En este artículo de introducción de Google Cloud vas a aprender qué es Dataproc, el servicio gestionado de Spark y Hadoop en Google Cloud. Explica sus ventajas y limitaciones, sus componentes, características e integraciones y cómo usarlo.

Contenidos
¿Qué es Google Cloud Dataproc y para qué se utiliza?
Dataproc nos permite usar tecnologías open source para procesamiento batch, streaming y machine learning como Apache Hadoop y Apache Spark. Es un servicio que automatiza la creación de clusters, facilita su gestión y permite disminuir el coste de infraestructura al usar clusters volátiles que se pueden apagar.
Además del bajo coste de Dataproc, es posible usar «preemptive instances» o instancias spot. Estas son instancias no permanentes con un precio mucho más bajo que pueden ser retiradas del servicio en cualquier momento y en un plazo de 24 horas. Dataproc factura solamente por los recursos que utilices, en intervalos de segundos. Los clusters de Dataproc son redimensionables. Se pueden realizar operaciones de creación y escalado en menos de 90 segundos
Al usar el ecosistema open source Hadoop, Dataproc se actualiza frecuentemente con las últimas versiones de las tecnologías Spark, Hadoop, Pig y Hive. También ofrece versionado de imágenes para cambiar entre versiones de las herramientas. Las organizaciones que desplieguen Dataproc podrán usar su código original para migrar fácilmente sus proyectos a la nube de Google.
GCP cuenta con servicios como Cloud Storage, BigQuery o Bigtable que se integran perfectamente con Dataproc como fuentes y destinos de datos. Además de estas tecnologías se integra con los servicios Cloud Logging y Cloud Monitoring para visualizar los logs y monitorizar todas las métricas del cluster. Es posible también añadir otras librerías o herramientas que sean necesarias mediante las acciones de inicialización, ejecutadas en el momento de creación del cluster.
¿Quieres Convertirte en Ingeniero de Datos?
Como un cluster tradicional, Dataproc se puede configurar con alta disponibilidad, con varios nodos primarios y múltiples workers.
Los servicios de otros proveedores cloud más parecidos son EMR en AWS y HDInsight en Azure.
Limitaciones de Hadoop y Spark
Los problemas tradicionales con los clusters de Hadoop y Spark vienen dados por las tareas de configuración y mantenimiento y la utilización eficiente de los recursos de los que se dispone.
En estos clusters no existe separación entre los recursos de almacenamiento y los de computación, se encuentran en el mismo hardware. Además, no son elásticos, y son complicados de escalar rápidamente. Esta falta de separación entre el almacenamiento y el cómputo puede llevar a límites de capacidad, frente a los que se debe añadir más servidores.
Para ejecutar Spark, el cluster debe ser ajustado para que los trabajos que se ejecutan hagan un uso eficiente de los recursos.
Ventajas de Dataproc
Una de las ventajas principales de Dataproc es que no necesitamos aprender nuevas herramientas ni APIs, ejecutará nuestros trabajos Spark y Hive como en cualquier otro cluster. Tampoco debemos preocuparnos del hardware físico. Solamente necesitamos especificar la configuración del cluster y el servicio asignará y gestionará los recursos asociados.
El mantenimiento de las versiones de las herramientas open source para que estén actualizadas y trabajen juntas sin problemas es otra de las dificultades de gestionar un cluster que no es necesario en Dataproc.
Con Dataproc también podemos aislar las cargas de trabajo y asignar un cluster configurado específicamente para cada una de ellas. Esta capacidad es muy llamativa frente a mantener un cluster único con muchas dependencias y servicios infrautilizados. Llamamos a estos clusters especializados y efímeros.
Solo se van a ejecutar cuando necesitemos ejecutar un trabajo. Cuando este trabajo termina, el cluster se eliminará de forma automática, dejando disponibles logs y métricas en los servicios de Google. No deberíamos pensar en un cluster de Dataproc como un servicio de larga duración.
Componentes de Dataproc
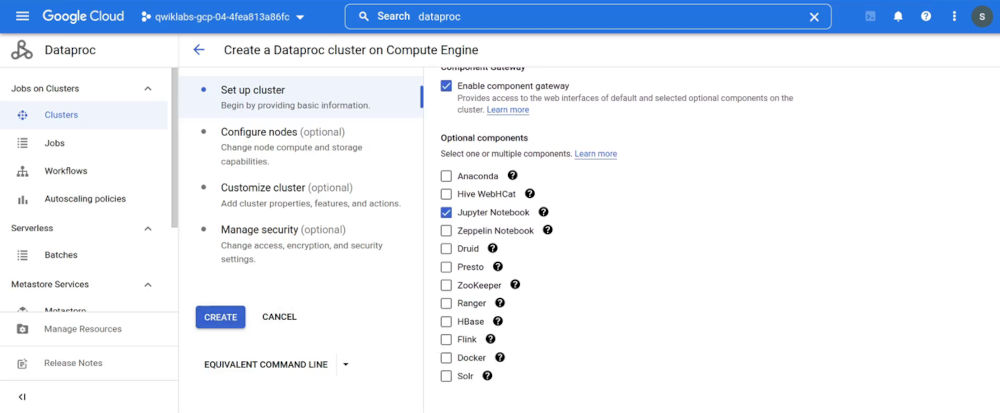
Dataproc puede enriquecerse con componentes opcionales y con las acciones de inicialización. Entre los componentes opcionales que se pueden seleccionar al desplegar un cluster se encuentran Anaconda, Hive WebHCat, Jupyter Notebook, Zeppelin Notebook, Druid, Presto y Zookeeper.
Las acciones de inicialización son personalizaciones sobre el cluster que se ejecutan con scripts en el momento de creación del cluster. De esta manera, podemos especificar un script para inicializar HBase. Observa que en el comando para desplegar un cluster desde la cloud shell indicamos el script de inicialización que se encuentra en un bucket de cloud storage, el número de nodos master y el número de nodos worker:
gcloud dataproc clusters create \
--initialization-actions gs://bucket/hbase.sh \
--num-masters 3 --num-workers 5Podríamos hacer lo mismo con servicios como Flink. Para muchos de estos servicios ya existen scripts implementados que podemos consultar en el repositorio de Github.
Integraciones
Debemos tener en cuenta que el almacenamiento HDFS que existe en los discos de Dataproc desaparece cuando el cluster se apaga. Por este motivo es una buena práctica utilizar almacenamiento fuera de clúster para los resultados de nuestro procesamiento. En lugar de HDFS podemos usar Cloud Storage a través del conector de HDFS.
Para adaptar el código solo tenemos que reemplazar el prefijo de las rutas de almacenamiento de hdfs// a gs//.
Podemos hacer lo mismo con HBase, escribiendo en Bigtable como vemos en la imagen. De igual modo, para cargas analíticas podemos leer los datos con BigQuery.

Originalmente, las velocidades de la red han sido muy lentas, y de ahí la necesidad de mantener los datos cerca del procesador. Con las nuevas redes de petabits que ponen a nuestra disposición los proveedores cloud, podemos separar el almacenamiento y el cómputo de forma eficiente. Las latencias de la red son mínimas.
Almacenamiento en Cloud Storage
La primera optimización que podemos hacer tras trasladar nuestras cargas de trabajo a la nube es utilizar los datos desde donde se almacenan. Cloud Storage es el servicio de almacenamiento de objetos de GCP escalable y duradero. Es la versión en GCP de S3 en AWS o de ADLS en Azure.
El almacenamiento en la nube está optimizado para operaciones paralelas de gran volumen, sin embargo tiene una latencia alta en comparación. HDFS local es una buena opción si:
- Los trabajos ejecutan sobre muchos bloques pequeños de datos
- Debemos iterar sobre muchos directorios anidados
- Tienes cargas de trabajo con muchas escruras particionadas o sensibles a latencias
- Requiere muchas operaciones de metadatos
- Utilizas mucho la operación append en archivos
El uso de Dataproc con Cloud Storage reduce los requisitos de disco y puede ahorrar muchos costes. De esta forma, HDFS puede usar discos más pequeños.
No nos podemos olvidar que Dataproc necesita HDFS para algunas operaciones como el almacenamiento de archivos de gestión, la agregación de registros o las operaciones shuffle.
Cómo usar Dataproc
Podemos crear un cluster de Dataproc desde la cloud shell utilizando el comando gcloud. También podemos crearlo a partir de una configuración de Terraform o a través de la API REST.
Tenemos tres opciones:
- VM única, para pruebas
- Un nodo master (con Namenode, YARN y controladores)
- Alta disponibilidad, con tres master
Podemos establecer las propiedades del clúster, que son valores en tiempo de ejecución que pueden ser utilizados por los archivos de configuración para más opciones de inicio más dinámicas. También debemos establecer el número máximo de workers y el número de discos SSDs que tienen conectados.
Los trabajos pueden enviarse a través de la consola, el comando gcloud y la API REST. Si es necesario podemos configurarlos también con cualquier servicio de orquestación como Cloud Composer (Airflow). No debemos usar las interfaces de Hadoop desde consola para ejecutar trabajos, ya que de esta forma Dataproc no dispone de metadatos necesarios para gestionar los trabajos.
La forma de monitorizar los trabajos es mediante el servicio Cloud Monitoring.
Dataproc autoscaling
El autoescalado de Dataproc proporciona clusters adaptables en función de su carga de trabajo. Se basa en la diferencia entre la memoria pendiente de YARN y la disponible. En el caso de que se necesite más memoria el cluster se ampliará. Si hay un exceso de memoria, el cluster se reducirá.
Por su naturaleza, el autoescalado está pensado para usarse en clusters con datos persistentes fuera del cluster, que no están usando HDFS o HBase como almacenamiento. También es recomendable su uso solamente en clusters con muchos trabajos o con un único trabajo muy pesado.
Esta capacidad no es compatible con Spark Streaming. Tampoco puede escalar a cero workers. Si queremos dejar un cluster inactivo, es mejor destruirlo y crear uno nuevo cuando sea necesario.
Para usar el autoescalado debemos establecer el número de workers iniciales, también los factores de escala, que determinarán cuantos nodos se añadirán o desalojarán en las operaciones de escalado.
Cada vez que se realiza una operación de escalado existe un periodo de enfriamiento, en el que no se realizan operaciones de escalado para permitir a los trabajos que se ajusten a los recursos.
Siguientes Pasos y Formación de GCP
¿Quieres aprender más sobre Google Cloud, Dataproc o BigQuery? Te recomiendo el siguiente curso para tomar ventaja en tu carrera profesional.

Certificación en Google Cloud: ingeniero de la nube
Este curso te aportará las habilidades que necesitas para avanzar en tu carrera de arquitecto cloud y podrás obtener la certificación Google Cloud Associate Cloud Engineer, reconocida por el sector. A través de presentaciones, demos y laboratorios, explorarás y desplegarás elementos de Google Cloud a través de proyectos de Qwiklabs que podrás compartir con posibles empleadores.
También tendrás la oportunidad de practicar habilidades clave, como la configuración e implementación de entornos. Este curso también te proporcionará preguntas de muestra similares a las del examen de certificación, con las soluciones y pruebas de examen de práctica.
Preguntas Frecuentes DataProc – FAQ
¿Qué opciones de escalabilidad ofrece Dataproc?
Dataproc permite escalar el tamaño del cluster de forma manual o automática. La escalabilidad manual se realiza a través de la consola de Google Cloud, donde es posible agregar o quitar nodos del cluster según las necesidades del proyecto. Por otro lado, la escalabilidad automática se realiza mediante el uso de Cloud Dataproc Autoscaling, que ajusta automáticamente el tamaño del cluster en función de la carga de trabajo.
¿Cómo se pueden optimizar las cargas de trabajo en Dataproc?
Para optimizar las cargas de trabajo en Dataproc, es importante seleccionar el tamaño adecuado del clúster y el tipo de máquina virtual. Además, se pueden utilizar prácticas recomendadas de programación de Spark y Hadoop para optimizar el rendimiento de las aplicaciones. Google Cloud también ofrece herramientas de diagnóstico y rendimiento que pueden ayudar a identificar y resolver problemas de rendimiento.
¿Cuál es la diferencia entre un clúster Dataproc y un clúster de Hadoop o Spark convencional?
La principal diferencia es que un clúster Dataproc se ejecuta en la infraestructura de Google Cloud, lo que significa que se puede escalar automáticamente y se integra fácilmente con otras herramientas de Google Cloud. Además, se pueden utilizar herramientas adicionales de Google Cloud, como BigQuery y Cloud Storage.

Arquitecto de Datos con más de 10 años de experiencia en el sector del Big Data. Autor de cursos de formación en tecnologías Big Data, Cloud y Streaming completados por más de 7000 alumnos en Udemy y otras plataformas. Miembro de la Apache Software Foundation desde 2019.


