En el mundo de Big Data, la capacidad de almacenar y procesar grandes cantidades de información se ha vuelto crucial para el éxito de muchas empresas. En respuesta a esta necesidad, ha surgido una nueva solución que combina lo mejor de los data lakes y los data warehouses: el data lakehouse.

El data lakehouse es una arquitectura híbrida que permite a las empresas gestionar grandes volúmenes de datos, al mismo tiempo que ofrece herramientas avanzadas para su procesamiento y análisis. En este artículo, descubriremos todo lo que necesitas saber sobre el data lakehouse y cómo puede ser la solución que estás buscando.
Contenidos
¿Qué es un Data Lakehouse?
Un Data Lakehouse es una arquitectura que combina la escalabilidad y rapidez de los Data Lakes con la eficiencia y confiabilidad de los Data Warehouses. Esta arquitectura se basa en un sistema de almacenamiento de datos distribuido, que permite la ingesta y procesamiento de grandes volúmenes de datos, y una capa de procesamiento que permite la transformación, integración y análisis de estos datos.
A diferencia de los Data Lakes tradicionales, que se basan en almacenar datos sin procesar en su forma original, los Data Lakehouses organizan los datos en un esquema de tablas o columnas para mejorar la eficiencia en la consulta y en el análisis de datos. Por otro lado, a diferencia de los Data Warehouses tradicionales, los Data Lakehouses no requieren la definición previa de esquemas de datos y favorecen la escalabilidad horizontal, lo que facilita el procesamiento de grandes volúmenes de datos.
Diferencias entre un Data Warehouse, un Data Lake y un Data Lakehouse
Resulta muy fácil confundir términos como Data Warehouse, Data Lake y Data Lakehouse. Cada uno de ellos se refiere a una arquitectura de almacenamiento de datos, pero tienen diferencias significativas.
Un Data Warehouse es un repositorio centralizado de datos estructurados, orientado a las consultas y el análisis de negocios. La información se almacena en tablas relacionales y se estructura para facilitar la consulta y el análisis. Te recomiendo que leas el artículo específico de Data Warehouse para tener más detalle.
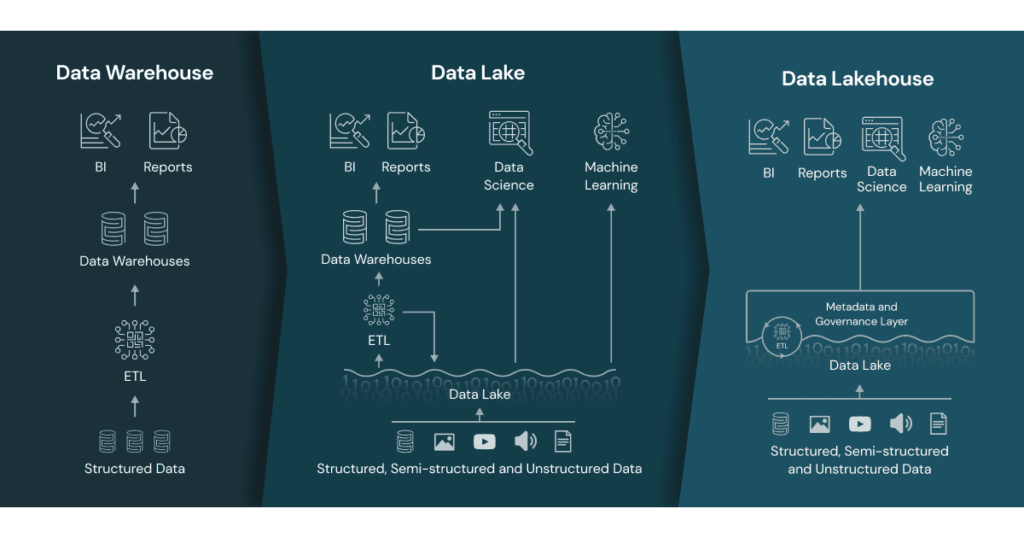
Por otro lado, un Data Lake es un repositorio centralizado de datos sin estructurar y semiestructurados. Es una solución más flexible y escalable que permite el almacenamiento de datos en bruto sin procesar, lo que permite un análisis más exhaustivo y una exploración más profunda de los datos. Aquí tienes el artículo en detalle sobre Data Lakes.
Un Data Lakehouse es una combinación de ambos. Es una solución híbrida que combina los beneficios de un Data Warehouse y de un Data Lake. Permite el almacenamiento y procesamiento de datos estructurados, semiestructurados y no estructurados, lo que significa que los datos pueden ser analizados y procesados según sea necesario. Además, los datos pueden ser utilizados tanto para analítica y para machine learning.
Arquitectura de un Data Lakehouse
La arquitectura de un Data Lakehouse por tanto combina elementos de un Data Warehouse y un Data Lake. Un Data Lakehouse se compone de un almacenamiento escalable y eficiente de datos en bruto, sin procesar. También, consta de una capa de procesamiento de datos flexible y escalable y de una capa de servicios para proporcionar un acceso controlado a los datos.
La capa de almacenamiento contiene los datos en su formato nativo y están organizados por temas o dominios de negocio. El almacenamiento de datos se basa en una infraestructura de almacenamiento distribuida que puede escalar horizontalmente a medida que aumenta la cantidad de datos. Generalmente, serán servicios como ADLS en Azure y S3 en AWS.
¿Quieres Convertirte en Ingeniero de Datos?
La capa de procesamiento de datos proporciona la capacidad de procesar grandes cantidades de datos de forma paralela y distribuida. Esta capa utiliza tecnologías como Apache Spark o Apache Flink para procesar los datos y transformarlos en información valiosa. La capa de procesamiento de datos se ejecuta en un clúster de procesamiento distribuido y escalable que puede ajustarse en función de la carga de trabajo, por ejemplo usando Databricks.
Por último, la capa de servicios proporciona una capa de abstracción que permite a los usuarios acceder a los datos de forma segura y controlada. Esta capa incluye tecnologías como Apache Hive o Presto para permitir el acceso a los datos mediante SQL, y tecnologías de virtualización de datos para proporcionar acceso a los datos a través de APIs RESTful.
Ventajas de utilizar un Data Lakehouse en tu empresa
Un Data Lakehouse ofrece varias ventajas técnicas y empresariales sobre las soluciones tradicionales de almacenamiento y procesamiento de datos. A continuación tienes un listado con algunas de las ventajas más importantes:
- Flexibilidad: Al combinar características de un data lake y un data warehouse, ofrece una arquitectura altamente flexible. Puedes almacenar datos en su formato nativo sin tener que preocuparte por el esquema de datos, lo que facilita la integración de datos de diferentes fuentes. Además, puedes transformar, procesar y consultar los datos en tiempo real sin tener que moverlos a otra ubicación.
- Escalabilidad: Un data lakehouse te permite escalar verticalmente y horizontalmente según tus necesidades. Puedes agregar más recursos de almacenamiento y procesamiento para manejar mayores volúmenes de datos y consultas más complejas. Además, puedes agregar nuevas fuentes de datos sin preocuparte por la capacidad de almacenamiento.
- Eficiencia: Al evitar la necesidad de mover datos entre diferentes sistemas de almacenamiento y procesamiento, un data lakehouse puede reducir significativamente los tiempos de procesamiento y aumentar la eficiencia. También puedes utilizar motores de procesamiento distribuido, como Apache Spark, para procesar grandes volúmenes de datos en paralelo y acelerar el tiempo de procesamiento.
- Coste: Al evitar la necesidad de mover datos entre diferentes sistemas de almacenamiento y procesamiento, un data lakehouse puede reducir significativamente el coste de almacenamiento y procesamiento.
Herramientas y tecnologías para implementar un Data Lakehouse
Para implementar un Data Lakehouse, se necesita un conjunto de tecnologías y herramientas que permitan integrar, procesar y analizar los datos.

Las opciones de almacenamiento para un Data Lakehouse pueden variar desde sistemas de almacenamiento de archivos distribuidos como HDFS o Amazon S3 hasta bases de datos columnares como Snowflake.
Por otro lado, Spark es una tecnología ampliamente utilizada para procesamiento de datos en tiempo real y batch en un Data Lakehouse. Otras herramientas populares incluyen Apache Flink para streaming y Apache Beam.
También necesitaremos herramientas de orquestación de flujo de trabajo e integración de datos. Algunas opciones son Apache Airflow, Apache Nifi y Apache Kafka.
La elección de las herramientas y tecnologías adecuadas dependerá de las necesidades específicas de la empresa y de los datos que se estén procesando. Es muy importante conocer estas tecnologías para diseñar una solución adecuada y adaptada a estas necesidades.
Desafíos y consideraciones a tener en cuenta
Aunque un Data Lakehouse puede ser una solución efectiva para manejar grandes volúmenes de datos y ofrecer una arquitectura más flexible y escalable, también hay ciertos desafíos y consideraciones importantes que debes tener en cuenta.
Al igual que con cualquier solución de Big Data, es fundamental implementar medidas de seguridad adecuadas para proteger los datos sensibles y garantizar el cumplimiento normativo. Esto puede incluir la implementación de controles de acceso, encriptación y monitorización.
Un Data Lakehouse puede generar grandes volúmenes de datos de diferentes fuentes y formatos. Es importante contar con herramientas y procesos para administrar y catalogar estos datos de manera efectiva. Debemos definir de políticas de datos, estandarizar los formatos usados y establecer mecanismos de housekeeping para eliminar datos obsoletos.
Preguntas Frecuentes – FAQ
¿Qué ventajas tiene el uso de un Data Lakehouse en comparación con otras soluciones de almacenamiento de datos?
Una de las principales ventajas de un Data Lakehouse es su flexibilidad y escalabilidad. Al combinar elementos de Data Warehousing y Data Lakes, un Data Lakehouse puede almacenar grandes cantidades de datos sin comprometer la velocidad de las consultas. Además, los datos almacenados en un Data Lakehouse pueden ser accedidos de manera más rápida y eficiente, lo que puede mejorar la toma de decisiones empresariales
¿Qué tipo de empresas pueden beneficiarse de un Data Lakehouse?
Un Data Lakehouse puede beneficiar a cualquier empresa que maneje grandes cantidades de datos y necesite un sistema de almacenamiento de datos flexible y escalable. En particular, las empresas que operan en sectores como el comercio electrónico, las finanzas, la salud y la tecnología pueden beneficiarse significativamente de un Data Lakehouse
¿Qué riesgos o desventajas hay en la implementación de un Data Lakehouse?
Algunos de los riesgos o desventajas incluyen la complejidad en la implementación y la necesidad de contar con expertos en el manejo de los datos. También es importante tener en cuenta la calidad de los datos y la necesidad de tener un buen sistema de gestión de datos para evitar errores en la información
¿Cómo se asegura la privacidad y seguridad de los datos en un Data Lakehouse?
Es importante contar con medidas de seguridad como el cifrado de datos, el control de acceso y la autenticación para asegurar la privacidad y seguridad de los datos almacenados en un Data Lakehouse. Además, se debe contar con un buen sistema de monitorización para detectar cualquier intento de acceso no autorizado o amenaza a la seguridad de los datos

Arquitecto de Datos con más de 10 años de experiencia en el sector del Big Data. Autor de cursos de formación en tecnologías Big Data, Cloud y Streaming completados por más de 7000 alumnos en Udemy y otras plataformas. Miembro de la Apache Software Foundation desde 2019.


