Aprende en esta entrada qué es Apache Kudu: el sistema de almacenamiento columnar distribuido para datos para analítica muy rápida sobre datos cambiantes.

Contenidos
¿Qué es Apache Kudu?
Apache Kudu es un sistema de almacenamiento columnar y open source para el ecosistema de Apache Hadoop.
El proyecto surgió en Cloudera y la primera versión se publicó en el año 2016. Está desarrollado en el lenguaje de programación C++ y se distribuye actualmente con licencia Apache 2.0.
El motor de consultas de Kudu ofrece lecturas con una latencia de milisegundos sobre datos estructurados. Puede compararse en velocidad de escritura a Apache HBase y a las bases de datos NoSQL orientadas a columnas.
Además, Apache Kudu puede usarse junto a Apache Impala o Apache Spark para acceder a los datos con el lenguaje de consulta SQL. Implementa APIs para los lenguajes Java, C++ y Python y también puede usarse con los conectores JDBC y ODBC.
Modelo de Datos
Apache Kudu está diseñado para cargas de trabajo de tipo OLAP. La diferencia principal con Apache HBase es que Apache Kudu implementa un modelo relacional, mientras que HBase no tiene esquema.
Un clúster de Kudu, por tanto, almacena las tablas de forma parecida a las bases de datos relacionales. Cada tabla contiene una clave primaria formada por una o más columnas. Esta clave primaria es el identificador único que nos permite leer, actualizar o eliminar filas de la tabla de una forma eficiente.
Internamente, Kudu organiza los datos por columnas, lo que supone una ventaja en consultas analíticas y es similar a usar un formato como Apache Parquet sobre HDFS.
¿Quieres Convertirte en Ingeniero de Datos?
Kudu también almacena de forma centralizada todos los metadatos. Para esto usa una tabla especial llamada catalog table. Esta tabla solo es accesible con las operaciones de metadatos expuestas en las APIs, no directamente.
Arquitectura de Apache Kudu
Apache Kudu es una tecnología distribuida que puede escalar horizontalmente. Para distribuir los datos, las tablas se parten en unidades más pequeñas llamadas tablets. Este particionado puede configurarse por cada tabla para hacerlo bien por un rango de claves o por el cálculo de una función hash.
Cada tablet se replica en varios servidores, uno de estos se considera el líder y el resto son réplicas. La replicación en Kudu se basa en las operaciones, no en los datos que residen en el disco, por lo que se trata de una replicación lógica. En este caso las operaciones de borrado no necesitan mover datos en la red y cada servidor con una copia realiza este borrado localmente. Cualquier réplica puede dar respuesta a las lecturas de datos, mientras que las escrituras necesitan de consenso.
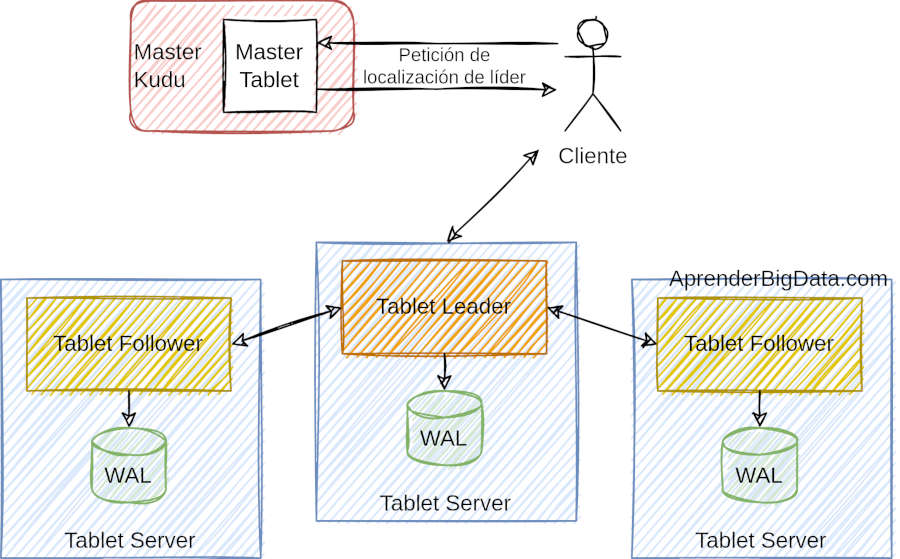
Por otro lado, las compactaciones de datos no se tienen por qué producir a la vez en cada tablet, sino que pueden repartirse en el tiempo para evitar periodos con alta latencia del sistema.
Para elegir el servidor líder, Apache Kudu usa el protocolo de consenso RAFT. El protocolo asegura que cada escritura de datos se persiste en al menos dos nodos antes de responder a la petición de escritura de forma satisfactoria. Este mecanismo asegura la tolerancia a fallos y una alta disponibilidad del sistema.
Kudu también puede compartir los discos de datos con los DataNodes de HDFS.
Casos de Uso
El principal caso de uso de Apache Kudu es la analítica y Business Intelligence en el ecosistema Hadoop. Para ello, es posible realizar consultas sobre los datos a través de claves, rangos de claves o por selección de columnas.
Otro caso de uso muy popular está relacionado con la ingesta de datos en tiempo real. Kudu ofrece la capacidad de insertar y actualizar datos con una latencia muy baja. Puede ser una herramienta muy potente en casos de uso en los que entren datos al sistema rápidamente y deban disponibilizarse para consultas analíticas de forma inmediata.
Cómo usar Apache Kudu
Para instalar Apache Kudu en Linux rápidamente, sigue estos pasos:
- Descarga el archivo binario de Apache Kudu desde https://kudu.apache.org/releases/
- Descomprime el archivo binario en un directorio de tu elección, por ejemplo
/opt/kudu - Crea un enlace simbólico para el archivo
kudu-masterykudu-tserveren el directorio/usr/local/binpara poder ejecutarlos desde cualquier directorio:sudo ln -s /opt/kudu/kudu-master /usr/local/bin/kudu-mastersudo ln -s /opt/kudu/kudu-tserver /usr/local/bin/kudu-tserver
- Inicia los servidores Kudu Master y Tablet Server en modo detrás (background):
kudu-master --log_dir=/var/log/kudu & kudu-tserver --log_dir=/var/log/kudu &
- Utiliza el comando
kudupara interactuar con el cluster Kudu, por ejemplo:kudu cluster list
A continuación se muestra un ejemplo de cómo ejecutar Apache Kudu y realizar una consulta de prueba en Python:
# Importar las libreríasfrom pykudu import connect # Crear una conexión al cluster de Kudu client = connect('mycluster.kudu.domain.com:7051') # Abrir una tabla de Kudu table = client.table('mytable') # Crear un scanner sobre la tabla scanner = table.scanner() # Ejecutar la consultaresults = scanner.open().read_all_tuples() # Mostrar los resultados print(results) # Cerrar el scanner scanner.close()
En este ejemplo se crea una conexión al cluster Kudu. Luego se abre una tabla Kudu y se crea un escáner para ejecutar la consulta. Se utiliza el escáner para ejecutar la consulta y se imprimen los resultados. Por último, se cierra el escáner.
Cursos y Formación Recomendada de Apache Kudu
A continuación, te recomiendo dos libros para complementar tu aprendizaje de Apache Kudu:
- Getting Started with Kudu: Perform Fast Analytics on Fast Data
- Next-Generation Big Data: A Practical Guide to Apache Kudu, Impala, and Spark
Preguntas Frecuentes Apache Kudu – FAQ
¿En qué se diferencia Apache Kudu de HBase?
La diferencia de Kudu coin HBase es que Kudu implementa un modelo relacional y HBase no tiene esquema. Kudu está diseñado para cargas de trabajo de tipo OLAP y almacena las tablas de forma parecida a las bases de datos relacionales, con una clave primaria como identificador único.
¿En qué se diferencia Apache Kudu de Impala?
Estas dos herramientas sirven propósitos diferentes en el ecosistema Hadoop de big data. Apache Impala es un motor de consultas distribuido para Apache Hadoop, mientras que Apache Kudu es el soporte de almacenamiento de datos que completa la capa de almacenamiento que proporciona HDFS.
¿Es Apache Kudu una base de datos?
Kudu es un sistema de almacenamiento similar a una base de datos, con mucha más funcionalidad que un filesystem. Actúa como base de datos relacional particionando las tablas y proporcionando acceso a los datos con latencias muy bajas.
¿Tiene Kudu propiedades ACID?
Apache Kudu aún no tiene propiedades ACID ni transacciones, pero se encuentran en el roadmap del proyecto.
A continuación, el vídeo-resumen. ¡No te lo pierdas!

Arquitecto de Datos con más de 10 años de experiencia en el sector del Big Data. Autor de cursos de formación en tecnologías Big Data, Cloud y Streaming completados por más de 7000 alumnos en Udemy y otras plataformas. Miembro de la Apache Software Foundation desde 2019.


