En esta entrada realizamos una introducción a Apache Flink repasando sus aspectos clave. En qué consiste esta herramienta de procesamiento en streaming Big Data, cómo funciona y cuál es su arquitectura.

Contenidos
Introducción al Streaming
En la actualidad, los negocios cada vez necesitan interacciones más eficientes para generar ciclos de venta más rápidos. Los servicios en tiempo real y las recomendaciones proactivas se vuelven activos fundamentales para la actividad de negocio. Estos servicios permiten comunicaciones más rápidas con el cliente incluso el uso de notificaciones push en tiempo real.
A continuación se enumeran algunos casos de uso para aplicaciones de streaming de baja latencia bien conocidos:
- Detección de fraude
- Análisis en videojuegos
- Recomendación de contenidos
- Monitorización de redes de telecomunicaciones
- Optimización de búsquedas
- IoT Industrial
- Monitorización de aplicaciones
Las tecnologías de procesamiento y analítica en streaming como Apache Flink proporcionan valor rápidamente. Ingestando y procesando eventos en tiempo real tanto integradas como parte de una aplicación de forma independiente.
También permiten reaccionar y responder a los clientes del negocio con muy baja latencia, mejorando la experiencia de usuario. Esta ventaja es muy usada en los smartphones y aplicaciones móviles. También se puede aprovechar para desarrollar una interacción continua en las redes sociales.
Cuando hablamos de procesamiento en tiempo real o stream analytics debemos tener en cuenta en qué consiste exactamente el tiempo real. En el caso de tiempos de procesamiento superiores a 1 hora, nos encontraríamos en un caso de uso de procesamiento batch. De 10 milisegundos a 1 segundo hablaríamos de procesamiento en tiempo real. Con latencias inferiores a 500 milisegundos, generalmente nos referimos a tecnologías OLTP. Por último, el tiempo real estricto consistiría en obtener latencias inferiores a 1 milisegundo, estas aplicaciones y tecnologías no suelen ser de propósito general.
Aspectos clave de Apache Flink
Apache Flink es un framework de código abierto orientado al procesamiento de flujos de datos en streaming de forma distribuida y con alta disponibilidad. El proyecto surgió en el año 2015. Las características más importantes de Apache Flink son las siguientes:
- Procesamiento de flujos de datos: Permite obtener resultados en tiempo real a partir de flujos de datos.
- Procesamiento Batch: Procesamiento de datos históricos y estáticos.
- Aplicaciones orientadas a eventos: Se pueden realizar acciones y dar servicios a partir de los datos procesados en tiempo real.
Una Tupla en terminología de streaming consiste en un conjunto de elementos o de tipos de datos simples guardados de forma consecutiva. De esta forma, se define un Flujo de datos como una secuencia infinita de tuplas.

Sobre un flujo de datos se pueden realizar dos tipos de operaciones:
Operaciones sin estado (stateless)
Las operaciones sin estado son acciones que obtienen una tupla como resultado de procesar una única tupla de entrada. Los más comunes son los siguientes:
- Map: Transforma el esquema de la tupla en un nuevo esquema.
- Filter: Descarga o enruta las tuplas dependiendo de las condiciones.
- Union: Combina varias secuencias de tuplas que comparten esquema.
Operadores con estado (stateful)
Son capaces de operar sobre N tuplas de entrada para generar una tupla de salida. Los operadores con estado más comunes son los siguientes:
- Agregación: Funciones de agregación.
- Equijoin: Empareja tuplas de dos secuencias con el mismo criterio.
Características de Apache Flink
- Es capaz de procesar datos de entrada fuera de orden o que llegan con retraso (datos tardíos)
- Mantiene el estado de la aplicación, pudiendo gestionar decenas de terabytes de estado (agregación y resumen de datos)
- La garantía de entrega (processing semantics) es de exactamente una vez (exactly once)
Además, Apache Flink es Escalable y soporta miles de nodos manteniendo una latencia baja. Puede escalar el sistema de forma automática (autoscaling), cambiando dinámicamente el paralelismo de los operadores. Estas operaciones de escalado y las actualizaciones no tienen downtime o periodo de inactividad. El clúster de Flink siempre está disponible cuando se realizan cambios en el código, cambios de paralelismo y actualizaciones del framework.
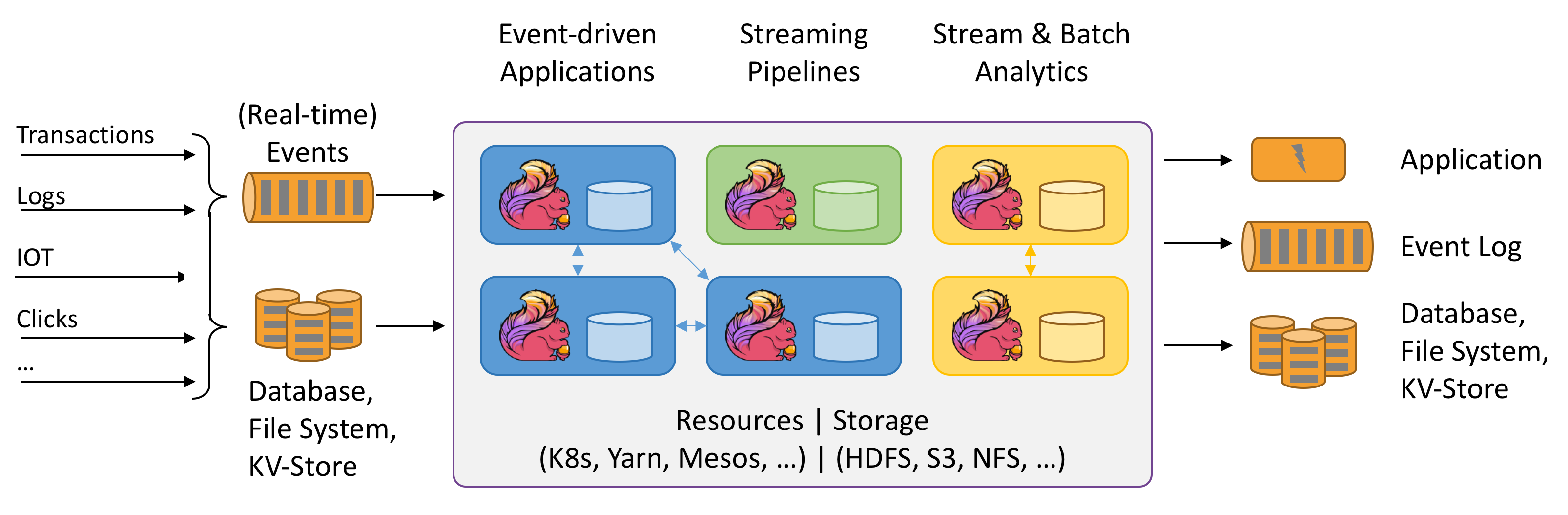
Flink tiene dos mecanismos para asegurar su tolerancia a fallos: los puntos de control o checkpoints y los puntos de guardado o Savepoints.
Los checkpoints se crean de forma transparente en el sistema y son gestionados por Flink. Se usan para recuperar el estado de forma automática cuando ocurren fallos no esperados. Cuando termina el trabajo, los checkpoints también se eliminan.
Los savepoints contienen más datos acerca del estado, los gestiona el usuario y no se eliminan con la terminación del trabajo asociado. Se usan generalmente para controlar las actualizaciones, los cambios de paralelismo y las ventanas de mantenimiento.
Control Temporal de Eventos en Apache Flink
Existen tres controles temporales importantes en Flink:
- Event Time: Momento en el que se creó un evento. Por lo general, se describe mediante una marca de tiempo generada por el sensor o el productor del dato.
- Ingestion Time: Momento en el que un evento ingresa en el flujo de datos de Flink en el origen.
- Processing Time: Tiempo local de cada operador que realiza una operación basada en tiempo.
Las ventanas temporales permiten tratar las secuencias infinitas con unos recursos limitados (memoria) dividiendo los datos de entrada en partes finitas. Se basan en la idea de que sólo los datos más recientes son relevantes.

Pueden estar basadas en tiempo o en el número de elementos y desplazarse por bloques de elementos o de la forma FIFO. El procesamiento en ventanas permite tener varios niveles de paralelismo: Paralelismo entre consultas (escalable por consultas) y paralelismo dentro de consultas (escalable por volumen de eventos).
Las ventanas se crean cuando el primer evento que pertenece a la ventana llega al sistema. La ventana vence cuando el tiempo (de evento o de procesamiento) termina y además pasa el tiempo de retraso máximo definido por el usuario.
Por último, cada ventana tiene un Trigger que especifica las condiciones para que se aplique la función de procesamiento. Existe otro concepto llamado Evictor, que permite controlar el borrado de elementos de la ventana después del trigger.
Tipos de Ventanas
- Tumbling Windows: Ventanas de tamaño fijo en el tiempo. No existe solapamiento entre ventanas de este tipo.
- Sliding Windows: Asignan elementos a ventanas de un tamaño fijo, determinado por el valor Window Size. Se define la frecuencia con la que se añade una nueva ventana deslizante (Window Slide). Estas ventanas pueden solaparse si el deslizamiento es menor al tamaño de la ventana: en este caso los elementos pueden pertenecer a más de una ventana.
- Session Windows: Permiten agrupar los elementos recibidos por claves o sesiones de actividad (user). Cada ventana vence cuando no recibe eventos que pertenezcan a ella durante un período de tiempo fijo llamado Session Gap (período de inactividad). No existe solapamiento ni un tiempo de inicio y de finalización predefinidos.
- Global Windows: Asigna todos los elementos con la misma clave a la misma ventana. Esta ventana solo es útil si se especifica un trigger: si no se especifica un trigger no se procesará nada, ya que no tiene fin.
Para procesar eventos que llegan al sistema con retraso, es posible extender las ventanas un tiempo establecido (de espera). De esta forma la ventana no vence hasta que no se termina este tiempo de espera.
Librerías y Componentes de Flink
Apache Flink tiene dos componentes principales. Por un lado, el Task Manager es el encargado de ejecutar los trabajos de Flink. Por otro lado, el Job Manager se encarga de distribuir estos trabajos en los Task Managers.
- DataStream API: Permite procesar conjuntos infinitos de datos (en modo Streaming).
- DataSet API: Permite procesar conjuntos finitos de datos (en modo Batch)
- Contiene una librería CEP (Complex Event Processing).
- El lenguaje SQL opera sobre unas abstracciones llamadas tablas.
- FlinkML es una librería para implementar algoritmos de Machine Learning.
- FlinkSpector permite definir pruebas unitarias sobre flujos de datos y operadores. Para ello ejecuta flujos de datos localmente y se encarga de verificar los resultados con las expectativas definidas.
Requisitos de Flink
- Java 8
- La API para Scala es opcional y depende de Scala 2.11
- Para tener alta disponibilidad (HA) sin un único punto de fallo depende de Apache Zookeeper
- Para configurar la recuperación ante fallos, Flink necesita alguna forma de almacenamiento distribuido para los checkpoints (HDFS / S3 / NFS / SAN / GFS / Kosmos / Ceph / …)
Despliegue de Apache Flink
Flink tiene un despliegue flexible, pudiendo ejecutar en ecosistemas como YARN, Mesos, Kubernetes, Docker o bien de forma standalone con un despliegue independiente.Flink es independiente de Hadoop pero:
- Se integra bien con HDFS, YARN o HBase
- Flink puede usar HDFS para leer datos o escribir resultados y checkpoints/snapshots
- Se puede desplegar con YARN
- Se integra con los módulos de seguridad de Kerberos de YARN y HDFS
Para ejecutar un trabajo, la manera por defecto es desplegar un fichero JAR con el código compilado junto a sus dependencias en un clúster activo. Este procedimiento se puede mejorar con la ayuda de Docker para aumentar la trazabilidad de los trabajos y orquestarlos con Kubernetes. De esta forma, ejecutando Flink en Kubernetes conseguiremos portabilidad, escalabilidad y mayor opciones de monitorización.
Ejemplo de programa en Flink
A continuación, vamos a escribir un ejemplo de código Java que implementa una aplicación con Flink. La diferencia en el rendimiento con la API de Java y Scala es despreciable. Los pasos que sigue el ejemplo son los siguientes:
- Lee un flujo de números de un topic de Apache Kafka representados con un string y almacenados todos con la misma clave. (líneas 7-10)
- Se define una ventana de tipo Tumbling de 10 segundos. (línea 13)
- Suma los números según se van procesando. (líneas 14-25)
- Imprime los resultados por consola. (línea 26)
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("client.id", "flink-example");
FlinkKafkaConsumer<KafkaRecord> kafkaConsumer = new FlinkKafkaConsumer<>("Topic-1", new MySchema(), props);
kafkaConsumer.setStartFromLatest();
DataStream<KafkaRecord> stream = env.addSource(kafkaConsumer);
stream
.timeWindowAll(Time.seconds(10))
.reduce(new ReduceFunction<KafkaRecord>()
{
KafkaRecord result = new KafkaRecord();
@Override
public KafkaRecord reduce(KafkaRecord record1, KafkaRecord record2) throws Exception
{
result.key = record1.key;
result.value = record1.value + record2.value;
return result;
}
})
.print();
env.execute();
En la línea 7 se crea un objeto del tipo FlinkKafkaConsumer que actúa como fuente de datos del sistema. La clase KafkaRecord es la que define el wrapper para los pares clave valor que devuelve el consumidor de Kafka. La clase MySchema se encarga de proporcionar el deserializador y la conversión de byte[] a string.
Curso recomendado de Apache Flink: Siguientes Pasos
Aprende Apache Flink a fondo con mi curso desde cero. Al final del curso, serás capaz de implementar aplicaciones de procesamiento de datos en tiempo real. El curso te enseñará a desenvolverte con Flink en un entorno profesional e implementar soluciones de datos. Está todo guiado y se compone de lecciones teóricas y prácticas, terminando con un proyecto paso a paso. ¡Aquí abajo tienes un enlace para que puedas aprovechar el cupón!
Apache Flink desde cero: La guía esencial
Preguntas Frecuentes Apache Flink – FAQ
¿Para qué se usa Apache Flink?
Flink es un framework distribuido para procesar flujos de datos manteniendo el estado y con una alta escalabilidad.
¿En qué se diferencia Apache Flink de Apache Spark?
Flink, al contrario que Spark, ha sido diseñado con una arquitectura orientada al procesamiento de eventos en streaming. Por ello, generalmente Flink tiene un mayor rendimiento y procesa a nivel de eventos individuales, sin crear micro-batches como hace Spark Streaming.
¿Apache Flink necesita Hadoop?
Apache Flink no necesita Hadoop ya que es una plataforma de procesamiento independiente. Flink también puede realizar procesamiento batch y usarse con Hadoop.

Arquitecto de Datos con más de 10 años de experiencia en el sector del Big Data. Autor de cursos de formación en tecnologías Big Data, Cloud y Streaming completados por más de 7000 alumnos en Udemy y otras plataformas. Miembro de la Apache Software Foundation desde 2019.


