En este artículo voy explicar en qué consiste la virtualización del dato. Aprenderás sus conceptos fundamentales y los beneficios que aporta en sistemas big data. Además, voy a introducir brevemente la tecnología Denodo, especializada en virtualización del dato a gran escala.

Contenidos
¿Qué es la Virtualización del Dato?
Podemos entender la virtualización del dato como la capa lógica que existe entre las herramientas de explotación del dato y las tecnologías de almacenamiento. Esta capa disponibiliza los datos a las herramientas de explotación sin importar las tecnologías de almacenamiento en las que se encuentre presente el dato, que pueden ser dispares. La virtualización muestra una visión única y en la que no importan los detalles técnicos, en la que se puede centralizar el gobierno y la seguridad del dato.
Los negocios necesitan acceso a numerosas fuentes de información en tiempo real para tomar decisiones acertadas. Estos datos se encuentran alojados en diferentes servicios, por ejemplo silos locales, cloud, páginas web o incluso redes sociales. Con las tecnologías de virtualización del dato, se pueden simplificar las técnicas de integración para tener acceso a los datos de manera uniforme y fácil de explotar.
En 2022, el 60% de las organizaciones implementarán virtualización del dato como una forma clave de entregar los datos en su arquitectura.
Gartner Market Guide for Data Virtualization, 16 November 2018
Los sistemas de virtualización del dato, al contrario que las soluciones ETL, no replican los datos ni realizan movimientos, sino que los mantienen en las fuentes originales. Simplemente exponen la vista integrada a los consumidores de los datos y les proporcionan acceso de lectura y de escritura. De esta forma se reduce el riesgo de errores al mover datos y las cargas de trabajo asociadas. Cuando se realiza una consulta, el sistema de virtualización puede consultar en tiempo real los datos o bien usar mecanismos de caché para responder.
Federación y Orquestación de Datos
A menudo se intercambian los términos virtualización de datos y federación de datos. La diferencia entre los dos es que la virtualización de datos hace solamente referencia a la capa de abstracción que oculta el detalle de dónde se encuentran los datos originalmente. La federación de datos se refiere a agregar datos de diferentes fuentes y mostrarlos bajo una vista y acceso unificados. Por lo tanto, la federación es una funcionalidad de la virtualización.
Por otro lado, la orquestación de los datos (Data orchestration) consiste en virtualizar los datos y exponer apis genéricas para que las aplicaciones sean agnósticas sobre las tecnologías que contienen los datos por debajo.
Beneficios de la Virtualización del Dato
El principal beneficio de la virtualización del dato es que puede actuar como un puente de acceso a los Data Warehouses, Data Lakes y Silos de datos en una organización. Esta solución no requiere un nuevo lugar para almacenar los datos, por lo que los sistemas originales siguen proporcionando el servicio para el que fueron diseñados.
La virtualización del dato permite a los clientes buscar los datos o metadatos que necesiten de una manera sencilla y de forma unificada. También hace posible descubrir los datos que están relacionados o duplicados.
También, estas herramientas facilitan el cumplimiento de la creciente regulación en torno a la seguridad y gobierno del dato como la GDPR. Permiten centralizar estos servicios y poder conseguir trazabilidad de los datos históricos y de las transformaciones que han tenido lugar. Además, existe un componente de seguridad alrededor de sistemas críticos, sobre los que se puede limitar el acceso y las operaciones para evitar problemas.

Otro beneficio de la virtualización del dato es que facilita realizar migraciones de sistemas de datos de forma transparente al usuario. Por ejemplo, es posible desplegar sistemas cloud que reemplacen a sistemas más anticuados y en cuanto estén operativos hacer el cambio en la herramienta de virtualización para empezar a consumir datos de la nueva fuente.
Por último, la virtualización del dato reduce los costes de acceso y de replicación de datos y en creación de pipelines de movimiento y transformación desde las diversas fuentes a los destinos.
Desventajas de la Virtualización de Datos
La principal desventaja de los sistemas de virtualización de datos es el posible impacto que pueden tener en las tecnologías de almacenamiento y de procesamiento de datos que usa como fuente. Para evitar la sobrecarga de estos sistemas, debe escalarse correctamente en función de las consultas que se vayan a realizar.
¿Quieres Convertirte en Ingeniero de Datos?
Otra desventaja es la gestión de los cambios en los datos y en las fuentes originales. Cada vez que se detecta un cambio en las fuentes de los datos se debe realizar un proceso de adaptación para que el servicio de virtualización no se vea negativamente afectado. Algunas soluciones pueden automatizar parte de esta gestión de cambios, pero lo normal es que se deban monitorizar y planificar manualmente la actuación correcta para cada caso. De esta forma evitaremos que las aplicaciones que consumen datos del sistema de virtualización tengan errores inesperados.
Virtualización de Datos con Denodo
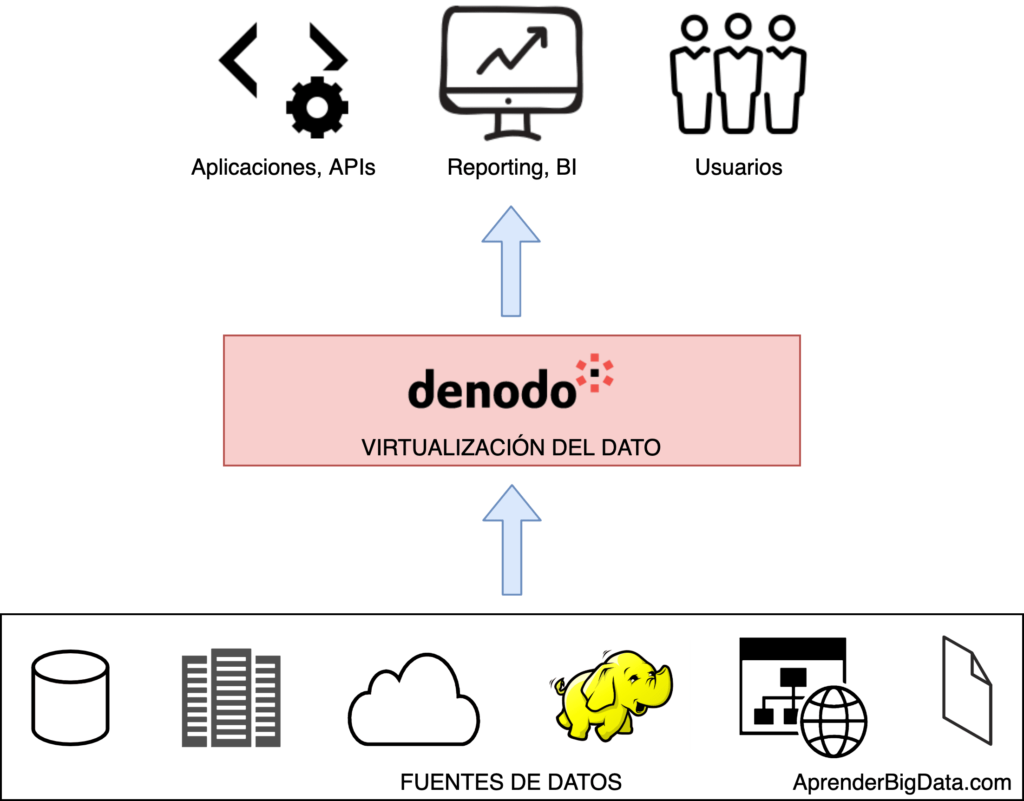
Denodo es una plataforma de virtualización del dato escalable que permite conectar a cualquier fuente de datos (bases de datos, ficheros, APIs, etc.). Además, es posible combinar estas fuentes para crear vistas avanzadas como resultado de realizar transformaciones sencillas en los datasets originales.
Denodo se encarga de exponer en tiempo real las vistas y datos a las herramientas externas mediante varias interfaces como JDBC/ODBC o APIs con soporte para distintos esquemas y formatos.
Incorpora un optimizador dinámico de consultas, que disminuye el tiempo y los recursos necesarios para dar respuesta a las peticiones de los usuarios.
También, Denodo tiene una caché de datos avanzada, que es posible habilitar y configurar para reducir el tiempo de respuesta y las consultas a los sistemas que contienen los datos.
Desplegar un sistema de virtualización de datos con Denodo es muy sencillo y se compone de tres pasos:
- Conectar a las fuentes de datos originales
- Combinar los datos en la herramienta
- Consumir los datos mediante APIs o herramientas externas
Denodo funciona combinando todas las fuentes de datos para crear una única fuente de verdad que se puede usar para trabajos operacionales, de reporting o de analítica. Las fuentes pueden contener datos estructurados, ficheros, documentos XML, PDFs, Excel, bases de datos SQL y NoSQL, Data Warehouses, aplicaciones cloud, APIs o Procesos Streaming, entre otros.
También pueden realizarse escrituras sobre las fuentes de datos originales. Para ello, Denodo usa técnicas de transformación e integración de los datos en el formato adecuado para su almacenamiento.
Denodo se puede desplegar en infraestructura propia o en cloud fácilmente, ya que está integrado con los marketplaces de AWS, Azure y GCP.
Ofrece una versión gratuita llamada Denodo Express que permite probar la funcionalidad básica en proyectos de investigación, pruebas de concepto o prototipos.
Conclusión
La virtualización de datos es fundamental para optimizar y unificar el acceso a las fuentes de datos de grandes organizaciones ¿Te parece que la virtualización de datos crecerá en uso en el futuro? ¿Crees que surgirán herramientas más especializadas?
Continúa aprendiendo sobre virtualización de datos con este libro:
Preguntas Frecuentes Virtualización del Dato – FAQ
¿Para qué se usa la Virtualización de Datos?
La virtualización de datos permite combinar diferentes fuentes de datos fácilmente sin la necesidad de realizar copias de los datos. De esta forma, aumenta la eficiencia y el coste de las operaciones.
¿Qué diferencia existe entre la Federación de datos y la Virtualización de datos?
La federación es una funcionalidad de la virtualización. La virtualización es la capa de abstracción que oculta el detalle de dónde se encuentran los datos originalmente. La federación de datos agrega datos de diferentes fuentes y los muestra bajo una vista y acceso unificados.
¿Qué es Denodo?
Denodo es una herramienta de virtualización de datos que conecta con numerosas fuentes de datos estructurados y no estructurados. Puede combinar estos datos y ofrecer vistas integradas en tiempo real.
¿Es Denodo una Base de Datos?
Denodo no es una base de datos, sino que puede contener diferentes bases de datos virtuales. Estas bases de datos virtuales están formadas por vistas sobre las fuentes de los datos originales.
A continuación, el vídeo-resumen. ¡No te lo pierdas!

Arquitecto de Datos con más de 10 años de experiencia en el sector del Big Data. Autor de cursos de formación en tecnologías Big Data, Cloud y Streaming completados por más de 7000 alumnos en Udemy y otras plataformas. Miembro de la Apache Software Foundation desde 2019.



Qué es lo que no puede hacer Denodo, entrando al ámbito de requerimientos no funcionales??