¿Quieres aprender Apache Impala? En esta entrada veremos en qué consiste esta herramienta de consultas para Big data, muy popular en Cloudera. También, veremos su arquitectura y las ventajas que aporta en los sistemas Big Data.

Contenidos
¿Qué es Apache Impala?
Apache Impala es una herramienta escalable de procesamiento MPP (Massively Parallel Processing). Tiene licencia open source. Fue desarrollada inicialmente por Cloudera y más tarde incluida en la Apache Software Foundation. Está incluida en las distribuciones de Cloudera.
Es muy popular para realizar consultas SQL interactivas con muy baja latencia. Además, soporta múltiples formatos como Parquet, ORC, JSON o Avro y tecnologías de almacenamiento como HDFS, Kudu, Hive, HBase, Amazon S3 o ADLS.
Impala usa los mismos metadatos, la misma sintaxis SQL y el mismo driver que Hive. Además, también se puede usar desde la interfaz de Hue, por lo que se integra perfectamente con el ecosistema de Hadoop.
Impala destaca cuando necesitamos una tecnología que nos proporcione una baja latencia en consultas exploratorias y de descubrimiento de datos. Así, podemos conseguir respuestas en tiempos menores de un segundo.
Arquitectura de Impala
El procesamiento MPP se caracteriza por dividir la consulta en fragmentos y distribuirlos en los nodos. Por lo tanto, para que esta estrategia sea eficiente necesita gran cantidad de datos y que estén distribuidos y particionados de forma adecuada.
Impala usa Hive Metastore para determinar las ubicaciones de los ficheros y de los bloques.
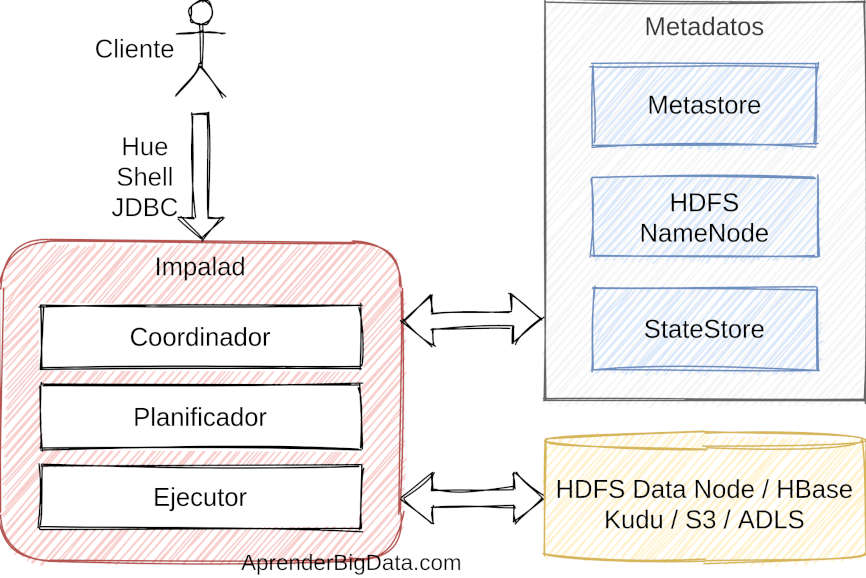
Cuando se realiza una consulta, se procesa en uno de los coordinadores, que inicia su planificación antes de ejecutarla. Una vez que se planifica en los fragmentos de datos correspondientes, el coordinador inicia su ejecución en los datanodes de Hadoop.
Ventajas de Apache Impala
Apache Impala tiene algunas ventajas frente a otras tecnologías de consulta de datos en Hadoop. La ventaja principal es que el demonio de Impala (Impalad) se ejecuta en los datanodes de Hadoop. Este, contiene el coordinador, el planificador y el motor de ejecución de consultas, por lo que gracias a la localidad de los datos se evitan cuellos de botella y se reduce la latencia.
También, Impala utiliza el metastore de Hive, en un formato abierto y que se puede reutilizar en otras tecnologías.
Debido a estos dos puntos no necesita hardware adicional, lo que simplifica el dimensionamiento y despliegue.
Apache Impala vs Hive
Por el diseño y arquitectura de Apache Impala, su rendimiento puede ser superior al de Apache Hive en varios órdenes de magnitud.
Para comparar estas herramientas de forma correcta, debemos considerar Hive LLAP. Ésta, es una tecnología similar a Impala pensada para cargas big data.
Ambas tecnologías son adecuadas en entornos empresariales de Data Warehouse en los que nos podemos encontrar consultas repetitivas pero muy pesadas en su primera ejecución, con transformaciones complejas y joins sobre grandes cantidades de datos.
Hive LLAP es una tecnología cuyos casos de uso están más orientados a realizar consultas y dashboards de BI gracias a sus sistemas de caché.
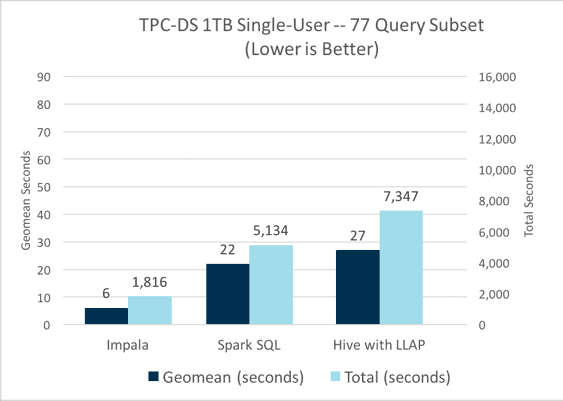
Por otro lado, Impala es una buena solución en entornos de analítica interactiva en los que se requiere el uso de funciones y tienen unos requisitos temporales más estrictos, inferiores a segundos.
Cómo ejecutar Apache Impala en tu sistema Linux
Para ejecutar Apache Impala en un sistema Linux y asegurarse de que funciona correctamente, se pueden seguir los siguientes pasos:
- Instala Apache Hadoop e impala en el sistema Linux, siguiendo las instrucciones específicas para su distribución y versión de Linux. Asegúrate de que Apache Hadoop e Impala estén correctamente configurados y funcionando.
- Inicia el servicio de Apache Impala en el sistema Linux, utilizando el comando
impala-starto el equivalente en tu distribución y versión de Linux. - Conecta a Apache Impala utilizando una herramienta de consulta SQL, como Apache Hue o Apache Drill.
- Realiza pruebas de consultas y análisis de datos en Apache Impala, utilizando datos de prueba o datos reales almacenados en Apache Hadoop.
Ejemplo con Apache Impala
Un ejemplo de Apache Impala funcionando podría ser el siguiente:
Supongamos que se tiene un sistema Apache Hadoop que almacena datos de transacciones comerciales, con información detallada sobre las transacciones, como el monto total, la fecha y hora, el cliente, la región y otros datos relevantes. Además, se ha instalado y configurado Apache Impala en el sistema Linux, y se ha iniciado el servicio.
¿Quieres Convertirte en Ingeniero de Datos?
Para ejecutar Apache Impala y obtener información de los datos de transacciones comerciales, puedes conectarte utilizando una herramienta de consulta SQL como hemos visto. Una vez conectado, se pueden escribir y ejecutar consultas SQL como la siguiente:
SELECT region, SUM(amount) AS total_amount
FROM transactions
GROUP BY region
Esta consulta SQL analiza los datos de transacciones comerciales almacenados en Apache Hadoop, y obtiene el total de ingresos por región, agrupando los datos por región y sumando el monto total de cada transacción. Como resultado, se obtiene una tabla con el total de ingresos por región:
| Region | Total |
|---|---|
| North | $1,500,000 |
| South | $2,000,000 |
| East | $1,200,000 |
| West | $1,800,000 |
Siguientes Pasos y Formación
Aquí tienes un curso específico que te recomiendo para aprender a fondo Impala:

En este curso específico aprenderás a usar Impala en un entorno Big Data de Cloudera y hacer consultas SQL básicas con filtros, agregaciones, joins y subconsultas para analizar los datos. Disponible en Coursera.
Y el mejor libro disponible en inglés:
Preguntas Frecuentes Apache Impala – FAQ
¿Impala es una Base de Datos?
Impala no es una base de datos. Sin embargo, proporciona un motor de consulta SQL para realizar consultas interactivas de baja latencia sobre datos almacenados en HDFS, HBase y otros.
¿Para qué se usa Apache Impala?
Los casos de uso más comunes de Apache Impala son los que necesitan una herramienta para realizar consultas interactivas sobre datos en el ecosistema de Apache Hadoop con menores latencias que Apache Hive.
¿Qué ventajas aporta Impala sobre Hive?
La ventaja principal que aporta Impala sobre Hive es la latencia. Así, puede ser de un orden de magnitud más rápida que Hive, lo que habilita realizar consultas interactivas con respuestas en segundos.
A continuación, el vídeo-resumen. ¡No te lo pierdas!

Arquitecto de Datos con más de 10 años de experiencia en el sector del Big Data. Autor de cursos de formación en tecnologías Big Data, Cloud y Streaming completados por más de 7000 alumnos en Udemy y otras plataformas. Miembro de la Apache Software Foundation desde 2019.


