En esta entrada vas a aprender qué es Apache Avro y las ventajas que aporta este sistema de serialización de datos muy usado en big data. Así, podrás empezar a usarlo en tus proyectos y a sacarle todo el partido posible.

Contenidos
¿Qué es Apache Avro?
Apache Avro es un formato de datos binario muy popular en arquitecturas de streaming de eventos. Los datos se almacenan por filas, cada una de forma independiente. Debido a esta característica, no es un formato apropiado para operaciones de agregación por columnas, pero es muy eficiente serializar los datos y posteriormente enviarlos de forma independiente entre sistemas. Se ha vuelto muy popular debido a la cantidad de herramientas del ecosistema Hadoop que lo soportan.
El esquema de los datos contenidos en un registro de Avro se define en formato JSON y es compatible con herramientas como Schema Registry. Este esquema se envía en el propio intercambio de datos como parte del mismo, por lo que un lector podría usarlo para parsear directamente el fichero en la lectura.
Las estructuras de datos que soporta Avro son muy completas, con tipos de datos simples y complejos y se integra con la mayoría de lenguajes populares como Java, C, C++, JavaScript, Python y Ruby.
Podemos comparar Avro con proyectos similares como JSON, Thrift o Protocol Buffer.
Ventajas y Desventajas de Apache Avro
Las ventajas más importante que aporta el uso de Apache Avro son:
- Documentación de datos incluida en el esquema
- Evolución de esquemas
- Soporta compresión y deserialización parcial.
- Compresión y deserialización
- Tipado de datos
Entre las desventajas se incluye que no existe la posibilidad de visualizar el contenido de Avro sin herramientas específicas, por lo que es necesaria una librería para integrarlo con los lenguajes de programación.
Apache Avro vs JSON
Apache Avro aporta numerosas ventajas respecto al uso de JSON para serializar conjuntos de datos. Por un lado, JSON no fuerza el uso de un esquema. Sin embargo, enviar una lista de objetos repetidos en JSON es ineficiente, al poderse repetir todas las claves e impactar en la carga útil del mensaje.
¿Quieres Convertirte en experto en Análisis de Datos?
Aunque Avro también soporta la serialización en formato JSON, el formato binario es más rápido y ocupa menos espacio. Además, también es posible complementarlo con mecanismos de compresión como Snappy.
Kafka con Apache Avro
Avro es muy popular en sistemas de streaming con Kafka y Schema Registry debido a su rendimiento. Al tratarse de un formato binario, es necesario que los clientes de Kafka conozcan el esquema del registro para deserializar el mensaje correctamente.
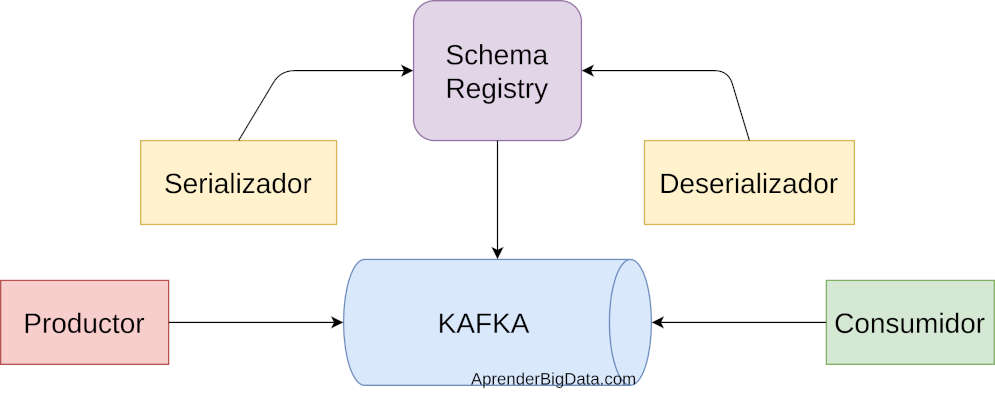
Para deserializar el registro de forma correcta se puede usar el componente Schema Registry. De esta forma, el productor consulta el esquema o añade uno nuevo y el consumidor deserializa el mensaje con ese mismo esquema indicado por Schema Registry.
Evolución de Esquemas
Es importante que ante cambios en el esquema de los datos, los componentes que utilizan el esquema anterior puedan seguir funcionando. A esto se le llama evolución de esquemas y es soportado por Apache Avro.
Con las plataformas de streaming, los consumidores y los productores pueden cambiar y evolucionar en cualquier momento. Los productores pueden tener consumidores que desconocen, y para ser ágil no se quiere actualizar cada consumidor cada vez que un productor añade un campo a un registro.
La compatibilidad entre versiones de esquema define los cambios permitidos. Puede ser de tres tipos. Compatibilidad hacia delante o forward, hacia detrás o backward y completa.
La compatibilidad forward se da cuando se actualiza el esquema de datos en el productor pero la aplicación que consume no se actualiza, sigue utilizando el esquema antiguo. Para que este patrón funcione, es posible añadir campos que no usarán los consumidores antiguos. También es posible eliminar los campos con valores por defecto, que será el valor que tomará el consumidor antiguo.
En el caso de la compatibilidad backward se actualiza el consumidor pero hay productores de datos con el esquema antiguo. Esto es típico cuando los productores de datos no se pueden actualizar por problemas de acceso. En este patrón es posible añadir campos con valores por defecto, que tomarán los consumidores y también es posible eliminar campos, puesto que el consumidor puede ignorar los campos de datos que no necesite.
Por último, la compatibilidad completa cumple con la backward y la forward, por lo que permite eliminar y añadir campos con valores de datos por defecto.
Herramienta de línea de comandos de Avro
Apache Avro proporciona una herramienta de línea de comandos para serializar y deserializar datos llamada avro-tools que se puede descargar desde la página web. La podemos ejecutar sin argumentos como una aplicación java para que nos muestre todas las opciones disponibles:
$ java -jar avro-tools-1.10.2.jar
Version 1.10.2 of Apache Avro
Copyright 2010-2015 The Apache Software Foundation
This product includes software developed at
The Apache Software Foundation (https://www.apache.org/).
----------------
Available tools:
canonical Converts an Avro Schema to its canonical form
cat Extracts samples from files
compile Generates Java code for the given schema.
concat Concatenates avro files without re-compressing.
count Counts the records in avro files or folders
fingerprint Returns the fingerprint for the schemas.
fragtojson Renders a binary-encoded Avro datum as JSON.
fromjson Reads JSON records and writes an Avro data file.
fromtext Imports a text file into an avro data file.
getmeta Prints out the metadata of an Avro data file.
getschema Prints out schema of an Avro data file.
idl Generates a JSON schema from an Avro IDL file
idl2schemata Extract JSON schemata of the types from an Avro IDL file
induce Induce schema/protocol from Java class/interface via reflection.
jsontofrag Renders a JSON-encoded Avro datum as binary.
random Creates a file with randomly generated instances of a schema.
recodec Alters the codec of a data file.
repair Recovers data from a corrupt Avro Data file
rpcprotocol Output the protocol of a RPC service
rpcreceive Opens an RPC Server and listens for one message.
rpcsend Sends a single RPC message.
tether Run a tethered mapreduce job.
tojson Dumps an Avro data file as JSON, record per line or pretty.
totext Converts an Avro data file to a text file.
totrevni Converts an Avro data file to a Trevni file.
trevni_meta Dumps a Trevni file's metadata as JSON.
trevni_random Create a Trevni file filled with random instances of a schema.
trevni_tojson Dumps a Trevni file as JSON.
Como vemos, podemos convertir ficheros de datos en Avro a JSON o texto fácilmente con esta herramienta, así como transformar un fichero JSON en Avro directamente con la opción tojson.
El comando para deserializar datos en Avro a JSON, tanto comprimidos como sin comprimir con Snappy es el siguiente:
java -jar avro-tools-1.10.2.jar tojson fichero.avro
Como el fichero Avro ya tiene incluido el esquema, no es necesario indicarlo en este caso. Si queremos acceder al esquema, podemos usar la opción getschema de la siguiente forma:
java -jar avro-tools-1.10.2.jar getschema fichero.avro
API para Java
Si quieres implementar código Java que manipule ficheros Avro, puedes importar la librería directamente en tu proyecto con Maven añadiendo la siguiente dependencia en el fichero pom:
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.10.2</version>
</dependency>
Recuerda comprobar la versión que necesitas en tu caso.
Preguntas Frecuentes Apache Avro – FAQ
¿Para qué se usa Apache Avro?
Apache Avro es un formato de datos usado para almacenar y serializar datos con esquema de una forma eficiente.
¿En qué se diferencia Apache Avro de JSON?
Apache Avro tiene algunas ventajas respecto a JSON para serializar datos: es un formato más rápido y que ocupa menos espacio, además, es más eficiente que JSON.
¿En qué se diferencia Apache Avro de Apache Parquet?
Apache Parquet es un formato de almacenamiento basado en columnas, en vez de en filas como hace Apache . Por esta razón, Apache Parquet es mejor para realizar consultas analíticas y pocas escrituras. Apache Avro, por otro lado, es mejor para realizar escrituras y serialización de datos.

Arquitecto de Datos con más de 10 años de experiencia en el sector del Big Data. Autor de cursos de formación en tecnologías Big Data, Cloud y Streaming completados por más de 7000 alumnos en Udemy y otras plataformas. Miembro de la Apache Software Foundation desde 2019.



EXCELENTE y PRECISA información