En esta entrada aprenderás en qué consiste la herramienta Kafka Mirror Maker. Además, veremos cómo le podemos sacar partido al mirroring en nuestros proyectos y 3 ejemplos de arquitecturas multi-clúster con Apache Kafka.

Contenidos
¿Qué es el Mirroring?
En ocasiones necesitaremos desplegar varios clusters de Apache Kafka en nuestra organización. El Mirroring es la técnica que nos permite copiar los datos entre dos o más clusters de Kafka independientes.
A continuación describiré los casos de uso más comunes:
1. Redundancia de Datos
Cuando necesitemos redundancia de datos entre varios clusters. En el caso de que el clúster principal sufra un fallo o una pérdida general de servicio, el clúster de backup o de recuperación podría tomar el control.
De esta forma es posible servir las peticiones de los clientes sin pérdida de servicio en el caso de emergencia.
2. Migraciones de Datos
Las migraciones de datos a entornos cloud son muy comunes. En ocasiones, conviven las aplicaciones cloud y las aplicaciones que ejecutan en infraestructura on-premise.
Para facilitar la migración de Kafka, se procede a realizar un mirroring de a otro clúster que se encuentra desplegado en el entorno cloud.
Los beneficios de este mirroring son que de esta forma se reducen los costes y las latencias. Además, se incrementa la seguridad del sistema al no realizar conexiones hacia las redes internas
3. Diferentes Organizaciones
Cuando tenemos varias organizaciones con clusters independientes podemos requerir también de mirroring. En una misma organización, se puede dar el caso de tener clusters regionales y un clúster central que requiera la información de todos los demás para hacer analítica o reportes de negocio de toda la organización.
Desventajas del Mirroring y de la Replicación de Datos
Debemos tener en cuenta que existen algunos inconvenientes en la replicación de datos entre varios clusters.
Por un lado, las latencias suelen ser altas debido a la distancia entre entornos y las comunicaciones. Además, el ancho de banda suele estar limitado. Por otro lado, se obtendrá un coste mayor asociado a la transferencia de datos.
Debemos evaluar nuestro caso particular para determinar cuál es la mejor estrategia de mirroring que implementar.
Arquitecturas Multi-Clúster con Kafka y Mirror Maker
A continuación, hago un breve resumen de las arquitecturas de Kafka multi-clúster más comunes.
Hub and Spokes
Esta arquitectura consiste en tener un clúster central y varios clusters auxiliares para diferentes organizaciones o regiones dentro de la misma organización.
Cada uno de los clusters locales realiza un mirroring de los datos hacia el clúster central.
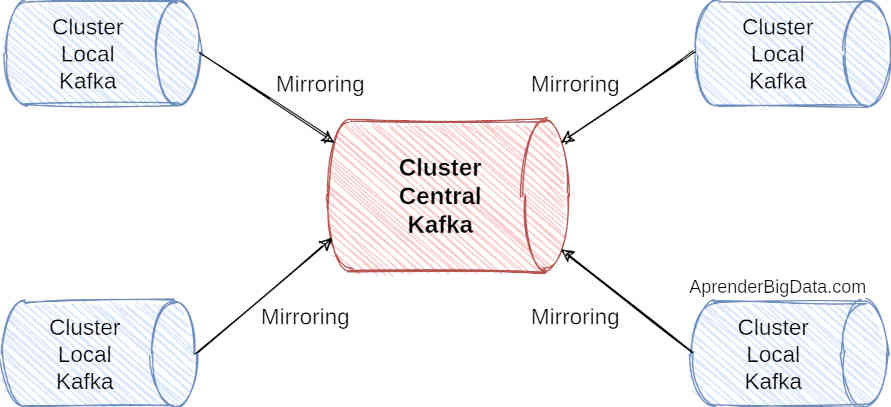
Este modelo, permite que cada clúster local acceda solamente a un subconjunto de la información total de la organización, que además es sobre la que tiene permisos. Esta arquitectura es muy útil en el caso de que los clusters locales no requieran los datos producidos en otros clusters.
Por ejemplo, este modelo se podría dar en un banco. En este caso, cada país o región tendría su propia regulación y produciría sus propios datos. Ahora imaginemos que desde las oficinas centrales se desea tener acceso a todos los datos para realizar procesos de analítica y tomar decisiones de negocio.
Activo-Activo
En la arquitectura Activo-Activo, se tienen dos o más clusters que comparten todos o parte de los datos. Cada uno de los clusters del sistema global consumen y producen datos.

La ventaja de esta arquitectura es que si un clúster sufre un fallo, los datos pueden ser accesibles inmediatamente en otro de ellos.
La desventaja principal es que se necesitan múltiples procesos de mirroring que mantengan la consistencia y la alta disponibilidad del sistema.
Activo-Pasivo
En la arquitectura activo-pasivo, un clúster se encuentra activo y otro en modo standby o inactivo. Esta arquitectura es muy simple y se usa en estrategias de recuperación de desastres.
Todos los datos se copian mediante mirroring desde el clúster activo al inactivo, que sirve como un backup y solamente se activará en el caso de un fallo en el clúster activo para servir a los clientes conectados.
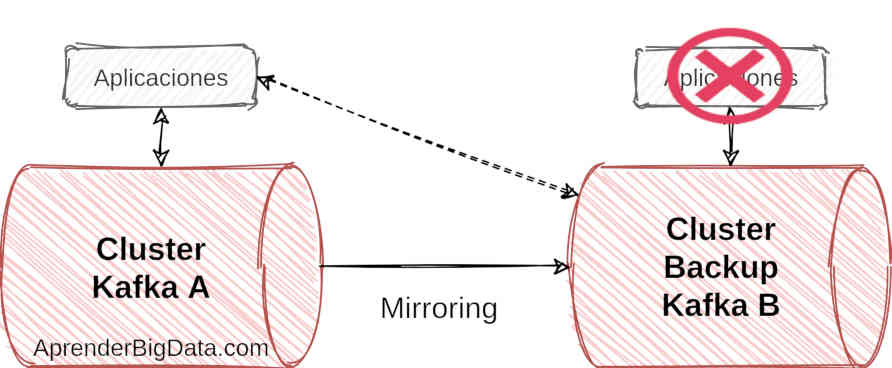
La desventaja principal es que un clúster se encuentra infrautilizado siempre que el otro clúster esté operativo.
Instalación de Kafka Mirror Maker
Mirror Maker es una herramienta incluida en Apache Kafka que nos permite mantener una réplica de los datos de Kafka en otro clúster.
Para probar esta herramienta, necesitaremos dos clusters de Apache Kafka: un clúster fuente y un clúster destino. Vamos a configurar Mirror Maker para replicar datos del clúster fuente al clúster destino.
Si queréis hacer la prueba en vuestra máquina local, bastará con ejecutar dos copias independientes de Kafka y Zookeeper, cada una usando puertos y directorios de log distintos para evitar los conflictos. De esta forma, podemos que están en distintos datacenters.
Aquí, tenéis un artículo sobre los comandos básicos de Apache Kafka que os puede ser de utilidad.
Cómo Configurar y Probar Kafka Mirror Maker
El fichero de configuración de zookeeper es zookeeper.properties. Dentro del directorio config de la instalación de Kafka. El fichero de configuración del broker de Kafka es server.properties, en el directorio config también.
Clúster Origen
- Zookeeper puerto 2181
- Kafka broker(s) puerto 9092
Clúster Destino
- Zookeeper puerto 2182
- Kafka broker(s) puerto 9100
Una vez que los dos clústers se encuentran en ejecución, creamos un topic con el mismo nombre en cada uno.
./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 2 --topic mirrortopic
./bin/kafka-topics.sh --create --zookeeper localhost:2182 --replication-factor 1 --partitions 2 --topic mirrortopic
Ahora, lo que debemos hacer es configurar el consumidor y el productor de Mirror Maker. El consumidor consumirá del clúster fuente y el productor producirá los eventos hacia el clúster destino.
Para ello, en la instalación del clúster destino, tenemos que editar los ficheros de configuración producer.properties y consumer.properties.
Al fichero producer.properties, le indicamos el puerto correspondiente a nuestro clúster destino (9100)
El fichero consumer.properties lo dejamos con los valores por defecto, ya que nuestro clúster origen, del que consumimos, está ejecutando en el puerto 9092
Ahora, ya solo nos queda ejecutar mirrormaker en el clúster destino y comprobar que se replican los datos.
Para ello, desde la instalación del clúster destino ejecutamos el siguiente comando, que indica los ficheros de consumidor y de productor y el topic que queremos replicar.
./bin/kafka-mirror-maker.sh --consumer.config config/consumer.properties --producer.config config/producer.properties --whitelist mirrortopic
Para comprobar que está funcionando, podemos producir mensajes en el clúster origen usando la herramienta productor de consola y leerlos en el clúster destino usando la herramienta de consumidor de consola:
./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic mirrortopic
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9100 --topic mirrortopic --group grupo
Conclusión Kafka Mirror Maker
La herramienta Mirror Maker nos proporciona la capacidad de replicar datos fácilmente entre dos clusters independientes de Apache Kafka.
Esta utilidad, se puede usar para implementar diferentes estrategias de replicación y arquitecturas multi-clúster en función del caso de uso.
Siguientes Pasos y Formación

Preguntas Frecuentes – FAQ
¿Cuáles son los casos de uso comunes para Kafka MirrorMaker?
Recuperación ante desastres: Replicar datos a un cluster en una ubicación diferente para asegurar la continuidad del negocio en caso de fallos. Distribución geográfica de datos: Copiar datos a clusters en diferentes regiones para mejorar la latencia y el acceso local. Carga de trabajo compartida: Distribuir la carga de trabajo entre varios clusters para mejorar el rendimiento y la escalabilidad. Migración de clusters: Transferir datos de un cluster antiguo a uno nuevo sin interrumpir las operaciones.
¿Se puede usar Kafka MirrorMaker para replicar datos entre clusters de diferentes versiones?
Sí, Kafka MirrorMaker puede replicar datos entre clusters de diferentes versiones de Kafka. Sin embargo, se recomienda que las versiones sean compatibles y que se realicen pruebas exhaustivas para asegurar la correcta replicación y funcionamiento.
¿Se pueden replicar solo ciertos temas o particiones específicas con Kafka MirrorMaker?
Sí, Kafka MirrorMaker permite la replicación selectiva de temas y particiones específicas. Esto se puede lograr configurando filtros en los consumidores y productores para incluir solo los temas y particiones deseados.
A continuación, un breve vídeo-resumen. ¡No te lo pierdas!

Arquitecto de Datos con más de 10 años de experiencia en el sector del Big Data. Autor de cursos de formación en tecnologías Big Data, Cloud y Streaming completados por más de 7000 alumnos en Udemy y otras plataformas. Miembro de la Apache Software Foundation desde 2019.


