En esta entrada aprenderás qué es PrestoDB y cómo empezar a trabajar con este motor SQL para tu data lake.

Contenidos
¿Qué es PrestoDB?
Presto es un motor de consultas SQL open source distribuido diseñado para realizar consultas analíticas interactivas para big data. La característica más importante de PrestoDB es la capacidad de consultar los datos donde están almacenados y de diversas fuentes federando las consultas. Aporta una alta escalabilidad y buen rendimiento, así como una gran cantidad de conectores a fuentes de datos que optimizan las consultas paralelizando y escalando el procesamiento.
PrestoDB fue desarrollada por Facebook en el año 2012 para evitar que las consultas sobre Apache Hive realizaran tantas escrituras en disco. Presto consigue reducir las latencias respecto a Apache Hive con su arquitectura en memoria para realizar consultas interactivas. Tras el fork del proyecto de Presto original, surgieron dos proyectos principales: PrestoDB y PrestoSQL, que se pasó a llamar Trino. Presto está escrito en Java y usa ANSI SQL como lenguaje de consultas, con soporte a los tipos de datos definidos (integer, string, double, etc).
Soporta fuentes de datos no relacionales como HDFS, S3, Cassandra, MongoDB o HBase y fuentes de datos relacionales como MySQL, PostgreSQL, Redshift, Microsoft SQL Server y Teradata. También puede trabajar con formatos de fichero CSV, RCFile, JSON, SequenceFile, ORC, Avro y Parquet.
Los casos de uso más comunes por tanto son los que incluyen consultas interactivas y pipelines de ETL.
Arquitectura de PrestoDB
La arquitectura de presto es un motor MPP (Massively parallel processing). Puede escalar horizontalmente añadiendo más nodos de cómputo y separar éste del almacenamiento.
Existe un nodo coordinador del clúster que orquesta el resto de nodos a través de comunicaciones HTTP y acepta y planifica la ejecución de las consultas. Los nodos worker son los que procesan la consulta en memoria.
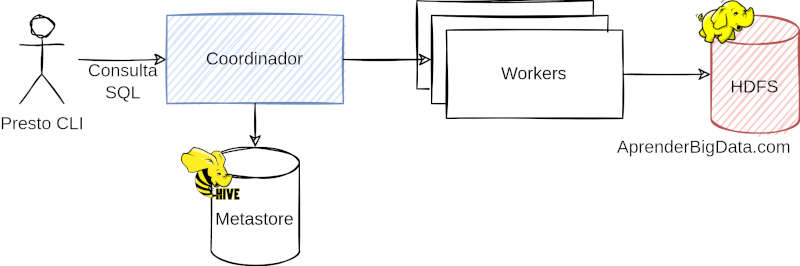
Presto consulta los datos donde se almacenan, sin la necesidad de mover los datos a un sistema analítico separado. Al no almacenar los datos, no requiere ninguna operación de redistribución de datos al añadir nodos de cómputo.
Los servicios Cloud Amazon Athena, Amazon EMR y Dremio están basados en el motor de consulta de PrestoDB, aunque son alternativas con más soporte y compatibilidad.
Ventajas
- Al federar las consultas, no necesita procesos de migración de datos
- Escalabilidad horizontal: Aumento de paralelismo y velocidad de consulta
- Puede ser una alternativa a Dremio, Athena o Databricks SQL
- Integrado con AWS S3 y ADLS como repositorios de datos
- La empresa Starbust ofrece la versión con soporte empresarial
Desventajas
- No se integra en AWS Lake Formation directamente
- No tiene la posibilidad de despliegue como servicio serverless en Cloud
- Carece de dashboard integrado y de una interfaz para realizar consultas SQL o con la capacidad de escribir notebooks
Funcionamiento de PrestoDB
Los usuarios envían su consulta SQL al nodo coordinador, que parsea, planifica y distribuye su plan de ejecución a los nodos worker. Se crea un pipeline de ejecución con las fases de la consulta en forma de árbol jerárquico para minimizar las operaciones de tipo I/O sobre los discos. Por tanto, añadir más nodos worker aumenta el paralelismo y la velocidad de ejecución de las consultas.
¿Quieres Convertirte en Ingeniero de Datos?
Presto se enfoca en el uso de plugins como muchas herramientas open source. Tanto en conectores como en herramientas de terceros para realizar las consultas, por ejemplo no tiene un driver ODBC oficial ni una interfaz gráfica para las consultas.
Los conectores de Presto implementan las interfaces para comunicarse con las fuentes de datos, sus tablas y esquemas de una manera uniforme.
Cómo Empezar con Presto
Última versión de Presto disponible para su descarga: https://prestodb.io/download.html
Para ejecutar Presto, necesitarás la JDK 1.8 o superior instalada en tu sistema. Si deseas probar las versiones de desarrollo y últimos cambios, también tienes el enlace al repositorio de Github oficial: https://github.com/prestodb/presto
Desde Linux, puedes descargarlo y ejecutarlo directamente desde la terminal:
wget "https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.271.1/presto-server-0.271.1.tar.gz"
tar -xzvf presto-server-0.271.1.tar.gz
sudo mv presto-server-0.271.1 /opt/presto-server
sudo chown -R $USER:$USER /opt/presto-server
export PATH=$PATH:$PRESTO_HOME/bin
Para ejecutar un clúster de un solo nodo, ejecutaremos el coordinador y el worker en el mismo host. Este despliegue nos resultará útil para hacer pruebas y poder interactuar fácilmente con el sistema.
Editaremos los ficheros etc/node.properties (para los nodos) y etc/config.properties (para el coordinador). En el fichero config.properties estableceremos los parámetros de memoria y puertos. En el caso de querer desplegar varios nodos, tendremos que crear varios ficheros etc/node.properties con identificadores diferentes. Para ejecutar PrestoDB, deberemos usar el comando:
bin/launcher start
También, podemos editar el fichero etc/jvm.config, donde se especifica la configuración para la JVM.
Por defecto, podremos acceder a la interfaz web en el siguiente puerto: http://localhost:8080
Presto también dispone de una CLI, para conectarse a ella, desde la terminal se especificará la localización del servidor, el catálogo y el esquema:
presto \
--server localhost:8080 \
--catalog hive \
--schema default
Ahora, puedes explorar los esquemas y tablas con comandos SQL:
SHOW CATALOGS;
SHOW SCHEMAS IN catalogo;
SHOW TABLES IN catalogo.esquema;
DESCRIBE catalogo.esquema.tabla;
SHOW STATS FOR tabla;
A continuación tienes un ejemplo de código en Python que muestra cómo utilizar PrestoDB para realizar consultas a una base de datos:
# Importa la librería de Python de PrestoDBfrom presto import PrestoClient # Crea una conexión al servidor de PrestoDB presto = PrestoClient( host='localhost', port=8080, user='presto', catalog='hive', schema='default' ) # Ejecuta una consulta response = presto.query( 'SELECT name, age FROM users WHERE age > 30' ) # Imprime los resultados de la consulta print(response.data)
En este ejemplo se importa la librería de cliente Python de PrestoDB y se crea una conexión al servidor PrestoDB. Luego se ejecuta una consulta en PrestoDB y se imprimen los resultados de la consulta.

Cursos de Formación con Presto y Siguientes Pasos
Si te interesa aprender más sobre Presto y los motores de consulta SQL distribuidos, te recomiendo este curso de especialización en analítica Big Data con SQL ofrecido por Cloudera que ya han disfrutado más de 50000 alumnos. Tiene un fuerte componente práctico que te permitirá comprender las habilidades esenciales que necesitarás para trabajar con estas tecnologías de manera profesional.
Si prefieres centrarte en comprender específicamente PrestoDB, aquí tienes dos cursos que te recomiendo en la plataforma online Udemy:


Preguntas Frecuentes PrestoDB
Presto vs Apache Drill
Ambas tecnologías tienen un propósito similar. Presto fue desarrollado para optimizar las consultas SQL para analítica interactiva a través de conectores con otras tecnologías. Apache Drill, por otro lado no necesita definir el esquema en los conectores para descubrir o consultar datos.
PrestoDB vs PrestoSQL
Ambas tecnologías son el resultado de un fork en el proyecto de Presto original. PrestoDBs e ha centrado en consultas analíticas interactivas para big data, mientras que PrestoSQL no tiene un foco tan específico. En el año 2020, PrestoSQL se renombró como Trino.
A continuación, el vídeo-resumen. ¡No te lo pierdas!

Arquitecto de Datos con más de 10 años de experiencia en el sector del Big Data. Autor de cursos de formación en tecnologías Big Data, Cloud y Streaming completados por más de 7000 alumnos en Udemy y otras plataformas. Miembro de la Apache Software Foundation desde 2019.