¿Sabías que la mayoría de las organizaciones desperdician horas tratando de gestionar accesos, permisos y metadatos en sus entornos de datos? Este problema no solo afecta la eficiencia, sino que también puede comprometer la seguridad y el cumplimiento normativo. Descubre cómo Unity Catalog puede centralizar y simplificar todo el proceso, ayudándote a transformar el caos en orden con unos pocos pasos bien estructurados.

Contenidos
La importancia del Gobierno de Datos
Garantizar la gestión adecuada de los datos es esencial para cualquier organización. El gobierno de datos no solo se encarga de su disponibilidad y usabilidad, sino también de asegurar que su integridad y seguridad estén garantizadas. Un desafío constante para muchas empresas es cómo centralizar y simplificar este proceso en un entorno que suele ser fragmentado, especialmente cuando se trabaja con múltiples plataformas y equipos.
Unity Catalog, una solución revolucionaria de Databricks, aborda estos desafíos al proporcionar un enfoque centralizado para el gobierno de datos. Esto permite un control robusto del acceso a los datos y una visibilidad total de cómo se utilizan, lo cual es crítico para cumplir con normativas y garantizar la confianza en las decisiones basadas en datos.
¿Qué es Unity Catalog?
Unity Catalog es un sistema de gobernanza de datos desarrollado por Databricks. Su objetivo principal es proporcionar una solución centralizada para gestionar el acceso, el linaje y los metadatos de los datos en un entorno de data lakehouse. Antes de su llegada, las organizaciones enfrentaban complicaciones al gestionar accesos y metadatos de manera aislada en cada workspace, lo que generaba discrepancias y una administración compleja.
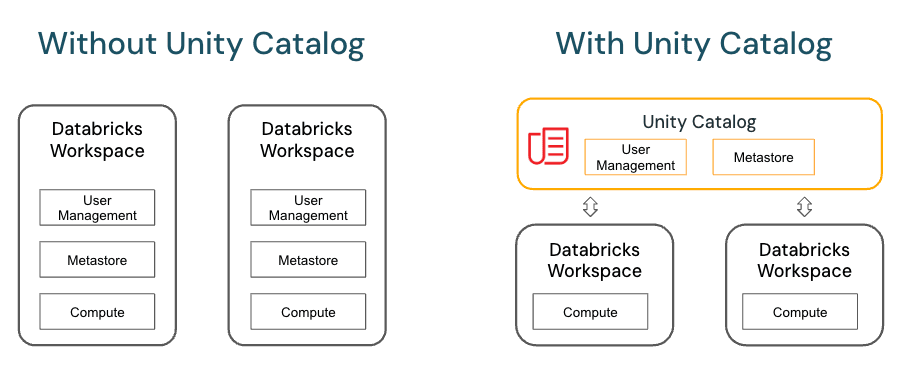
Gracias a Unity Catalog, las organizaciones ahora pueden consolidar estos aspectos, garantizando una experiencia unificada en todos los workspaces de Databricks. Esto incluye la capacidad de definir permisos a nivel de objeto, auditar accesos y rastrear el linaje de datos, desde su origen hasta su transformación final.
Antes de Unity Catalog, cada Workspace de Databricks tenía su propia gestión de usuarios y metastore local. Unity Catalog cambia esto por completo, aportando un metastore y una gestión de usuarios centralizada, a la que se pueden unir los workspaces.
Databricks también ha liberado el software de Unity Catalog como Open Source, que tienes disponible en su repositorio de Github.
Características Principales de Unity Catalog
1. Control de acceso centralizado
Unity Catalog permite definir permisos detallados para cada objeto, como tablas, vistas y funciones. De esta forma se segura que cada usuario o grupo acceda únicamente a los datos que necesita para su trabajo, garantizando la seguridad y evitando errores humanos.
Controlar no solo el acceso a los datos, sino también a clusters, notebooks y dashboards, es esencial para mantener un entorno seguro y eficiente. Unity Catalog lo hace posible desde una única ubicación centralizada.
2. Auditoría y linaje de datos
Uno de los aspectos más destacables es la capacidad de registrar cada acceso y operación realizada sobre los datos. Esto no solo ayuda a cumplir normativas, sino que también permite identificar quién accedió a un recurso y cuándo lo hizo.
¿Quieres Convertirte en Ingeniero de Datos?
La auditoría y el linaje son particularmente valiosos en proyectos de machine learning. Cuando trabajamos con datos para entrenar modelos, saber exactamente cómo se generaron y transformaron los datos es clave para garantizar la transparencia y reproducibilidad.
3. Descubrimiento de datos y metadatos
Unity Catalog actúa como un repositorio donde los usuarios pueden explorar y descubrir los datos que necesitan. Todo esto, mientras se respetan los controles de acceso y los permisos previamente establecidos.
Integración de Unity Catalog
Unity Catalog se integra perfectamente con Databricks, simplificando la administración en entornos de múltiples workspaces.
- Configuración inicial: Para comenzar, es necesario configurar un metastore. Este actúa como el contenedor principal donde se registran los catálogos, esquemas y tablas.
- Asociación de workspaces: Con Unity Catalog, es posible asociar varios workspaces a un mismo metastore, eliminando la necesidad de administrarlos de forma independiente. Unity Catalog requiere un runtime 11.3 o superior para garantizar su funcionamiento óptimo en los clusters de Databricks.
- Compatibilidad con Azure Active Directory: Esto permite sincronizar usuarios y grupos, garantizando que los permisos se administren de manera consistente en toda la organización.
Modelo de Objetos en Unity Catalog
Unity Catalog introduce una jerarquía clara y sencilla para la gestión de datos:
- Metastore: El contenedor principal que agrupa todos los objetos.
- Catálogos: Subconjuntos dentro del metastore, como por ejemplo, un catálogo por departamento.
- Esquemas: Representan las bases de datos que organizan tablas, vistas y funciones.
- Tablas y vistas: Los objetos finales donde se almacenan y acceden los datos.
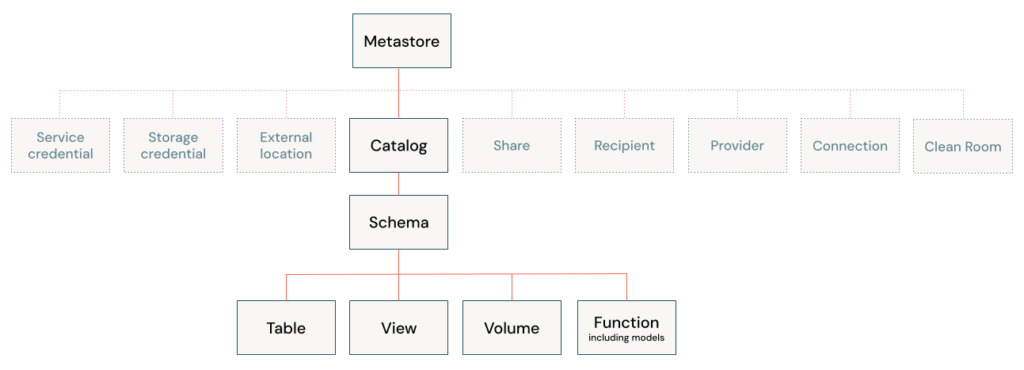
Esta estructura permite un manejo mucho más ordenado y elimina las discrepancias que antes existían entre los workspaces. Ahora, un solo select puede dirigirse fácilmente a un catálogo y esquema específico. Es importante diseñar una estructura clara de catálogos y esquemas desde el principio.
Tablas externas y manejadas en Unity Catalog
En Unity Catalog, existen dos tipos de tablas: «managed» (administradas o manejadas) y «external» (externas) con algunas diferencias.
Tablas Managed (Administradas)
En este tipo de tablas Databricks gestiona completamente los datos y metadatos. Los archivos físicos de los datos se almacenan dentro del metastore de Unity Catalog, en la ubicación de almacenamiento especificada al crear el catalog.
Cuando creas una tabla managed, los archivos de datos se almacenan en la ubicación predeterminada del Metastore. Esta ubicación está definida en la Storage Account asociada al metastore, que puede estar en tu cuenta de Azure si la configuraste así.
Por tanto, no puedes especificar una ubicación diferente por tabla como lo harías con tablas external, pero sí puedes cambiar la ubicación predeterminada del metastore.
Si borras este tipo de tablas con DROP TABLE, los archivos subyacentes también se eliminan.
Creación de una managed table:
CREATE TABLE my_catalog.my_schema.my_table (
id INT,
name STRING
);En Unity Catalog todas las tablas managed son Delta Lake por defecto. Si intentas crear una tabla managed con otro formato (Parquet, CSV, etc.), Databricks automáticamente la guardará como Delta Lake. Si quieres que la tabla use otro formato, debes crearla como tabla external, especificando la ubicación y el formato manualmente.
Tablas External (Externas)
En este caso, los datos se almacenan fuera de Unity Catalog, en una ubicación específica dentro de un bucket S3, Azure Data Lake o Google Cloud Storage. Databricks solo gestiona los metadatos, pero los archivos físicos siguen existiendo incluso si se borra la tabla con DROP TABLE.
Creación de una tabla externa:
CREATE EXTERNAL TABLE my_catalog.my_schema.my_table (
id INT,
name STRING
)
LOCATION 's3://my-bucket/data/';Resumen de Diferencias
| Tipo de tabla | Ubicación de datos | Formato Soportado | Almacenamiento | ¿Cuándo usarla? |
|---|---|---|---|---|
| Managed | En la Storage Account configurada en el Metastore. | Solo Delta Lake | En la ubicación del Metastore | Cuando quieres que Databricks maneje completamente el almacenamiento de los datos. Ideal para datos transitorios o que solo se usan dentro de Databricks. |
| External | En cualquier Storage Account que el cliente especifique manualmente. | Cualquier formato (Parquet, JSON, etc.) | Ubicación definida por el usuario | Cuando los datos ya están en un data lake externo (S3, ADLS, GCS) y necesitas mantener el control sobre ellos sin duplicarlos en Unity Catalog. |
Siguientes Pasos, Formación y Cursos de Databricks
Aquí tienes mi propio curso para que aprendas de forma eficiente Databricks, para cualquier nivel:

Curso de Introducción a Databricks
Este curso te preparará para comprender y sacar todo el partido posible al ecosistema de Databricks.
Explorarás conceptos fundamentales como la arquitectura de Databricks, los tipos de clústeres, Delta Lake, Unity Catalog y la integración con Azure Data Lake Storage.
En las secciones prácticas, pondrás manos a la obra utilizando la interfaz gráfica, configurando clústeres, trabajando con notebooks, gestionando costes y securizando accesos
También, tienes este libro disponible en Amazon: Beginning Apache Spark Using Azure Databricks
Preguntas Frecuentes
¿Unity Catalog reemplaza al Hive Metastore?
Sí, Unity Catalog reemplaza al Hive Metastore en Databricks, ofreciendo una solución centralizada para la administración de metadatos. Aunque el Hive Metastore sigue disponible por compatibilidad, se recomienda usar Unity Catalog para nuevas implementaciones.
¿Es compatible Unity Catalog con Azure Active Directory?
Sí, Unity Catalog se integra con Azure Active Directory, permitiendo sincronizar usuarios y grupos para una administración unificada de permisos y roles en Databricks.
¿Cómo se controla el acceso a los datos en Unity Catalog?
Unity Catalog utiliza un modelo de control basado en permisos definidos para objetos específicos como tablas, vistas o catálogos. Los permisos se pueden asignar a usuarios y grupos mediante políticas centralizadas.
¿Qué es el linaje de datos en Unity Catalog y por qué es importante?
El linaje de datos muestra el recorrido completo de un dato desde su origen hasta su uso final. Esto incluye transformaciones, consultas y outputs. Es esencial para garantizar transparencia, cumplir regulaciones y entender cómo se generan los insights.
¿Se puede usar Unity Catalog con múltiples workspaces?
Sí, Unity Catalog permite asociar un metastore único con varios workspaces, unificando la gobernanza de datos en una sola plataforma.

Arquitecto de Datos con más de 10 años de experiencia en el sector del Big Data. Autor de cursos de formación en tecnologías Big Data, Cloud y Streaming completados por más de 7000 alumnos en Udemy y otras plataformas. Miembro de la Apache Software Foundation desde 2019.


