Databricks Workflows se han convertido en una de las piezas clave para orquestar procesos de datos dentro del ecosistema Databricks. Si trabajas con pipelines de ingesta, de transformaciones o de machine learning, necesitarás coordinar ejecuciones, definir dependencias y controlar fallos. Aquí es donde los Workflows te vendrán bien.

En mi experiencia, poder orquestar procesos directamente desde la interfaz de Databricks sin depender siempre de herramientas externas simplifica mucho la arquitectura y reduce la fricción operativa, sobre todo en proyectos donde todo vive ya en el lakehouse.
Contenidos
Qué son Databricks Workflows
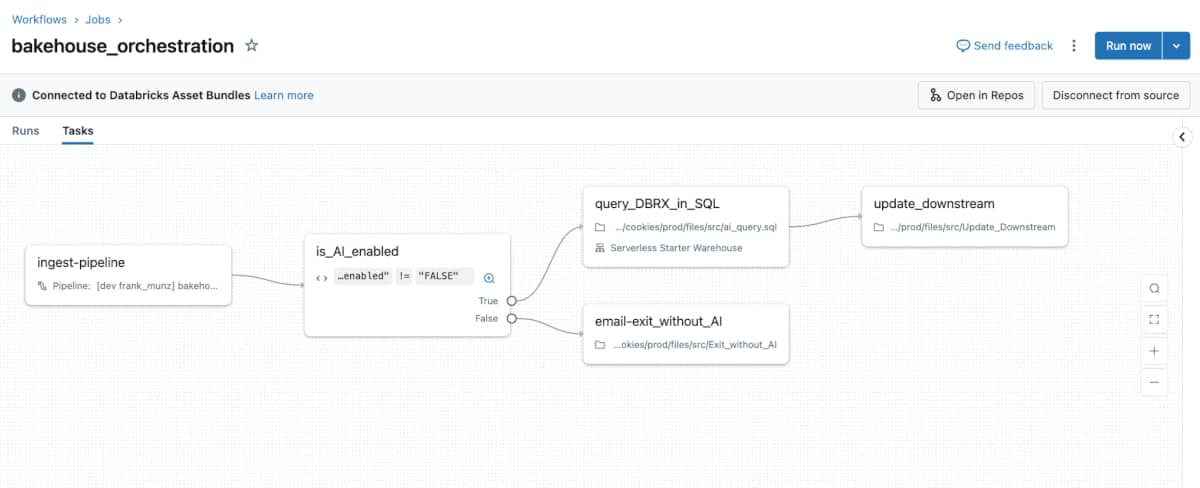
Databricks Workflows es el servicio de orquestación nativo de Databricks que permite definir, programar y monitorizar jobs compuestos por múltiples tareas. Estas tareas pueden ser notebooks, scripts, JARs, pipelines de Delta Live Tables o incluso llamadas a la API.
A nivel conceptual, un workflow es un DAG (Directed Acyclic Graph) donde:
- Cada nodo es una tarea
- Las aristas representan dependencias
- La ejecución puede ser manual, programada o disparada vía API
Lo interesante es que todo esto se gestiona desde la propia plataforma, con una curva de aprendizaje bastante suave.
Componentes principales de un Workflow
Jobs y Tasks
El job es el contenedor principal. Dentro definimos una o varias tasks que se ejecutan de forma secuencial o paralela. Cada task puede usar su propio cluster, lo cual da bastante flexibilidad para optimizar costes y recursos.
En la práctica, esto permite separar claramente, por ejemplo, una ingesta pesada de una transformación ligera sin mezclar necesidades de cómputo.
Dependencias entre procesos
Uno de los puntos fuertes es la definición visual y declarativa de dependencias. Puedes indicar fácilmente que una tarea solo se ejecute si otra ha finalizado correctamente.
Esto evita mucho código pegamento y hace que el pipeline sea más legible y mantenible. En proyectos reales, esta claridad se nota mucho cuando el número de procesos crece.
Programación y disparadores
Los workflows pueden ejecutarse:
- En horarios definidos (cron)
- Bajo demanda
- Mediante llamadas a la API
He usado bastante la API para integrarlos con otros sistemas y es una forma muy cómoda de lanzar procesos sin exponer lógica fuera de Databricks.
Reintentos y control de errores
Cada task permite definir:
- Número de reintentos
- Timeout
- Comportamiento ante fallos
Esto es especialmente útil en procesos de datos donde los errores transitorios son habituales. En mi caso, configurar bien los reintentos ha evitado más de un falso positivo de fallo en producción.
Cómo se crean Databricks Workflows
Desde la interfaz de Databricks
La UI es probablemente la forma más rápida de empezar:
- Creas un job
- Añades tareas
- Defines dependencias
- Configuras el schedule
Todo es bastante intuitivo y visual, ideal para equipos que quieren avanzar rápido.
Usando la API de Databricks
Para escenarios más avanzados, la API permite definir workflows como código. Esto encaja muy bien con enfoques de infraestructura como código y CI/CD. Puedes combinar UI para prototipado y API para producción.
Casos de uso habituales
- Orquestación de pipelines de datos: Es el caso más común: ingesta, limpieza, transformación y carga. Con Workflows puedes definir todo el flujo sin salir de Databricks.
- Procesos de machine learning: Entrenamiento, validación y despliegue de modelos se benefician mucho de la gestión de dependencias y reintentos.
- Automatización sin orquestador externo: En proyectos medianos, Databricks Workflows pueden ahorrarte la necesidad de herramientas como Airflow o Azure Data Factory. Cuando todo el stack vive en Databricks, esta simplicidad es una gran ventaja.
¿Quieres Convertirte en Ingeniero de Datos?
Databricks Workflows vs orquestadores externos
Cuándo usar Workflows
- Todo el procesamiento está en Databricks
- Pipelines de complejidad media
- Equipos que priorizan simplicidad y rapidez
Cuándo no son suficientes
- Orquestación entre muchos sistemas heterogéneos
- Lógicas muy complejas fuera del ecosistema Databricks
En estos casos, un orquestador externo sigue teniendo sentido, pero no siempre es necesario empezar por ahí.
Buenas prácticas
- Separar tareas por responsabilidad
- Ajustar clusters por tipo de task
- Definir reintentos razonables
- Versionar workflows críticos vía API
Estas prácticas marcan la diferencia cuando el número de jobs crece y el entorno se vuelve más exigente.
Databricks Workflows ofrecen una forma potente y sencilla de orquestar procesos de datos sin salir del entorno Databricks. No sustituyen a todos los orquestadores externos, pero en muchos casos eliminan una capa de complejidad innecesaria.
Si ya trabajas en Databricks, mi recomendación es clara: empieza con Workflows, entiende sus límites y solo añade más piezas cuando realmente lo necesites.
Siguientes Pasos, Formación y Curso
Aquí tienes mi propio curso para que aprendas de forma eficiente Databricks, para cualquier nivel:

Curso de Introducción a Databricks
Este curso te preparará para comprender y sacar todo el partido posible al ecosistema de Databricks.
Explorarás conceptos fundamentales como la arquitectura de Databricks, los tipos de clústeres, Delta Lake, Unity Catalog y la integración con Azure Data Lake Storage.
En las secciones prácticas, pondrás manos a la obra utilizando la interfaz gráfica, configurando clústeres, trabajando con notebooks, gestionando costes y securizando accesos
Preguntas Frecuentes – FAQs
¿Databricks Workflows reemplaza a Databricks Jobs?
Workflows es la evolución natural de Jobs, con más flexibilidad y mejor gestión de dependencias.
¿Se pueden versionar los workflows?
Sí, usando la API y definiéndolos como código.
¿Son adecuados para producción?
Sí, siempre que se configuren correctamente reintentos, alertas y control de errores.

Arquitecto de Datos con más de 10 años de experiencia en el sector del Big Data. Autor de cursos de formación en tecnologías Big Data, Cloud y Streaming completados por más de 7000 alumnos en Udemy y otras plataformas. Miembro de la Apache Software Foundation desde 2019.
![Lee más sobre el artículo Mejores Libros de Visualización de Datos [Actualizado]](https://aprenderbigdata.com/wp-content/uploads/mejores-libros-visualizacion-datos-300x169.jpg)

![Lee más sobre el artículo Mejores Libros de Python para Programadores [Actualizado]](https://aprenderbigdata.com/wp-content/uploads/Mejores-libros-python-300x169.jpg)