en Hadoop. Sigue leyendo par conocer sus características, su arquitectura y las ventajas que tiene como base de datos NoSQL distribuida.

Contenidos
¿Qué es HBase?
HBase es una base de datos NoSQL de tipo clave-valor o columnar distribuida que ejecuta sobre HDFS (Hadoop Distributed File System). Proporciona una capa para acceder y actualizar los ficheros de datos en formato estructurado con operaciones CRUD (Create, Read, Update, Delete).
Nos aporta lecturas de datos muy rápidas y está pensada para arquitecturas y sistemas de datos que escriben una vez y leen muchas veces. Eso es debido a que cuando se escriben ficheros en HDFS no se pueden modificar, pero si acceder a ellos con un gran rendimiento.
Apache HBase es un proyecto open source de la Apache Software Foundation que comenzó en el 2008 como un subproyecto de Hadoop. Está escrito en el lenguaje de programación Java.
Modelo de Datos
El modelo de datos está basado en Google Big Table, por lo que es muy similar. Está diseñado para proporcionar acceso aleatorio a una gran cantidad de datos estructurados.
En HBase los datos se dividen en tablas. Estas tablas, tienen filas que representan los datos. Cada fila tiene una clave que actúa de identificador único y que divide las tablas en regiones. Esta clave de fila es un array de bytes.

Como en una base de datos relacional o SQL, las columnas representan los atributos. Las columnas se agrupan en familias de columnas (con valores semánticos relacionados), que se almacenan en los ficheros de HDFS denominados HFiles. Cuando no tiene un valor, una columna no se almacena ni se reserva ese espacio.
Cada familia de columas puede tener millones de columnas. Los usuarios pueden crear más en cualquier momento.
Arquitectura y Componentes
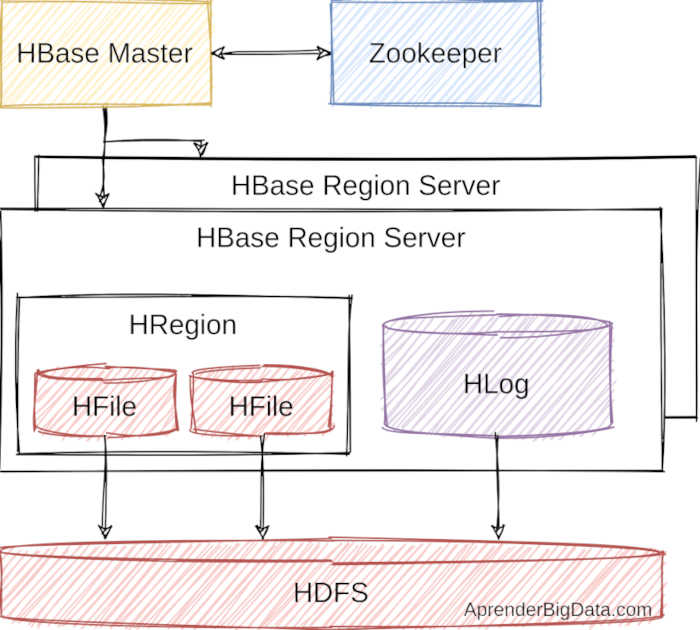
HBase tiene una arquitectura de tipo maestro-esclavo (master-slave) y se puede desplegar en decenas y cientos de nodos.

HBase Master: Es el componente responsable de asignar las regiones en las que se encuentran distribuidos los datos en los nodos del clúster. Para ello, particiona el espacio de claves de las tablas y asigna las regiones resultantes a los servidores de regiones (Region Servers). También, mantiene la carga balanceada reasignando regiones a los nodos.
El Master es el punto de entrada para las peticiones de los usuarios, las cuales redirige al Region Server correspondiente. También controla los fallos que se producen en el sistema. Es posible ejecutar varios Master para habilitar alta disponibilidad.
¿Quieres Convertirte en Ingeniero de Datos?
Region Server: Este componente ejecuta en todos los nodos workers del cluster y aloja las regiones. Tiene una caché de bloques que contiene los datos que se acceden con más frecuencia para optimizar las consultas (BlockCache). También gestiona una caché de escritura en memoria (MemStore) que aloja los datos que aún no han persistido en el disco. Además, contiene el log de escritura o WAL (Write-ahead log). Cuando el MemStore acumula suficientes datos se persisten en un nuevo HFile con la operación de Flush.
Zookeeper: Apache Zookeeper es el coordinador del clúster de HBase. Contiene la configuración de los nodos y actúa también en caso de detectar un fallo mediante un demonio de monitorización. El HBase Master hace el seguimiento de los Region Servers con la información que mantiene Zookeeper.
Características de HBase
Escalabilidad Horizontal: HBase usa sharding automático para distribuir sus tablas de datos en regiones, que son las unidades de balanceo de carga y de distribución en los nodos del clúster. Las regiones también pueden combinarse o dividirse en las operaciones de balanceo.
Tolerancia a Fallos: HBase se puede recuperar automáticamente en caso de fallos en regiones. Cuando el HBase Master detecta un fallo en un Region Server, reasigna esas regiones a un nuevo Region Server. Los datos no persistidos se recuperan directamente del HLog. Por otro lado, los fallos en nodos de HDFS son transparentes, ya que HDFS se encarga de replicarlos.
Consistencia de datos: Proporciona consistencia fuerte de los datos, tanto en lecturas como en escrituras, por lo que siempre se devolverá un dato actualizado. Las operaciones de escritura no terminarán satisfactoriamente hasta que todas las réplicas del dato hayan sido actualizadas correctamente.
Ventajas
HBase se integra perfectamente con aplicaciones en HDFS y MapReduce como fuente o como destino de datos. Mitiga los problemas de HDFS proporcionándonos actualizaciones sobre los datos, así como lecturas y escrituras aleatorias con buen rendimiento. También, nos proporciona una API en Java, una API Rest y con Thrift muy flexible.
Desventajas
No debemos usar HBase cuando no tenemos suficientes datos para compensar su complejidad y arquitectura distribuida. Es un sistema pensado para almacenar millones de filas. También, debemos tener en cuenta para dimensionar nuestra base de datos la velocidad a la que se generarán datos en el futuro o lo que crecerá nuestro dataset a almacenar.
Debemos prestar atención al mecanismo de compactación de datos, que puede afectar también a nuestras operaciones. Este mecanismo permite optimizar nuestros HFiles agrupándolos y reescribiéndolos para aumentar el rendimiento de las consultas.
Ejemplo Sencillo en HBase
Podemos usar la shell de nuestro sistema para interactuar con la API de HBase fácilmente. Para ejecutar la shell (en Linux), nos moveremos al directorio bin dentro del directorio de instalación y ejecutaremos el comando ‘hbase shell’.
En este ejemplo, vamos a crear una tabla llamada clientes con dos familias de columnas: localizacion y personal. Usamos el comando create:
create 'clientes', 'localizacion', 'personal'
Para insertar datos en la tabla de forma individual usaremos put. Deberemos especificar el nombre de la columna junto a su familia de columas separados por dos puntos (:).
put 'clientes', 'r1', 'localizacion:ciudad', 'Madrid'
put 'clientes', 'r1', 'personal:nombre', 'Oscar'
put 'clientes', 'r1', 'personal:edad', '28'
Para realizar una consulta de lectura de tipo get sobre nuestra tabla, especificaremos el identificador de la fila.
get 'clientes', 'r1', {COLUMN => 'personal:edad'}
Formación y Cursos de HBase
A continuación tienes mi cursos favorito de HBase en Udemy con el que aprenderás a usar HBase completamente y desde cero. Es muy recomendable y lo podrás completar rápidamente.

Aprende con ejemplos: HBase: la base de datos de Hadoop
Este curso de 5 horas ofrece 25 ejemplos para que aprendas todo sobre HBase. Trabajar con tablas e integrar con aplicaciones para que tengas una visión completa de esta tecnología.
Preguntas Frecuentes de HBase – FAQ
¿Para qué se usa Apache HBase?
Apache HBase se usa como una base de datos NoSQL orientada a columnas sobre el sistema de ficheros distribuido de Hadoop: HDFS. Nos permite almacenar grandes cantidades de datos estructurados de una manera eficiente, tolerante a fallos y escalable. Además, nos proporciona acceso rápido de lectura y de escritura por clave.
¿Cuál es la diferencia entre Apache Hive y Apache HBase?
Apache Hive es un motor de consulta analítica SQL que transforma las consultas en trabajos de Hadoop. Apache HBase es una base de datos que ejecuta las consultas en tiempo real. Ambas tecnologías usan HDFS como capa de almacenamiento de los datos.
¿En qué se diferencia Apache HBase de Apache Cassandra?
Apache HBase necesita HDFS y Zookeeper para funcionar, mientras que Apache Cassandra es independiente. Además, HBase tiene una arquitectura con un maestro y Cassandra no tiene maestros ni esclavos.
A continuación, el vídeo-resumen. ¡No te lo pierdas!

Arquitecto de Datos con más de 10 años de experiencia en el sector del Big Data. Autor de cursos de formación en tecnologías Big Data, Cloud y Streaming completados por más de 7000 alumnos en Udemy y otras plataformas. Miembro de la Apache Software Foundation desde 2019.


