En este artículo revisamos cómo optimizar los clusters en Databricks, integrando mejores prácticas con experiencia personal y ejemplos de código para ofrecer consejos efectivos.

Contenidos
Importancia de la Optimización de Clústeres en Databricks

Optimizar nuestros clusters en Databricks es importante para maximizar el rendimiento y eficiencia de las cargas de trabajo que ejecutamos. Sin una adecuada configuración y ajuste, Databricks puede enfrentarse a problemas de rendimiento importantes y costosos.
Un clúster bien optimizado no solo mejora la velocidad de procesamiento, sino que también reduce el coste operativo al hacer un uso más eficiente de los recursos. Esto es particularmente relevante en entornos de nube donde pagas por el uso de recursos. La capacidad de manejar cargas de trabajo de manera eficaz puede ser la diferencia entre un proyecto exitoso y uno que se desborda en presupuesto y tiempo.
Comprobaciones Iniciales para Detectar Problemas de Rendimiento
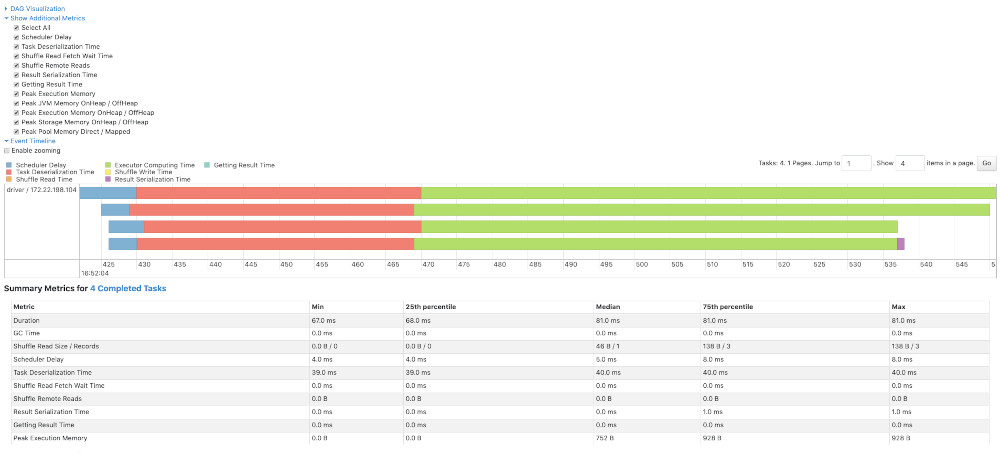
Lo primero que debes hacer cuando detectas problemas de rendimiento en Databricks o Apache Spark en general es verificar si tu carga se está distribuyendo adecuadamente entre los ejecutores. Spark es más efectivo cuando la carga de trabajo se distribuye entre varios workers. Si esto no ocurre, considera ajustar la configuración de tus clústeres. Es fundamental revisar la configuración inicial antes de hacer cambios más profundos.
Ejemplo de Código:
from pyspark.sql import SparkSession
# Crear sesión de Spark
spark = SparkSession.builder \
.appName("Optimización de Clústeres") \
.config("spark.executor.memory", "4g") \
.config("spark.executor.cores", "4") \
.config("spark.cores.max", "16") \
.getOrCreate()
# Configuración de particionado
df = spark.read.csv("path/to/data.csv")
df = df.repartition(8) # Reparticionar el DataFrame en 8 particionesIncrementar el número de ejecutores y nodos puede mejorar significativamente el rendimiento. Aumentar los ejecutores y asignar más memoria a cada uno es crucial para mejorar la eficiencia. Databricks facilita este ajuste, permitiéndote configurar un entorno de pruebas de manera sencilla. Sin embargo, es importante ser consciente del impacto en el coste, ya que más nodos y mayor memoria y CPU incrementan los gastos tanto en licencias como en infraestructura de nube.
¿Quieres Convertirte en Ingeniero de Datos?
Esto se puede hacer fácilmente en Databricks a través de su interfaz de usuario. Al hacerlo, asegúrate de asignar más memoria a cada ejecutor. Recuerda que aunque esto puede aumentar los costos operativos, el beneficio en términos de rendimiento puede justificar la inversión. Es esencial encontrar un equilibrio entre costo y rendimiento, ajustando según las necesidades específicas de tus cargas de trabajo.
Databricks permite elegir entre una gama de tamaños de workers, con diferentes relaciones entre CPU y memoria. Por norma general, en los nuevos procesos podemos partir de los tamaños estándar, con una relación entre CPUs y memoria equilibrada. Si al analizar los logs y la Spark UI detectamos que la utilización de alguno de estos recursos es muy alta de forma constante, podemos realizar pruebas con otros tipos de máquinas, con mayor memoria por cada unidad de CPU o al revés, en función de lo que hayamos observado.
Análisis del Código y Uso de Logs
Otro aspecto importante de la optimización es analizar el código para identificar líneas que toman más tiempo en ejecutarse. Utilizar los logs de Databricks puede ayudarte a detectar estas áreas problemáticas. Asegúrate de no realizar acciones que involucren mucho data shuffling, ya que en mi experiencia esto puede reducir significativamente el rendimiento.
# Habilitar el registro de logs
spark.sparkContext.setLogLevel("INFO")
# Ejemplo de operación de transformación
df = df.withColumn("new_col", df["existing_col"] * 2)
# Acción que puede causar data shuffling
result = df.groupBy("group_col").count()
# Mostrar logs
for line in spark.sparkContext._gateway.jvm.org.apache.log4j.LogManager.getLogger("org.apache.spark").getAppender("stdout").getLayout().getStrings():
print(line)Manejo del Data Shuffling y Estrategias de Particionado
El data shuffling, o movimiento de datos entre workers para realizar operaciones, puede ser un cuello de botella en el rendimiento. Para manejar esto, revisa tu estrategia de particionado. Es importante no evitar la distribución del cómputo; en su lugar, configura más ejecutores y divide la memoria y CPUs disponibles entre ellos. Con esto, reducimos la necesidad de movimientos excesivos de datos, mejorando la eficiencia.
# Estrategia de particionado
df = df.repartition("partition_col")
# Evitar data shuffling innecesario
df = df.sortWithinPartitions("partition_col")Evitar Cuellos de Botella en el Driver
El driver puede convertirse en un cuello de botella si no se maneja adecuadamente. Asegúrate de que tu código esté optimizado para minimizar las veces que todos los datos deben ser llevados a un solo sitio.

Este problema es fácil de detectar revisando los logs del driver; si detectas que no hay suficiente memoria, es una señal de que el driver está sobrecargado. Cuando esto ocurre, el sistema escribe a disco, lo cual es mucho más lento. Asegurarte de que el driver tenga suficiente memoria y está correctamente configurado es vital para mantener el rendimiento.
# Configuración del driver
spark = SparkSession.builder \
.appName("Optimización de Clústeres") \
.config("spark.driver.memory", "8g") \
.config("spark.driver.cores", "4") \
.getOrCreate()Optimización de Recursos y Costes en Databricks
Optimizar recursos no solo mejora el rendimiento, sino que también ayuda a controlar el coste. Configurar más ejecutores y ajustar el tamaño de los nodos debe hacerse con una visión del impacto financiero. Utilizar las herramientas de monitorización y ajuste de Databricks puede proporcionar una visión detallada de cómo se están utilizando los recursos y dónde se pueden hacer mejoras para reducir el coste sin sacrificar el rendimiento.
Siguientes Pasos, Formación y Cursos de Databricks
Aquí tienes mi propio curso para que aprendas de forma eficiente Databricks, para cualquier nivel:

Curso de Introducción a Databricks
Este curso te preparará para comprender y sacar todo el partido posible al ecosistema de Databricks.
Explorarás conceptos fundamentales como la arquitectura de Databricks, los tipos de clústeres, Delta Lake, Unity Catalog y la integración con Azure Data Lake Storage.
En las secciones prácticas, pondrás manos a la obra utilizando la interfaz gráfica, configurando clústeres, trabajando con notebooks, gestionando costes y securizando accesos
También, tienes este libro disponible en Amazon: Beginning Apache Spark Using Azure Databricks
Preguntas Frecuentes
¿Qué es lo primero que debo hacer cuando mi clúster de Databricks tiene problemas de rendimiento?
Lo primero que debes hacer es verificar si la carga de trabajo se está distribuyendo adecuadamente entre los ejecutores. Spark es más eficiente cuando la carga se reparte entre varios workers o ejecutores. Aumentar el número de ejecutores y nodos, así como asignar más memoria a cada ejecutor, puede mejorar significativamente el rendimiento.
¿Cómo puedo ajustar el número de workers en Databricks?
En Databricks, puedes ajustar el número de workers desde la configuración del clúster. En la interfaz de usuario de Databricks, ve a la configuración del clúster y ajusta los parámetros de Número de Workers y el tipo de máqui Es importante encontrar un equilibrio entre el coste y el rendimiento.
¿Qué es el data shuffling y cómo afecta el rendimiento de mi clúster?
El data shuffling se refiere al movimiento de datos entre los ejecutores para realizar operaciones como joins, aggregations y repartitioning. Este proceso puede ser costoso en términos de tiempo y recursos. Para minimizar su impacto, asegúrate de particionar los datos de manera efectiva y evitar operaciones innecesarias que requieran data shuffling.
¿Qué herramientas ofrece Databricks para monitorizar y optimizar el rendimiento?
Databricks proporciona varias herramientas para monitorizar y optimizar el rendimiento, incluyendo la interfaz de administración de clústeres, los logs de Spark, la Spark UI y las métricas de ejecución de trabajos. Utiliza estas herramientas para identificar y solucionar problemas de rendimiento, ajustar configuraciones de clúster y optimizar el uso de recursos.
¿Cómo puedo manejar el particionado de datos para mejorar el rendimiento?
Asegúrate de particionar los datos de manera que cada partición tenga un tamaño manejable y balanceado. Utiliza repartition y coalesce de manera adecuada para ajustar el número de particiones según las necesidades de tu trabajo. Evita particiones demasiado pequeñas o demasiado grandes, ya que ambas pueden impactar negativamente el rendimiento.

Arquitecto de Datos con más de 10 años de experiencia en el sector del Big Data. Autor de cursos de formación en tecnologías Big Data, Cloud y Streaming completados por más de 7000 alumnos en Udemy y otras plataformas. Miembro de la Apache Software Foundation desde 2019.


