En esta entrada vas a aprender en qué consiste Azure Synapse Analytics, el servicio de data warehouse en la nube de Azure. Explicaré brevemente su arquitectura, componentes principales y algunas de sus características más importantes para ayudarte a comprender su uso y las ventajas que aporta.

Contenidos
¿Qué es Azure Synapse Analytics?
Azure Synapse Analytics es una plataforma de analítica completa disponible como servicio en la nube de Azure. Anteriormente se llamaba SQL Data Warehouse.
Nos permite ingestar, preparar, transformar y servir los datos de una forma totalmente escalable para nuestros procesos de analítica o BI.
Arquitectura de Azure Synapse Analytics
La plataforma de Azure Synapse está formada por cuatro componentes principales:
Por un lado tiene dos motores analíticos. El primero está basado en SQL y tiene dos variantes: Dedicado y Serverless. El otro motor está basado en Apache Spark, y nos permite levantar nuestros propios clusters de Apache Spark dedicados para ejecutar nuestros trabajos.

Incluye Apache Spark, Scala, Java, Python y Delta Lake.
El motor de consulta SQL es distribuido. Permite implementar un Data Warehouse escalable usando el lenguaje T-SQL.
Synapse también integrada la funcionalidad de Azure Data Factory llamada Synapse Pipelines para realizar transformaciones, integraciones y movimientos de datos. Sigue el mismo modelo de costes que Azure Data Factory.
Por último, Synapse Studio es la capa que integra y unifica todos estos componentes bajo una gestión única, con capacidades de monitorización y aportando la seguridad y gestión de usuarios propia de Azure. Synapse Studio también permite la creación de notebooks y de scripts SQL colaborativos desde la interfaz.
Como almacenamiento persistente, Synapse usa Azure Data Lake Storage Gen2 (ADLS). La cuenta de almacenamiento del área de trabajo se elige al crearlo, aunque después es posible asociar más cuentas de almacenamiento y contenedores para acceder a sus datos. El ratio de compresión de datos en Synapse es de 5 a 10 veces.
Data Warehouse con Azure Synapse
Como hemos visto, Synapse tiene dos variantes del SQL Warehouse. Ambas están caracterizadas por separar el cómputo del almacenamiento. Existe un nodo de control que utiliza un motor SQL distribuido para optimizar nuestras consultas para ejecutar en paralelo. Ambas opciones nos proporcionan un conector JDBC/ODBC para conectarnos a través de cualquier cliente SQL compatible, por ejemplo Power BI.
SQL Dedicado
El SQL dedicado usa el DWU como unidad de coste y de poder de cómputo. Se calcula a partir de la CPU, memoria e IO de los hosts. Synapse nos permite elegir clústers desde DW100c hasta DW30000c.
Los ficheros de datos ingestados se deben distribuir en particiones para optimizar el rendimiento de las consultas. En concreto, al crear una tabla debemos especificar si queremos distribuir las particiones con una estrategia Hash, round robin o replicadas.
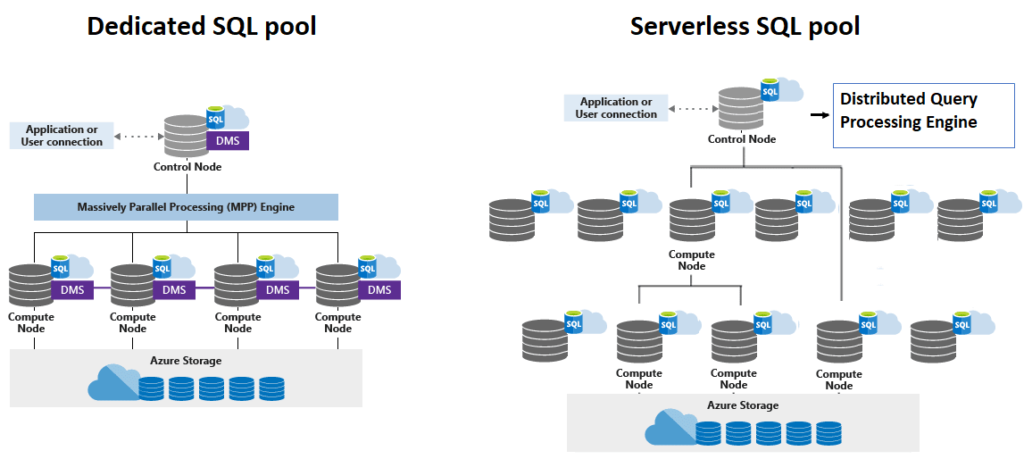
El clúster dedicado también nos permite aumentar o disminuir el número de nodos sin mover los datos, simplemente se redistribuyen las asignaciones de las particiones en los nodos disponibles, que pueden llegar hasta 60. Podemos detener el clúster cuando no vayamos a usarlo y volver a arrancarlo bajo demanda, pagando solamente por el almacenamiento.
SQL Serverless
En el caso del clúster SQL Serverless, el motor SQL distribuido divide la consulta en tareas, que leen los datos del almacenamiento, realiza agregaciones y ordena los resultados de otras tareas. Este clúster permite definir tablas externas para exponer el almacenamiento con una interfaz SQL.
En el clúster SQL Serverless no es necesario controlar su ejecución o escalado, ya que lo hace automáticamente y de forma transparente. El rendimiento es menor que en el caso del dedicado, ya que no implementa la estrategia de particionado de datos.
Gestión de workloads
Synapse Analytics gestiona los usuarios en dos niveles. Por un lado, debemos establecer los accesos al área de trabajo de Synapse, donde tenemos el control de las pipelines de datos y los clusters de Spark y SQL. Por otro lado, se puede gestionar el acceso a los propios datos. En el caso de los motores SQL, podremos hacerlo a través de credenciales SQL o con Azure Active Directory.
¿Quieres Convertirte en Ingeniero de Datos?
Para monitorizar nuestras consultas y trabajos del clúster tenemos varias opciones. Synapse contiene una interfaz de monitorización en la que podemos ver la lista de consultas activas en tiempo real, así como los trabajos que tengamos en ejecución y sus logs. También, podemos integrarlo fácilmente con Azure Monitor si queremos centralizar la monitorización de varios servicios.
Los backups en Azure Synapse se realizan de forma automática. Tiene snapshots para gestionar puntos de restauración de los datos cada 8 horas, aunque se pueden añadir más de forma manual. También, realiza un backup georeplicado a otro centro de datos una vez al día, por lo que asegura un RPO de 24h de este tipo.
Conclusión
Azure Synapse Analytics es un servicio cloud de Data Warehouse que está teniendo un gran impulso por parte de Microsoft. Está perfectamente integrado con otros servicios en la nube como Azure Data Factory, Azure Purview (Gobierno de datos) o Databricks.
Resulta una opción muy interesante para gestionar nuestros clusters SQL en la nube de manera sencilla y sin limitaciones de cómputo o de almacenamiento. Nos permite implementar fácilmente esquemas de datos como Snowflake schema. Como tecnologías alternativas que tenemos que valorar encontramos Snowflake (multi-cloud) o Redshift en AWS.
Recursos Relacionados y Formación
Aunque Synapse es sencillo de usar, debes comprender cómo explotarlo de la mejor manera posible para satisfacer las necesidades de tus proyectos. Además, necesitas entender cómo interactuar desde este servicio con otros servicios del catálogo de Azure.

Preparación de la Certificación Azure Data Fundamentals DP-900
Este curso actualizado y ofrecido por Microsoft en la plataforma de formación online de Coursera te preparará para la certificación de Azure Data Fundamentals.
Es una forma eficaz de aprobar el examen, ya que te guiará con ejercicios prácticos para que aprendas y apliques todos los conocimientos
Si quieres aprender más sobre cloud computing y Azure, aquí tienes algunas entradas relacionadas que deberías leer:
- Conceptos Básicos de la nube
- Servicios de Big Data y Bases de Datos en Azure
- AZ-900 Certificación Microsoft Azure Fundamentals
- DP-900 Certificación Microsoft Azure Data Fundamentals
- Certificaciones de Seguridad de Microsoft Azure
Preguntas Frecuentes Synapse Analytics – FAQ
¿Cuándo usar Azure Synapse Analytics?
Azure Synapse Analytics es la solución de Microsoft Azure para implementar Data Warehouses en la nube. Aunque ofrece múltiples características, su punto fuerte es la consulta de datos del Data Lake con SQL, así como la capacidad de desplegar clusters de Apache Spark para ejecutar tus trabajos.
¿Es compatible con Databricks y HDInsight?
Azure Synapse es compatible con Databricks y HDInsight en Azure. Cuenta con un conector para Databricks que permite acceder a los datos y realizar consultas a través de Synapse. En el caso de Databricks, también es posible conectarlo para realizar consultas SQL.
¿Es un servicio serverless?
Synapse Analytics cuenta con un servicio serverless de consulta SQL. Este servicio permite ejecutar un motor SQL distribuido para consultar datos externos que escala automáticamente en función de las necesidades.
¿Es un servicio de Azure SaaS o PaaS?
Azure Synapse Analytics es un servicio de Azure PaaS (Plataforma como servicio), que nos proporciona acceso a herramientas para desplegar nuestros clusters de Spark o SQL, así como implementar pipelines de datos alrededor del Data Warehouse.
A continuación, el vídeo-resumen. ¡No te lo pierdas!

Arquitecto de Datos con más de 10 años de experiencia en el sector del Big Data. Autor de cursos de formación en tecnologías Big Data, Cloud y Streaming completados por más de 7000 alumnos en Udemy y otras plataformas. Miembro de la Apache Software Foundation desde 2019.


