En esta entrada vamos a introducir qué es Apache Druid, una tecnología para analítica Big Data con capacidad de realizar consultas en tiempo real sobre datos históricos. Además, aprenderemos acerca de su arquitectura, su funcionamiento y sus ventajas respecto a otras bases de datos. ¡No te lo pierdas!

Contenidos
¿Qué es Apache Druid?
Apache Druid es una tecnología enfocada en análisis de datos en tiempo real y muy popular para trabajos OLAP (Online Analytical Processing). Aporta alta disponibilidad al sistema de consultas y nos permite escalarlo con latencias muy bajas.
Se distribuye con licencia open source y es mantenida por la Apache Software Foundation.
Grandes empresas como Netflix o Airbnb usan Apache Druid para hacer consultas sobre flujos de datos y así tomar decisiones en tiempo real.
Druid es una herramienta para almacenar datos. Combina características de Data Warehouses, de sistemas de búsqueda y de análisis de series temporales. De esta forma, puede tomar varias formas para resolver distintos problemas, y de ahí su nombre.
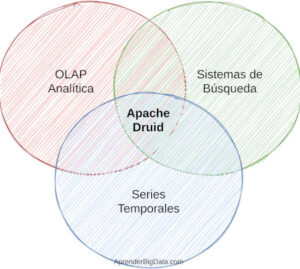
En prestaciones, Apache Druid consigue ser más rápido que tecnologías como Apache Hive o Presto en cargas analíticas.
Características de Apache Druid
Entre las características más importantes de Apache Druid podemos destacar los siguientes aspectos:
Almacenamiento columnar: Este tipo de bases de datos tratan cada columna de forma independiente. Por lo tanto, las consultas se optimizan leyendo solamente las columnas que sean necesarias.
Búsquedas indexada: Permite realizar búsquedas rápidas y filtros sobre los datos. Usa índices invertidos, formando un mapa del contenido y permitiendo búsquedas de textos sobre documentos.
Ingestas de datos streaming y batch: Proporciona conectores ya listos para conectar a sistemas externos como Apache Kafka, Kinesis, S3 o HDFS. Típicamente, esto significa que Apache Kafka será la fuente de datos para cargas en streaming y HDFS o S3 las fuentes de datos para las cargas de tipo batch. Por tanto, la arquitectura en Druid es de tipo Lambda.
Esquemas flexibles: Los esquemas de flexibles soportan su evolución y cambios en el tiempo en función de las necesidades y tipos de datos.
Particionado de datos temporales: Al realizar un particionado de los datos en función de sus fechas, se aceleran las consultas sobre rangos de tiempo considerablemente. Además, puede realizar una preagregación de los datos (rollup) para reducir o colapsar el tamaño de las columnas.
Soporte SQL: Además del lenguaje nativo (JSON), Druid soporte el lenguaje SQL a través de APIs JDBC y HTTP.
Escalabilidad horizontal: El rendimiento de Druid se puede incrementar añadiendo nodos al sistema. También es posible desescalar eliminando nodos. El sistema rebalancea la carga automáticamente y proporciona una arquitectura resistente a fallos.
Funcionamiento de Apache Druid
Druid convierte los datos almacenados en las tecnologías fuentes, como HDFS, a un formato optimizado para la lectura mediante un proceso de indexación. El resultado de este proceso de conversión se denomina segmentos de Druid. También se aplican mecanismos de compresión para optimizar el espacio utilizado.
¿Quieres Convertirte en Ingeniero de Datos?
En ocasiones, Druid también puede pre-agregar los datos a medida que se ingestan. Esta operación permite reducir el espacio empleado, ya que se reduce el número de registros para cada dato.
Además, Druid realiza replicación de datos y backups periódicos a sistemas externos.
Arquitectura de Apache Druid
Apache Druid se sitúa en una arquitectura Big Data como una capa entre los sistemas de almacenamiento de datos y el servicio al usuario. Actúa como una capa de consulta rápida de datos.
La arquitectura de Druid se basa en microservicios, con servicios de ingesta, de consulta y de coordinación. Estos servicios se pueden distribuir de varias maneras en el hardware disponible. Cada uno de ellos tiene mecanismos de tolerancia a fallos para evitar que el sistema sufra pérdidas de servicio.
Como muchas otras tecnologías distribuidas, Apache Druid se apoya en Apache Zookeeper para realizar la coordinación de los nodos del clúster.
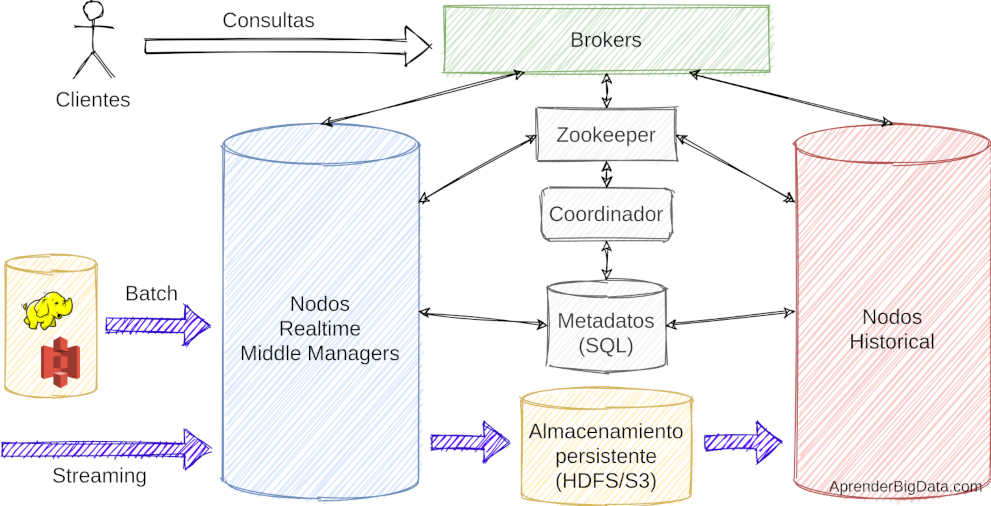
A continuación vamos a ver qué tipos de nodos existen en Druid y para qué sirve cada uno.
Realtime
Estos nodos son los encargados de gestionar las lecturas y las escrituras en tiempo real en streaming. Para aumentar el rendimiento, tienen un buffer en memoria que persisten periódicamente al disco. Estos datos, se almacenan con un formato columnar (segmentos) y sobre ellos se calculan los índices.
Para mantener la persistencia de los datos, los segmentos se terminan almacenando en un sistema de ficheros distribuido, típicamente HDFS (deep storage). Sus metadatos se almacenan en una base de datos relacional como MySQL para hacerlos disponibles a otros nodos.
Historical
Este tipo de nodos son los más comunes en Apache Druid. Se encargan de servir las consultas analíticas que se realizan al clúster. Para ello, cargan los segmentos almacenados en HDFS.
Para enterarse de los nuevos segmentos que se publican usan Zookeeper. Algunos de ellos los guardan en caché para acelerar las consultas.
También se les suele llamar workers.
Brokers
Son los nodos encargados de gestionar las consultas que realizan los usuarios, redirigirlas a los nodos apropiados (historical o realtime) y agregar las respuestas.
Coordinador
Este nodo coordina los nodos históricos o workers indicando cuándo desalojar, cargar, compactar o replicar datos, así como balancear la carga entre los demás nodos. El el responsable de gestionar la disponibilidad de los datos en el clúster.
Solo existe un coordinador o líder ejecutando en cada momento. En el caso de que sufra un fallo, otro nodo toma su lugar.
Ventajas de Apache Druid
La principal ventaja de Apache Druid es que aporta la capacidad de realizar consultas de datos muy rápidas en un sistema de datos escalable de forma columnar.
Esta velocidad es fundamental en sistemas analíticos y para realizar consultas exploratorias sobre nuestros datos. La velocidad de agregación de los datos es muy superior a sistemas de bases de datos tradicionales RDBMS como MySQL o PostgreSQL.
Si lo comparamos con otras herramientas NoSQL escalables, debemos tener en cuenta las preagregaciones de datos que se realizan en Druid. Las optimizaciones que incluye para explorar datos históricos y en tiempo real basados en rangos temporales no son fáciles de implementar sobre otras tecnologías de bases de datos. En este caso, sería necesario preprocesar los datos y realizar agregados con determinadas granularidades, por ejemplo cada hora, cada minuto, etc. Es inviable almacenar estas agregaciones para todas las columnas, rangos de tiempo y combinaciones. Aquí es donde realmente destaca Druid.
Casos de Uso para Apache Druid
Como hemos visto, Apache Druid es una tecnología muy flexible, capaz de adaptarse a multitud de casos de uso. Generalmente, estos casos de uso se caracterizan por tener una alta necesidad de inserciones masivas y rápidas, mientras que las actualizaciones de registros son menos frecuentes.
Debemos observar si la mayor parte de nuestras consultas serán de reporting y necesitarán operaciones de agregación (group by) o de búsqueda. Si además tienen un componente temporal, entonces deberemos evaluar Druid como una solución potente.
Casos de uso más comunes de Apache Druid:
- Analítica web y móvil
- Analítica de marketing digital
- Business Intelligence (OLAP)
- Métricas de rendimiento de redes y de aplicaciones

Curso práctico de Apache Druid
No lo dudes y aprende Apache Druid a fondo con este curso de Udemy en inglés. Te enseñará el detalle de todos sus componentes y los conceptos fundamentales para sacarle todo el partido posible.
Preguntas Frecuentes – FAQ
¿Qué ventajas ofrece Apache Druid sobre otras bases de datos analíticas?
Latencias bajas: Optimizado para consultas de baja latencia y alta concurrencia. Escalabilidad: Arquitectura distribuida que permite escalar horizontalmente. Ingesta en tiempo real: Capacidad para ingerir y consultar datos en tiempo real sin retrasos. Compresión eficiente: Almacenamiento eficiente de datos mediante técnicas de compresión. Soporte para agregaciones complejas: Facilita el análisis avanzado de datos mediante agregaciones y filtrado.
¿Qué es un "segmento" en Apache Druid y cuál es su importancia?
Un «segmento» en Apache Druid es una unidad de almacenamiento que contiene un conjunto de datos indexados para un intervalo de tiempo específico. Los segmentos son fundamentales porque permiten la partición y distribución de datos en el clúster, facilitando la escalabilidad, el rendimiento de consultas y la recuperación ante fallos.
¿Qué es un "rollup" en Apache Druid y cómo se utiliza?
El «rollup» en Apache Druid es una técnica de preagregación de datos durante el proceso de ingesta. Agrupa datos basados en claves específicas y calcula agregaciones como sumas, promedios, etc., antes de almacenarlos en segmentos. Esto reduce el volumen de datos almacenados y mejora el rendimiento de consultas, aunque puede sacrificar el acceso a los datos detallados.
¿Cómo se realiza el escalado horizontal en Apache Druid?
El escalado horizontal en Apache Druid se realiza añadiendo más nodos a los diferentes tipos de servicios (nodos de datos, nodos de consulta, nodos históricos, etc.). Druid está diseñado para ser distribuido y puede automáticamente balancear la carga de trabajo entre los nodos disponibles. Esto permite manejar mayores volúmenes de datos y más consultas concurrentes.
A continuación, un breve vídeo-resumen. ¡No te lo pierdas!

Arquitecto de Datos con más de 10 años de experiencia en el sector del Big Data. Autor de cursos de formación en tecnologías Big Data, Cloud y Streaming completados por más de 7000 alumnos en Udemy y otras plataformas. Miembro de la Apache Software Foundation desde 2019.


