Databricks SQL se ha posicionado como una de las soluciones más eficientes para la ejecución de consultas SQL sobre grandes volúmenes de datos.

Databricks nació como una plataforma enfocada en procesamiento distribuido basado en Apache Spark, pero con Databricks SQL se ha convertido en una herramienta potente para analistas y científicos de datos que necesitan ejecutar consultas SQL con tiempos de respuesta optimizados.
Contenidos
¿Qué hace especial a Databricks SQL?
Optimización para Big Data: A diferencia de otros sistemas tradicionales, Databricks SQL aprovecha la escalabilidad de la nube para ejecutar consultas de manera eficiente sobre conjuntos de datos masivos.
Interfaz Intuitiva: Su entorno gráfico facilita la escritura, ejecución y visualización de consultas SQL, haciendo que sea accesible tanto para analistas como para ingenieros de datos.
Integración con herramientas de BI: Funciona perfectamente con soluciones como Power BI, MicroStrategy o Tableau, lo que permite a las empresas extraer insights de sus datos sin fricciones.
También podremos crear directamente visualizaciones, dashboards y configurar alertas. Los usuarios principales son analistas de datos y científicos de datos.
Databricks SQL tiene 4 componentes principales:
- Editor SQL: El editor SQL nos permite escribir y almacenar consultas para acceder y explorar nuestros datos. También, podremos crear y compartir visualizaciones y dashboards y crear alertas de cambios.
- Conectores de BI y SQL: Los conectores nos permiten integrar otras herramientas como Power BI en nuestros endpoints SQL para establecer accesos optimizados a los datos.
- Endpoints SQL: Estos endpoints representan los puntos de acceso a los datos. Son recursos computacionales que permiten ejecutar consultas SQL. También gestionan los accesos a los usuarios, el tamaño de los clusters de Apache Spark y su concurrencia.
- Databricks Delta Engine: Es el motor de consultas que ejecuta en los clusters de Spark, procesando grandes cantidades de datos en paralelo.
Ventajas de Databricks SQL
Interfaz de SQL Nativo
Una de las capacidades que se echaban de menos en Databricks es un editor de consultas SQL que permita a los usuarios explorar fácilmente los datos, similar a lo que hace Apache Hue en el ecosistema Hadoop con Hive. Este editor está basado en Redash y tiene autocompletado. En este caso, las tablas se almacenan en formato Delta Lake aunque también admite fuentes de datos como JSON o CSV con operaciones limitadas.
Los resultados de las consultas se pueden almacenar en una caché para reducir los tiempos de respuesta en ejecuciones posteriores. Además, podremos ver las ejecuciones anteriores de una consulta. También es posible guardar consultas y fragmentos de código SQL junto a una descripción para reutilizarlos cuando necesitemos.

La interfaz SQL integra también un navegador de esquemas, en el que podremos ver todas las tablas para las que tengamos permisos de lectura.
Visualizaciones, Dashboards y Alertas
A partir de los resultados de las consultas, Databricks SQL nos permite construir y guardar fácilmente visualizaciones. Entre los tipos de visualizaciones incluidos se encuentran los diagramas de cajas, gráficos de barras, de áreas, circulares, Cohort, contadores, embudos, mapas, tablas dinámicas, Sankey, Sunburst y nubes de palabras.
Estas visualizaciones se pueden agrupar en dashboards o paneles con una interfaz gráfica de arrastrar y soltar. Cuando tenemos guardado un dashboard lo podemos compartir y abrir en cualquier navegador.
Estos dashboards también se pueden configurar para que refresquen los datos automáticamente, y establecer alertas automáticas para avisar de los cambios en los datos. De esta forma, podremos realizar un seguimiento fácilmente de nuestros KPIs o indicadores.
Con las alertas deberemos establecer una frecuencia de notificaciones y un destino. Los destinos de alertas soportados son Email. Slack, WebHook, Mattermost, ChatWork, PagerDuty y Google Hangouts Chat.
Administración del lago de datos
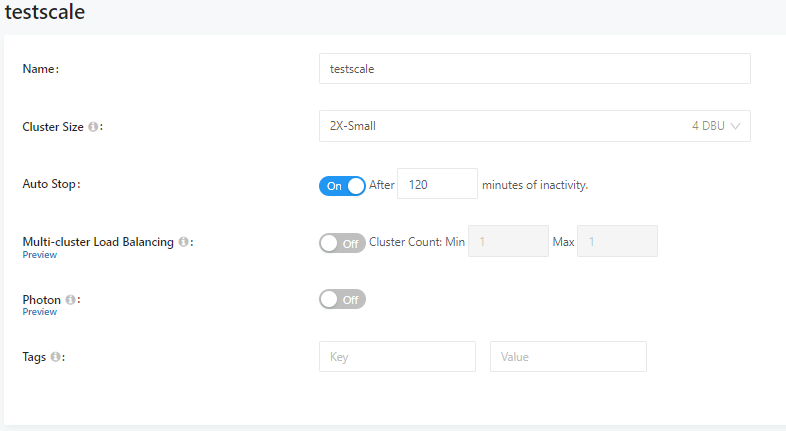
En Databricks SQL se crean SQL Endpoints, que son los puntos de acceso a los datos. Estos endpoints se pueden asignar a usuarios o grupos de usuarios y también controlar su tamaño y su concurrencia.
Representan clusters de Apache Spark desplegados en nuestra suscripción. Los endpoints extienden la capacidad de Delta Lake para manejar los picos de tráfico y la utilización del clúster. Admiten escalado automático estableciendo un tamaño mínimo y un tamaño máximo medido en DBU (Databricks Units), que representan la capacidad de procesamiento por hora. El máximo son 256 workers.
Si un endpoint se encuentra detenido y ejecutamos una consulta, este arranca automáticamente.
Por otro lado, podremos analizar el uso de estos endpoints por los usuarios de la plataforma y por intervalos de tiempo. También, podremos analizar las consultas que se han realizado y las fases en las que descomponen, para realizar auditorías o solucionar los problemas. Se integra con Azure Active Directory y tiene controles basados en roles.
Integraciones con otras Herramientas
Aunque muchas operaciones y visualizaciones se pueden llevar a cabo en la propia interfaz de la herramienta, también es posible integrar Databricks SQL con otras herramientas de BI con los conectores de Power BI, Tableau, Qlick o MicroStrategy. Podemos usar cualquier cliente compatible con Apache Spark y de esta forma establecer las conexiones a nuestras tablas de datos de Delta Lake.
Además podemos integrar Databricks SQL con bases de datos y servicios de almacenamiento de Azure o AWS como Synapse Analytics, Cosmos DB o ADLS (Azure Data Lake Storage).
Databricks SQL Warehouses: ¿Qué son y cómo funcionan?
Los SQL Warehouses en Databricks son entornos optimizados para ejecutar consultas SQL de alto rendimiento sobre datos almacenados en la nube.
Son una solución de Data Warehouse en la nube que permite aprovechar la potencia de Databricks sin necesidad de administrar infraestructura.
La creación y gestion de SQL Warehouses en Databricks es similar a los clusters de propósito general (job compute o all purpose). Hay dos tipos de SQL Warehouse, que también tienen una política de costes diferente:
Classic SQL Warehouse (Basado en Clústeres)
- Se paga por tiempo de ejecución del clúster, no por consulta.
- Se cobra por cada VM en ejecución mientras el warehouse está encendido.
- El coste es en DBU/hora (Databricks Units por hora) más el coste de las máquinas virtuales.
Por ejemplo, si activas un warehouse Medium (4 DBUs/hora) y lo dejas encendido 1 hora, pagas 4 DBUs + costo de VMs aunque no ejecutes consultas. Una buena idea es utilizar la funcionalidad de auto-suspend para evitar costes innecesarios.
Serverless SQL Warehouse (Pago por Consulta)
- Se paga solo por las consultas ejecutadas (modelo pay-per-query).
- No hay costes por encender el warehouse ni por mantener un clúster. No pagas nada si no hay consultas en ejecución.
- El precio depende de la cantidad de datos procesados en cada query.
Diferencias Clave
| Tipo de Warehouse | Pago por | Mejor para |
|---|---|---|
| Classic SQL Warehouse | Tiempo de ejecución del clúster (DBU/hora + Azure VMs) | Cargas constantes y pesadas |
| Serverless SQL Warehouse | Consultas ejecutadas (pay-per-query) | Consultas intermitentes o impredecibles |
Si usas Classic y quieres reducir costes, considera cambiar a Serverless, si está disponible en tu región.
Una de las mayores frustraciones en entornos tradicionales es la espera de varios minutos para que un clúster SQL esté listo. Con los Serverless SQL Warehouses, este problema desaparece. En mi experiencia, esto es una mejora clave en la experiencia del usuario, ya que los análisis son prácticamente instantáneos.
Integración con herramientas de BI
Uno de los puntos fuertes de Databricks SQL es su integración con herramientas de inteligencia de negocios.
Para muchas herramientas, se puede establecer una conexión directa a través del conector nativo de Databricks y JDBC/ODBC. En Power BI, también se optimizan las consultas mediante DirectQuery para análisis en tiempo real.
Esto nos permite acceder rápidamente a los datos sin necesidad de ETL adicionales o copias de datos. Configurar la conexión es un proceso rápido y los dashboards se actualizan con datos en tiempo real, algo clave para la toma de decisiones estratégicas.
Migración desde Cloudera: Databricks SQL como alternativa a HUE
Para muchas empresas que migran desde Cloudera, una de sus mayores preocupaciones es encontrar un reemplazo para HUE, la herramienta web para ejecutar consultas SQL.
Comparación HUE vs. Databricks SQL:
| Característica | HUE (Cloudera) | Databricks SQL |
|---|---|---|
| Interfaz | Básica, menos intuitiva | Moderna y optimizada |
| Tiempo de ejecución | Dependiente del clúster | Optimización con caching |
| Integraciones | Limitadas a Cloudera | Compatible con múltiples nubes |
Siguientes Pasos, Formación y Cursos de Databricks
Aquí tienes mi propio curso para que aprendas de forma eficiente Databricks, para cualquier nivel:

Curso de Introducción a Databricks
Este curso te preparará para comprender y sacar todo el partido posible al ecosistema de Databricks.
Explorarás conceptos fundamentales como la arquitectura de Databricks, los tipos de clústeres, Delta Lake, Unity Catalog y la integración con Azure Data Lake Storage.
En las secciones prácticas, pondrás manos a la obra utilizando la interfaz gráfica, configurando clústeres, trabajando con notebooks, gestionando costes y securizando accesos

Arquitecto de Datos con más de 10 años de experiencia en el sector del Big Data. Autor de cursos de formación en tecnologías Big Data, Cloud y Streaming completados por más de 7000 alumnos en Udemy y otras plataformas. Miembro de la Apache Software Foundation desde 2019.


