Apache Iceberg es un formato para almacenar datos masivos en forma de tablas que se está popularizando en el ámbito analítico. Cloudera ya incluye Iceberg en su stack para aprovechar su compatibilidad con sistemas de almacenamiento de objetos. Sigue leyendo si quieres aprender qué aporta este formato de datos, sus ventajas, desventajas y competidores.

Contenidos
¿Qué es Apache Iceberg?
Iceberg es un formato de datos open source que permite almacenar tablas analíticas con grandes cantidades de datos y con un buen rendimiento. Proporciona las ventajas del lenguaje SQL para acceder a estas tablas y hace posible que motores de procesamiento como Spark, Flink, Presto, Athena, EMR o Hive puedan acceder a los mismos conjuntos de datos de manera consistente. Está escrito en Java y se distribuye con la licencia Apache 2.0. Fue desarrollado originalmente Netflix.
Actualmente existen tres problemas principales al realizar consultas SQL sobre datasets grandes. Por un lado, la planificación de las consultas es lenta ya que debe conocer donde se encuentran las particiones de la tabla. Además, el metastore que usan algunos sistemas de almacenamiento supone un cuello de botella para su escalabilidad. Por último, muchos de estos sistemas de almacenamiento no consideran la evolución del esquema y de las particiones en los datos.
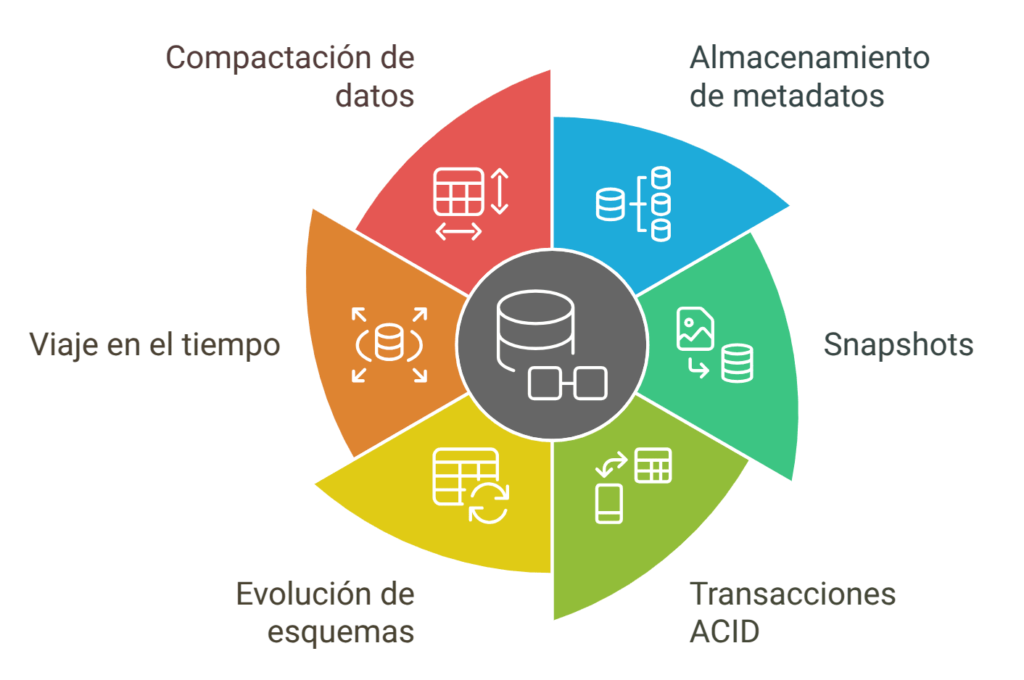
Apache Iceberg incrementa la velocidad y la eficiencia de acceso a estos datasets masivos. También, resuelve el cuello de botella del metastore almacenando los metadatos de partición al nivel de fichero. Además, Iceberg soporta la creación de snapshots, transacciones ACID, time travel, evolución de las particiones y operaciones de compactación de datos.
Time Travel y Rollback
Llamamos time travel a la capacidad de realizar una consulta sobre un snapshot o un timestamp específico, que representa el estado de la tabla en otro momento. La sintaxis de SQL incluye la extensión «AS OF», en la que se especifica el instante temporal sobre el que se quieren recuperar los datos:
SELECT * FROM tabla FOR SYSTEM_TIME AS OF '2022-01-01 10:00:00';
SELECT * FROM tabla FOR SYSTEM_VERSION AS OF 4;
En el caso de Spark, se puede hacer time travel sin la necesidad de SQL, simplemente usando la API:
spark.read
.option("as-of-timestamp", "164107440000") //timestamp
.format("iceberg")
.load("ruta/de/la/tabla")
spark.read
.option("snapshot-id", "4L") //snapshot
.format("iceberg")
.load("ruta/de/la/tabla")
Apache Iceberg en Cloudera
Apache Iceberg está incluido e integrado en la distribución de Cloudera CDP como formato de ficheros en el mismo plano que las tablas de Hive. Las tablas en formato Iceberg se integran con los sistemas de linaje y de gobierno de la plataforma, y son compatibles con las capas de almacenamiento estándar, como HDFS, Apache Ozone, s3 en AWS o ADLS en Azure.
La integración incluye la interoperabilidad de lectura y de escritura consistentes con Hive, Impala y Spark, así como la posibilidad de realizar operaciones de time travel directamente. El uso es a través de comandos SQL compatibles con estos tres sistemas, a través de los que se puede convertir fácilmente a tablas Iceberg.
Para migrar tablas Hive a Iceberg, se puede usar la siguiente sentencia en SQL.
ALTER TABLE tabla1 SET TBLPROPERTIES
('storage_handler'='org.apache.iceberg.mr.hive.HiveIcebergStorageHandler')
También es posible la conversión de tablas Hive a Iceberg desde Spark 3:
spark.sql("CALL <catalog>.system.snapshot('<src>', '<dest>')")
spark.sql("CALL <catalog>.system.migrate('<src>')")
Evolución de Particiones
Generalmente, las soluciones de datos no incluyen la capacidad de evolucionar las particiones. Las tablas deben ser reescritas totalmente si se desea tener una nueva columna de particionado. Para conseguirlo, Apache Iceberg separa las particiones físicas y lógicas, de forma que puede evolucionar los esquemas de particiones cuando el volumen de datos cambia (particiones ocultas).
Los beneficios de esta aproximación es que no se deben reescribir las tablas, con el coste que esto supone, tanto de tiempo como de indisponibilidad de las tablas. Tampoco es necesario reescribir las consultas. La sintaxis es la siguiente:
ALTER TABLE tabla SET PARTITION FIELD (hour(ts))
Cómo funciona Apache Iceberg
Iceberg es una tecnología diseñada para resolver los problemas de consistencia de datos al almacenar tablas Hive en sistemas de objetos como s3. Para funcionar, Hive usa un metastore centralizado en el que almacena la información de particiones, y usa también un sistema de ficheros para almacenar los datos. Esto hace que sea imposible implementar cambios con operaciones atómicas sobre las tablas. Además, sistemas eventualmente consistentes como s3 pueden devolver resultados incorrectos al usar varios ficheros para reconstruir el estado de las tablas.
La manera que usa Iceberg para conocer el listado de ficheros que componen una tabla es mediante una estructura de árbol que se persiste con cada snapshot. Cada escritura o modificación produce un nuevo snapshot de la tabla que se almacena en un fichero. Con este mecanismo, se garantiza que las lecturas siempre usen un snapshot consistente y sin necesidad de bloquear la tabla.
¿Quieres Convertirte en Ingeniero de Datos?
Por otro lado, la creación de snapshots permite que existan varias escrituras en las tablas de forma concurrente. Cada escritor asume que no hay otras escrituras y escribe un nuevo snapshot. Cuando termina, intenta hacer el commit y reemplazar el fichero de metadatos actual con el que acaba de escribir. Si en este momento el commit falla porque hay un nuevo fichero de metadatos correspondiente a otra escritura, reintenta todo el proceso usando este nuevo fichero de metadatos.
Como Apache Iceberg evita las operaciones de listado y de renombrado de ficheros sobre un directorio, no necesita que el sistema de almacenamiento sea consistente, haciéndolo compatible con sistemas de almacenamiento de objetos como s3.
Apache Iceberg vs Parquet y Delta Lake
Apache Iceberg es muy similar a Delta Lake, el formato de ficheros propuesto por Databricks que proporciona transacciones ACID y time travel sobre Apache Parquet.
Iceberg es recomendable si necesitas almacenar grandes tablas con muchas particiones en almacenamientos de objetos como s3, ya que optimiza el rendimiento y evitan los listados de ficheros y la gestión de particiones en el metastore. Además, a diferencia de Delta Lake, Iceberg es compatible con otros formatos de datos además de Parquet como ORC.
Por otro lado, deberías evaluar Delta Lake si estás usando Databricks o el ecosistema de Apache Spark y necesitas capacidades de upsert y de streaming como por ejemplo con Spark Streaming sobre este formato.
Siguientes pasos y Formación Recomendada

Curso de Especialización en Big Data de Cloudera
Esta especialización de Coursera ofrecida directamente por Cloudera te enseñará todos los componentes necesarios para convertirte en experto Big Data, es muy recomendable. Se compone de cuatro módulos de aprendizaje para dominar el análisis de datos:
Preguntas Frecuentes – FAQ
¿Cómo maneja Apache Iceberg la evolución del esquema?
Apache Iceberg maneja la evolución del esquema permitiendo cambios como la adición, eliminación y renombrado de columnas sin afectar las operaciones de lectura y escritura. Esta flexibilidad se logra mediante el uso de metadatos que mantienen un historial de versiones de esquema, lo que permite a los usuarios realizar modificaciones sin interrumpir los procesos existentes ni comprometer la integridad de los datos.
¿Cómo soporta Apache Iceberg las operaciones ACID?
Apache Iceberg soporta operaciones ACID mediante la implementación de un sistema de gestión de transacciones que garantiza la atomicidad, consistencia, aislamiento y durabilidad de las operaciones. Esto se logra a través de metadatos que rastrean los cambios en los datos y aseguran que todas las modificaciones sean aplicadas de manera coherente. Iceberg permite transacciones concurrentes sin comprometer la integridad de los datos, facilitando la creación de aplicaciones que requieren una alta confiabilidad.
¿Qué es un snapshot en Apache Iceberg y para qué se utiliza?
Un snapshot en Apache Iceberg es una captura de la tabla en un estado específico del tiempo. Los snapshots permiten a los usuarios realizar operaciones como consultas históricas, rollback de cambios y análisis de versiones anteriores de los datos. Esto es útil para la auditoría, el cumplimiento normativo y la recuperación ante fallos, ya que proporciona un mecanismo para revertir a estados anteriores de los datos.

Arquitecto de Datos con más de 10 años de experiencia en el sector del Big Data. Autor de cursos de formación en tecnologías Big Data, Cloud y Streaming completados por más de 7000 alumnos en Udemy y otras plataformas. Miembro de la Apache Software Foundation desde 2019.


