Los Cluster Pools de Databricks son una funcionalidad que debemos entender para mejorar el tiempo de arranque o startup time de nuestros clústeres, especialmente en escenarios de Job Compute (trabajos programados o por lotes).

En este artículo repasaremos qué son los cluster pools y cómo usarlos para mejorar nuestros clusters.
Contenidos
¿Qué es un Cluster Pool en Databricks?
Un pool en Databricks es un conjunto preinicializado de instancias de cómputo (VMs) que están listas para ser usadas cuando se lanza un clúster.
En lugar de aprovisionar y arrancar instancias cada vez que se lanza un Job Cluster, el pool ya tiene instancias calientes (warm) esperando a ser usadas.
Con este mecanismo, podemos reducir el tiempo de arrancado, que normalmente puede tardar varios minutos cada vez que un cluster se inicializa.
En un cluster pool de Databricks no tienes que indicar un runtime específico, ya que el pool no crea clusters por sí mismo, sino que proporciona instancias de máquina virtual (VMs) preinicializadas para acelerar el arranque de clusters.
Los pools permiten que los clústeres arranquen y escalen hasta 4 veces más rápido, lo que acelera tus pipelines y las consultas interactivas.
¿Cómo funciona con Job Compute?
Cuando creas un Job Cluster y lo asocias a un pool el cluster no tiene que esperar a que se creen nuevas instancias. Cuando arranca, toma nodos directamente de este pool si están disponibles.
Si no hay nodos libres en el pool, se pueden crear más (según el límite del pool). Cuando termina el job, los nodos vuelven al pool y se quedan en espera para el siguiente uso (si están configurados como idle).
En Databricks, los cluster pools tienen un mecanismo similar al de los clústeres llamado Idle Instance Autotermination, que permite controlar cuánto tiempo las instancias en espera pueden permanecer encendidas sin ser usadas, antes de ser terminadas automáticamente.
Un artículo académico sobre sistemas de pooling inteligente (Intelligent Pooling) muestra que, con aprovisionamiento proactivo basado en ML, es posible reducir el tiempo de inactividad de clúster en un 43% manteniendo un 99% de tasa de aciertos en el pool, lo cual podría ahorrar “decenas de millones de dólares” en costes de infraestructura.
En qué debes basarte para configurar un Cluster Pool en Databricks
Aquí van las principales consideraciones prácticas:
- Tipo de instancia: Usa instancias optimizadas en tu pool para el tipo de carga de trabajo y alinea la selección con los tipos de nodos que usarías en tus job clusters normalmente.
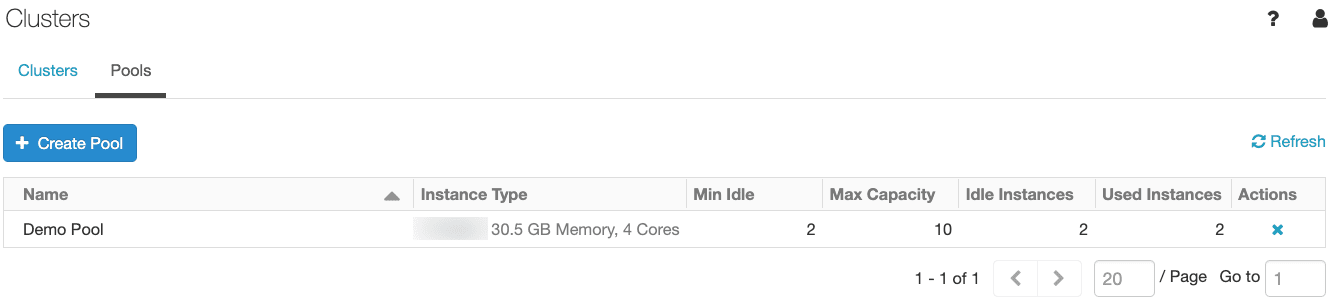
- Tamaño del pool: Debes definir dos propiedades, en función de la concurrencia esperada:
- Min Idle Instances: cuántas instancias quieres que estén siempre calientes. Acelera el tiempo de arranque.
- Max Capacity: el número máximo de nodos que el pool puede usar (esto es tu límite de cómputo asociado). Por ejemplo, si tienes 5 jobs simultáneos y cada uno usa 2 nodos, considera la capacidad máxima del pool 10 nodos.
- Autoscaling del clúster: aunque uses un pool, puedes seguir usando autoscaling en los clusters. El cluster usará los nodos del pool hasta llegar al máximo disponible.
- Coste vs Rendimiento: Tener más idle nodes reduce la latencia de arranque, pero aumenta el coste total (se están cobrando). El uso de pools es ideal para cargas de trabajo con SLAs ajustados o que tienen mucha frecuencia de ejecución. En el caso de cargas de trabajo ocasionales, debes evaluar mantener 0 o pocos nodos en espera.
- Separación por tipo de carga de trabajo: También puedes crear distintos pools para distintos tipos de trabajos, por ejemplo ETLs ligeros, notebooks exploratorios, entornos de desarrollo, producción, etc.
Autoapagado de instancias idle
Cuando configuras un pool en Databricks, se puede definir un período de actividad y autoapagado:
Idle Instance Autotermination:
Es el número de minutos que una instancia puede estar en espera (idle) dentro del pool sin ser utilizada antes de ser apagada automáticamente. Esto ayuda a reducir costes.
| Parámetro | Descripción |
|---|---|
| Min Idle Instances | Número mínimo de instancias que siempre están calientes (listas para usar). |
| Idle Instance Autotermination (minutos) | Tiempo de espera antes de apagar las instancias inactivas. |
Recomendaciones prácticas Databricks Cluster Pools
Para jobs recurrentes y con SLAs, define al menos 1-2 nodos idle para minimizar latencia.
Monitoriza el uso del pool con DBU metrics y ajusta tamaño si hay saturación o sobrecapacidad.
Usa pools distintos para entornos de desarrollo, staging y producción si necesitas aislamiento.
Si tienes cargas frecuentes (jobs cada pocos minutos), pon un valor bajo de Idle Instance Autotermination como 15 o 30 minutos para evitar apagar nodos entre ejecuciones. Si los jobs son esporádicos, usa valores más cortos (5-10 minutos) o directamente deja Min Idle Instances = 0.
Artículo relacionado: Cómo optimizar clusters en Databricks.
Siguientes Pasos y Curso de Databricks
Aquí tienes mi propio curso para que aprendas de forma eficiente Databricks, para cualquier nivel:

Curso de Introducción a Databricks
Este curso te preparará para comprender y sacar todo el partido posible al ecosistema de Databricks.
Explorarás conceptos fundamentales como la arquitectura de Databricks, los tipos de clústeres, Delta Lake, Unity Catalog y la integración con Azure Data Lake Storage.
En las secciones prácticas, pondrás manos a la obra utilizando la interfaz gráfica, configurando clústeres, trabajando con notebooks, gestionando costes y securizando accesos
Preguntas Frecuentes sobre Databricks Cluster Pools
¿Cuál es la diferencia entre un clúster y un Pool en Databricks?
Un clúster es una agrupación de recursos computacionales para ejecutar tareas. Un pool actúa como una reserva de nodos disponibles que pueden asignarse rápidamente a los clústeres cuando se necesitan, reduciendo la latencia de arranque.
¿Por qué debería usar cluster pools en Databricks?
Usar cluster pools ayuda a reducir costes si se usan estratégicamente en entornos con cargas de trabajo variables, reducir el tiempo de arranque de clústeres y Optimizar el uso de instancias preinicializadas.
¿Un pool puede compartirse entre varios clústeres?
Sí, los pools son reutilizables por múltiples clústeres, lo que permite escalar diferentes cargas de trabajo sin duplicar el tiempo de arranque o el coste de recursos.
¿Cómo afecta el uso de pools al coste en Databricks?
El uso de pools puede disminuir el coste total al reducir el tiempo de inactividad entre tareas y aprovechar mejor las instancias. Sin embargo, mantener instancias inactivas por mucho tiempo puede incrementar el gasto si no se configuran correctamente los límites del pool.
¿Se puede usar un pool con Jobs y Workflows en Databricks?
Sí, los Jobs y Workflows pueden utilizar clústeres configurados con un pool, acelerando la ejecución de tareas programadas o automáticas.

Arquitecto de Datos con más de 10 años de experiencia en el sector del Big Data. Autor de cursos de formación en tecnologías Big Data, Cloud y Streaming completados por más de 7000 alumnos en Udemy y otras plataformas. Miembro de la Apache Software Foundation desde 2019.


![Lee más sobre el artículo Mejores Cursos de Bases de Datos en Udemy [Actualizado]](https://aprenderbigdata.com/wp-content/uploads/Mejores-cursos-udemy-bases-de-datos-300x169.jpg)