En este artículo voy a realizar una introducción a la tecnología Apache Ignite, sus características, alguna de sus ventajas y sus casos de uso principales en Big Data.

Contenidos
¿Qué es Apache Ignite?
Apache Ignite es una plataforma en memoria distribuida para procesar grandes volúmenes de datos. La plataforma se centra en proporcionar una alta escalabilidad y un buen rendimiento para realizar procesamiento de datos en memoria. Para conseguir una escalabilidad elevada, Apache Ignite particiona los datos y los distribuye entre los componentes del clúster.
Apache Ignite es una base de datos distribuida centrada en la memoria, es una plataforma de almacenamiento en caché y de procesamiento para cargas de trabajo transaccionales, analíticas y de streaming que ofrece velocidades en memoria a escala de petabytes.
Apache Ignite
La plataforma está compuesta por varios componentes. En la imagen se muestra la arquitectura de alto nivel y su relación con componentes externos:
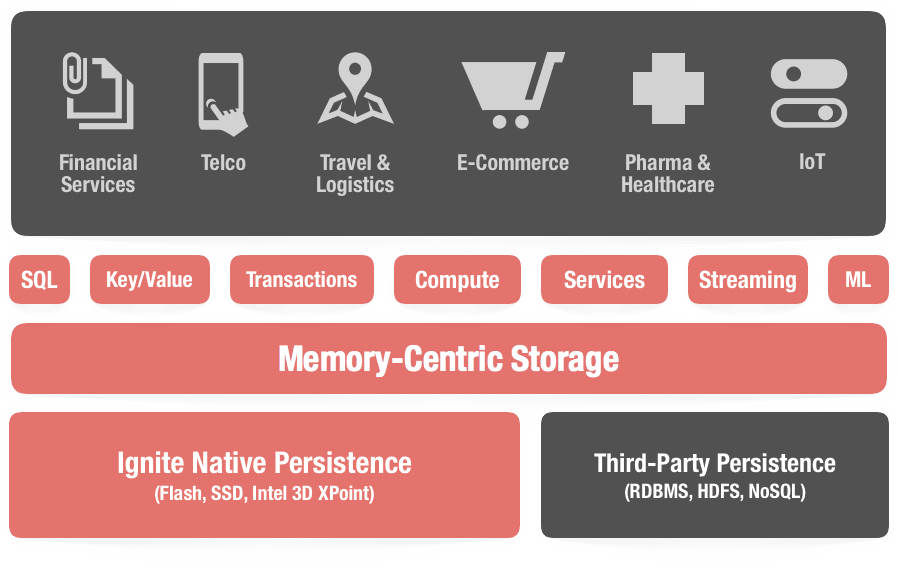
Despliegue de Apache Ignite
En Apache Ignite, los nodos del clúster se autodescubren para trabajar juntos en el entorno en el que se encuentren desplegados. Además, este entorno puede ser una cloud pública como Azure o AWS o bien una cloud híbrida o privada. También existe la opción de desplegar Apache Ignite en contenedores Docker.
Data Grid
Data Grid es un concepto que permite aumentar el rendimiento de las aplicaciones. La idea principal consiste en un Hashmap distribuido, o un almacenamiento de datos del tipo clave-valor distribuido. Concretamente, esta colección de datos se va a encontrar en memoria, lo que reduce drásticamente las latencias de acceso y posibilita su uso como una caché. Un caso de uso típico de Data Grid es ejecutar sobre fuentes de datos tradicionales, por ejemplo bases de datos relacionales, y servir como un mecanismo para acelerar sus consultas.
Generalmente, los Data Grids también tienen capacidad de procesamiento y determinados mecanismos para colocar este procesamiento en el lugar donde se encuentran los datos. Es una manera de aprovechar el poder compartido de la CPU y memoria RAM de varios nodos. Apache Ignite se desarrolló inicialmente como un Data Grid aunque actualmente es mucho más.
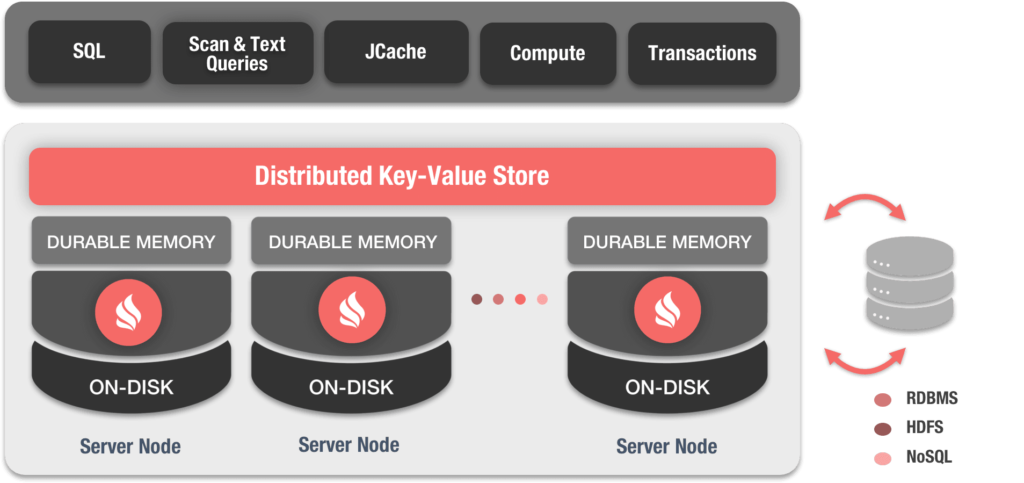
El clúster de Ignite de la figura consiste en N servidores en el que los datos están distribuidos de forma balanceada entre todos estos nodos del clúster.
Los usuarios pueden usar la memoria RAM no solo como una capa de caché, sino como una capa de almacenamiento completa. La persistencia de los datos se puede activar o desactivar y permite conectarse a múltiples sistemas. En el caso de que se desactive, Ignite se comporta como una base de datos distribuida en memoria. Esta persistencia de datos es escalable, soporta transacciones y SQL de forma transparente para las aplicaciones.
Ignite como Base de Datos
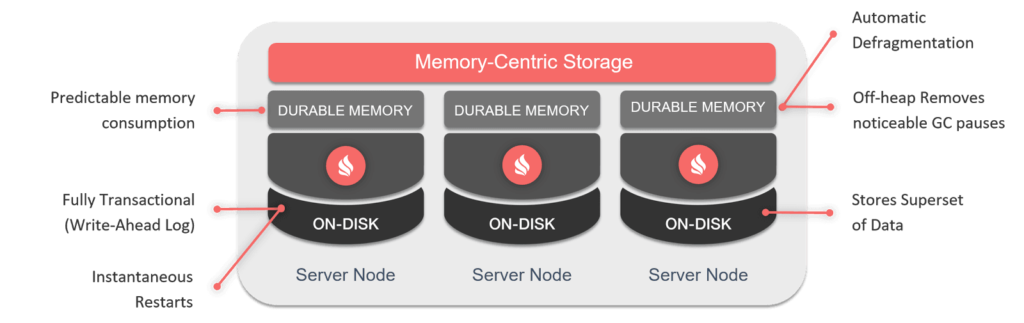
Cuando se activa la persistencia, Ignite se convierte en una base de datos escalable que garantiza la consistencia de los datos y no es necesario tener el dataset completo con los datos e índices en memoria, reduciendo así los tiempos de precarga en el reinicio del sistema.
Ignite hace uso de la memoria off-heap para almacenar los datos. Esta región de la memoria se encuentra fuera del heap de Java, lo que evita pausas en el clúster debido al Garbage Collector.
Según el teorema CAP, Apache Ignite puede configurarse para ser un sistema AP, garantizando la disponibilidad y tolerancia a particiones sacrificando la consistencia. Sin embargo, su diseño se inclina más hacia un sistema CP, que sacrifica la disponibilidad para garantizar la consistencia de los datos con mecanismos como commits de varias fases y control de concurrencia.
¿Quieres Convertirte en Ingeniero de Datos?
Asumiendo que Apache Ignite es un sistema CP y que no podemos garantizar disponibilidad total frente a problemas en la red, si podemos tomar algunas acciones para maximizarla.
Entre estas opciones se encuentran la configuración de las copias de backup que realiza el sistema, el ajuste de las zonas de disponibilidad en el caso de que aplique a nuestro despliegue, la replicación de datos a otro clúster separado y mediante la persistencia de datos en sistemas externos.
Caché de datos
Como ya hemos comentado, Apache Ignite se puede usar como una caché de datos para una o varias fuentes de datos más lentas, como por ejemplo bases de datos relacionales, NoSQL o HDFS.
Al actualizar los datos en la caché de Ignite, estos cambios se propagan al almacenamiento original. En el caso de las operaciones de lectura, si el dato no se encuentra en la caché, la operación de lectura se realizará contra la fuente de datos.
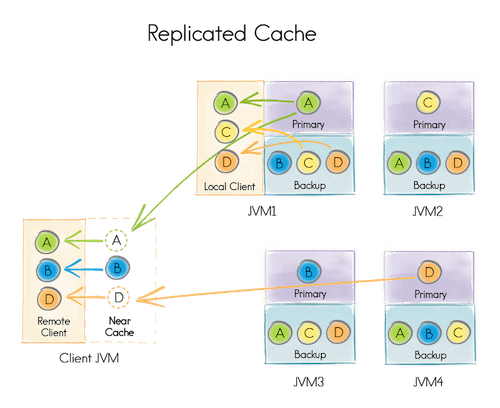
Replicación de datos
Una de las características más importantes es la redundancia de los datos, en la que los datos se replican con una o más copias en memoria. El número de réplicas se puede configurar en función de los requisitos del sistema.
La replicación de los datos en varios nodos del clúster permite garantizar la alta disponibilidad del sistema, y que si un nodo deja de estar disponible, las operaciones son servidas por otro nodo que se encontraba manteniendo la copia de los datos.
Hay dos conceptos en torno a la estrategia de distribución de los datos en el clúster:
Caché particionada
En este caso, los datos son distribuidos en función de su clave entre los nodos del cluster. Cada una de las claves dispone de una copia en otro nodo a modo de backup.
En este escenario, cada nodo contiene una porción del dataset completo. La ventaja es que en el caso de realizar una operación de escritura sobre un dato, solamente el servidor primario y el de backup con la copia deben ser actualizados.

Caché replicada
Por otro lado, en el escenario de la caché replicada, cada nodo contiene todo el dataset, actuando de copia primaria para una de las claves de datos y como backup para el resto. Por lo tanto, cada servidor debe tener memoria suficiente para contener todos los datos.
La principal ventaja en este caso es que un cliente local (ejecutando en uno de los nodos del clúster) reduce significativamente sus latencias, ya que va a contener una copia del dato al que intenta acceder en su propio servidor.
Transacciones en Apache Ignite
Apache Ignite también soporta transacciones ACID (Operaciones con las propiedades de Atomicidad, Consistencia, Aislamiento y Durabilidad), tanto en disco como en memoria.
Existen dos modos de operación transaccionales y el modo atómico. Las operaciones atómicas permiten realizar múltiples operaciones de forma atómica, una cada vez. Para agrupar múltiples operaciones en una transacción se pueden usar los modos transaccionales, que garantizan que todas las operaciones fallarán o se ejecutarán correctamente, sin llevar nunca a un resultado parcial.
Para completar este artículo, quizás quieras echar un ojo a la guía sobre cómo crear una caché con Apache Ignite para Spark.
Formación para Aprender más de Apache Ignite
A continuación, tienes dos libros recomendados para aprender Apache Ignite a fondo e implementar esta potente tecnología en tus proyectos:
- El libro de Apache Ignite
- Guía de inicio rápido de Apache Ignite: procesamiento y almacenamiento en caché de datos distribuidos de forma sencilla
Preguntas Frecuentes – FAQ
¿Para qué se usa Apache Ignite?
Apache Ignite es plataforma de datos en memoria. Se puede usar como un sistema de caché o como una base de datos distribuida en memoria. Esto permite tener un rendimiento superior a las soluciones basadas en disco.
¿Qué es una caché en Apache Ignite?
Ignite se puede usar como una caché de datos para fuentes de datos más lentas, como por ejemplo bases de datos relacionales o HDFS. Al hacer un cambio en la caché de Ignite, el cambio se propaga a la fuente original, pero de esta forma se obtienen tiempos de respuesta más rápidos.
¿En qué se diferencia Ignite de Redis?
Apache Ignite es una plataforma completa de procesamiento en memoria con múltiples casos de uso. Redis, se suele usar como caché de datos clave-valor en memoria. Al ser una solución más completa, en casos de uso más avanzados, en los que se requiere mayor consistencia o procesamiento en tiempo real, Apache Ignite es una solución superior a Redis.
A continuación el vídeo-resumen. ¡No te lo pierdas!

Arquitecto de Datos con más de 10 años de experiencia en el sector del Big Data. Autor de cursos de formación en tecnologías Big Data, Cloud y Streaming completados por más de 7000 alumnos en Udemy y otras plataformas. Miembro de la Apache Software Foundation desde 2019.



Cuales son los datos de latencia para lectura/escritura del software Apache INGNITE? Son del orden de Nanosegundos, microsegunsos, etc? Existe algún dato oficial?
Hola Javi, son del orden de milisegundos. Depende mucho del hardware y caso de uso, pero existen algunos benchmarks interesantes por la web de Apache Ignite.